Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 139 results for "Greg R Madey" clear search

COMM-PDND: Communication-Based Model of Perceived Descriptive Norm Dynamics in Digital Networks
Lars Reinelt | Published Friday, September 08, 2023The Communication-Based Model of Perceived Descriptive Norm Dynamics in Digital Networks (COMM-PDND) is an agent-based model specifically created to examine the dynamics of perceived descriptive norms in the context of digital network structures. The model, developed as part of a master’s thesis titled “The Dynamics of Perceived Descriptive Norms in Digital Network Publics: An Agent-Based Simulation,” emphasizes the critical role of communication processes in norm formation. It focuses on the role of communicative interactions in shaping perceived descriptive norms.
The COMM-PDND is tuned to explore the effects of normative deviance in digital social networks. It provides functionalities for manipulating agents according to their network position, and has a versatile set of customizable parameters, making it adaptable to a wide range of research contexts.

Cultural Evolution of Sustainable Behaviours: Landscape of Affordances Model
Nikita Strelkovskii Roope Oskari Kaaronen | Published Wednesday, December 04, 2019 | Last modified Wednesday, December 04, 2019This NetLogo model illustrates the cultural evolution of pro-environmental behaviour patterns. It illustrates how collective behaviour patterns evolve from interactions between agents and agents (in a social network) as well as agents and the affordances (action opportunities provided by the environment) within a niche. More specifically, the cultural evolution of behaviour patterns is understood in this model as a product of:
- The landscape of affordances provided by the material environment,
- Individual learning and habituation,
- Social learning and network structure,
- Personal states (such as habits and attitudes), and
…
Peer reviewed MOOvPOPsurveillance
Matthew Gompper Aniruddha Belsare Joshua J Millspaugh | Published Tuesday, April 04, 2017 | Last modified Tuesday, May 12, 2020MOOvPOPsurveillance was developed as a tool for wildlife agencies to guide collection and analysis of disease surveillance data that relies on non-probabilistic methods like harvest-based sampling.
An Opinion Dynamics of Science? Agent-Based Modeling of Knowledge Spread
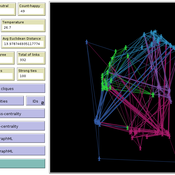
Bernardo Buarque | Published Thursday, April 13, 2023We present a socio-epistemic model of science inspired by the existing literature on opinion dynamics. In this model, we embed the agents (or scientists) into social networks - e.g., we link those who work in the same institutions. And we place them into a regular lattice - each representing a unique mental model. Thus, the global environment describes networks of concepts connected based on their similarity. For instance, we may interpret the neighbor lattices as two equivalent models, except one does not include a causal path between two variables.
Agents interact with one another and move across the epistemic lattices. In other words, we allow the agents to explore or travel across the mental models. However, we constrain their movements based on absorptive capacity and cognitive coherence. Namely, in each round, an agent picks a focal point - e.g., one of their colleagues - and will move towards it. But the agents’ ability to move and speed depends on how far apart they are from the focal point - and if their new position is cognitive/logic consistent.
Therefore, we propose an analytical model that examines the connection between agents’ accumulated knowledge, social learning, and the span of attitudes towards mental models in an artificial society. While we rely on the example from the General Theory of Relativity renaissance, our goal is to observe what determines the creation and diffusion of mental models. We offer quantitative and inductive research, which collects data from an artificial environment to elaborate generalized theories about the evolution of science.
Cellular automata model of social networks
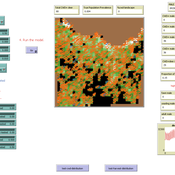
Rubens de Almeida Zimbres | Published Tuesday, August 02, 2022This project was developed during the Santa Fe course Introduction to Agent-Based Modeling 2022. The origin is a Cellular Automata (CA) model to simulate human interactions that happen in the real world, from Rubens and Oliveira (2009). These authors used a market research with real people in two different times: one at time zero and the second at time zero plus 4 months (longitudinal market research). They developed an agent-based model whose initial condition was inherited from the results of the first market research response values and evolve it to simulate human interactions with Agent-Based Modeling that led to the values of the second market research, without explicitly imposing rules. Then, compared results of the model with the second market research. The model reached 73.80% accuracy.
In the same way, this project is an Exploratory ABM project that models individuals in a closed society whose behavior depends upon the result of interaction with two neighbors within a radius of interaction, one on the relative “right” and other one on the relative “left”. According to the states (colors) of neighbors, a given cellular automata rule is applied, according to the value set in Chooser. Five states were used here and are defined as levels of quality perception, where red (states 0 and 1) means unhappy, state 3 is neutral and green (states 3 and 4) means happy.
There is also a message passing algorithm in the social network, to analyze the flow and spread of information among nodes. Both the cellular automaton and the message passing algorithms were developed using the Python extension. The model also uses extensions csv and arduino.
Gender differentiation model
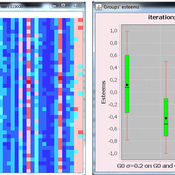
Sylvie Huet | Published Monday, April 20, 2020 | Last modified Thursday, April 23, 2020This is a gender differentiation model in terms of reputations, prestige and self-esteem (presented in the paper https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0236840). The model is based on the influence function of the Leviathan model (Deffuant, Carletti, Huet 2013 and Huet and Deffuant 2017) considering two groups.
This agent-based model studies how inequalities can be explained by the difference of open-mindness between two groups of interacting agents. We consider agents having an opinion/esteem about each other and about themselves. During dyadic meetings, agents change their respective opinion about each other and possibly about other agents they gossip about, with a noisy perception of the opinions of their interlocutor. Highly valued agents are more influential in such encounters. We study an heterogeneous population of two different groups: one more open to influence of others, taking less into account their perceived difference of esteem, called L; a second one less prone to it, called S, who designed the credibility they give to others strongly based on how higher or lower valued than themselves they perceive them.
We show that a mixed population always turns in favor to some agents belonging to the group of less open-minded agents S, and harms the other group: (1) the average group self-opinion or reputation of S is always better than the one of L; (2) the higher rank in terms of reputation are more frequently occupied by the S agents while the L agents occupy more the bottom rank; (3) the properties of the dynamics of differentiation between the two groups are similar to the properties of the glass ceiling effect proposed by Cotter et al (2001).
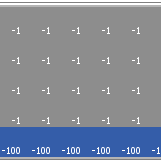
Cliff Walking with Q-Learning NetLogo Extension
Kevin Kons Fernando Santos | Published Tuesday, December 10, 2019This model implements a classic scenario used in Reinforcement Learning problem, the “Cliff Walking Problem”. Consider the gridworld shown below (SUTTON; BARTO, 2018). This is a standard undiscounted, episodic task, with start and goal states, and the usual actions causing movement up, down, right, and left. Reward is -1 on all transitions except those into the region marked “The Cliff.” Stepping into this region incurs a reward of -100 and sends the agent instantly back to the start (SUTTON; BARTO, 2018).
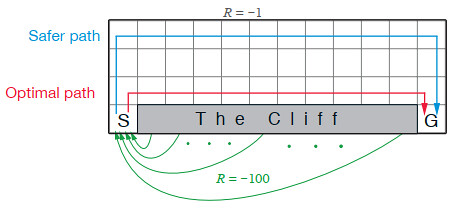
The problem is solved in this model using the Q-Learning algorithm. The algorithm is implemented with the support of the NetLogo Q-Learning Extension

