Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 4 of 4 results q-learning clear search
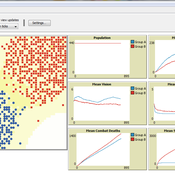
This model was developed to test the usability of evolutionary computing and reinforcement learning by extending a well known agent-based model. Sugarscape (Epstein & Axtell, 1996) has been used to demonstrate migration, trade, wealth inequality, disease processes, sex, culture, and conflict. It is on conflict that this model is focused to demonstrate how machine learning methodologies could be applied.
The code is based on the Sugarscape 2 Constant Growback model, availble in the NetLogo models library. New code was added into the existing model while removing code that was not needed and modifying existing code to support the changes. Support for the original movement rule was retained while evolutionary computing, Q-Learning, and SARSA Learning were added.
Cliff Walking with Q-Learning NetLogo Extension
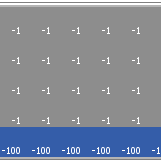
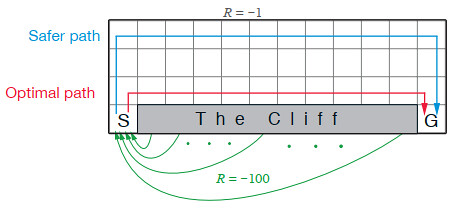
Kevin Kons Fernando Santos | Published Tuesday, December 10, 2019This model implements a classic scenario used in Reinforcement Learning problem, the “Cliff Walking Problem”. Consider the gridworld shown below (SUTTON; BARTO, 2018). This is a standard undiscounted, episodic task, with start and goal states, and the usual actions causing movement up, down, right, and left. Reward is -1 on all transitions except those into the region marked “The Cliff.” Stepping into this region incurs a reward of -100 and sends the agent instantly back to the start (SUTTON; BARTO, 2018).
The problem is solved in this model using the Q-Learning algorithm. The algorithm is implemented with the support of the NetLogo Q-Learning Extension

Maze with Q-Learning NetLogo extension
Kevin Kons Fernando Santos | Published Tuesday, December 10, 2019This is a re-implementation of a the NetLogo model Maze (ROOP, 2006).
This re-implementation makes use of the Q-Learning NetLogo Extension to implement the Q-Learning, which is done only with NetLogo native code in the original implementation.
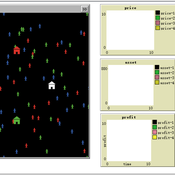
Dynamic pricing strategies for perishable products in a competitive multi-agent retailer market
Wenchong Chen Hongwei Liu | Published Monday, November 27, 2017 | Last modified Thursday, March 01, 2018This model explores a price Q-learning mechanism for perishable products that considers uncertain demand and customer preferences in a competitive multi-agent retailer market (a model-free environment).