Prisoner's Tournament
Kristin Crouse | Published Wednesday, November 06, 2019 | Last modified Wednesday, December 15, 2021This model replicates the Axelrod prisoner’s dilemma tournaments. The model takes as input a file of strategies and pits them against each other to see who achieves the best payoff in the end. Change the payoff structure to see how it changes the tournament outcome!
FlipFlop1-ProMEERB: A coupled social-ecological model with a promotional mechanism for emergence of environmentally responsible behavior
Liliana Perez Saeed Harati Roberto Molowny-Horas | Published Friday, December 17, 2021At the heart of a study of Social-Ecological Systems, this model is built by coupling together two independently developed models of social and ecological phenomena. The social component of the model is an abstract model of interactions of a governing agent and several user agents, where the governing agent aims to promote a particular behavior among the user agents. The ecological model is a spatial model of spread of the Mountain Pine Beetle in the forests of British Columbia, Canada. The coupled model allowed us to simulate various hypothetical management scenarios in a context of forest insect infestations. The social and ecological components of this model are developed in two different environments. In order to establish the connection between those components, this model is equipped with a ‘FlipFlop’ - a structure of storage directories and communication protocols which allows each of the models to process its inputs, send an output message to the other, and/or wait for an input message from the other, when necessary. To see the publications associated with the social and ecological components of this coupled model please see the References section.
MERCURY extension: population
Tom Brughmans | Published Thursday, May 23, 2019This model is an extended version of the original MERCURY model (https://www.comses.net/codebases/4347/releases/1.1.0/ ) . It allows for experiments to be performed in which empirically informed population sizes of sites are included, that allow for the scaling of the number of tableware traders with the population of settlements, and for hypothesised production centres of four tablewares to be used in experiments.
Experiments performed with this population extension and substantive interpretations derived from them are published in:
Hanson, J.W. & T. Brughmans. In press. Settlement scale and economic networks in the Roman Empire, in T. Brughmans & A.I. Wilson (ed.) Simulating Roman Economies. Theories, Methods and Computational Models. Oxford: Oxford University Press.
…
Displaying 10 of 139 results for "Greg R Madey" clear search