About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 9 of 9 results reinforcement learning clear search
Agent-Based Model for Multiple Team Membership (ABMMTM)
Andrew Collins | Published Thursday, April 03, 2025The Agent-Based Model for Multiple Team Membership (ABMMTM) simulates design teams searching for viable design solutions, for a large design project that requires multiple design teams that are working simultaneously, under different organizational structures; specifically, the impact of multiple team membership (MTM). The key mechanism under study is how individual agent-level decision-making impacts macro-level project performance, specifically, wage cost. Each agent follows a stochastic learning approach, akin to simulated annealing or reinforcement learning, where they iteratively explore potential design solutions. The agent evaluates new solutions based on a random-walk exploration, accepting improvements while rejecting inferior designs. This iterative process simulates real-world problem-solving dynamics where designers refine solutions based on feedback.
As a proof-of-concept demonstration of assessing the macro-level effects of MTM in organizational design, we developed this agent-based simulation model which was used in a simulation experiment. The scenario is a system design project involving multiple interdependent teams of engineering designers. In this scenario, the required system design is split into three separate but interdependent systems, e.g., the design of a satellite could (trivially) be split into three components: power source, control system, and communication systems; each of three design team is in charge of a design of one of these components. A design team is responsible for ensuring its proposed component’s design meets the design requirement; they are not responsible for the design requirements of the other components. If the design of a given component does not affect the design requirements of the other components, we call this the uncoupled scenario; otherwise, it is a coupled scenario.
Using Agent-Based Modelling and Reinforcement Learning to Study Hybrid Threats
kpadur | Published Friday, September 20, 2024Hybrid attacks coordinate the exploitation of vulnerabilities across domains to undermine trust in authorities and cause social unrest. Whilst such attacks have primarily been seen in active conflict zones, there is growing concern about the potential harm that can be caused by hybrid attacks more generally and a desire to discover how better to identify and react to them. In addressing such threats, it is important to be able to identify and understand an adversary’s behaviour. Game theory is the approach predominantly used in security and defence literature for this purpose. However, the underlying rationality assumption, the equilibrium concept of game theory, as well as the need to make simplifying assumptions can limit its use in the study of emerging threats. To study hybrid threats, we present a novel agent-based model in which, for the first time, agents use reinforcement learning to inform their decisions. This model allows us to investigate the behavioural strategies of threat agents with hybrid attack capabilities as well as their broader impact on the behaviours and opinions of other agents.
NeoCOOP: The Neolithic Cooperation Model
Brandon Gower-Winter | Published Saturday, February 11, 2023NeoCOOP is an iteration-based ABM that uses Reinforcement Learning and Artificial Evolution as adaptive-mechanisms to simulate the emergence of resource trading beliefs among Neolithic-inspired households.
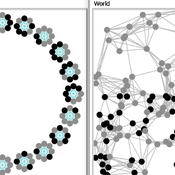
Two agent-based models of cooperation in dynamic groups and fixed social networks
Carlos A. de Matos Fernandes | Published Thursday, January 20, 2022Both models simulate n-person prisoner dilemma in groups (left figure) where agents decide to C/D – using a stochastic threshold algorithm with reinforcement learning components. We model fixed (single group ABM) and dynamic groups (bad-barrels ABM). The purpose of the bad-barrels model is to assess the impact of information during meritocratic matching. In the bad-barrels model, we incorporated a multidimensional structure in which agents are also embedded in a social network (2-person PD). We modeled a random and homophilous network via a random spatial graph algorithm (right figure).
FlipFlop1-ProMEERB: A coupled social-ecological model with a promotional mechanism for emergence of environmentally responsible behavior
Liliana Perez Saeed Harati Roberto Molowny-Horas | Published Friday, December 17, 2021At the heart of a study of Social-Ecological Systems, this model is built by coupling together two independently developed models of social and ecological phenomena. The social component of the model is an abstract model of interactions of a governing agent and several user agents, where the governing agent aims to promote a particular behavior among the user agents. The ecological model is a spatial model of spread of the Mountain Pine Beetle in the forests of British Columbia, Canada. The coupled model allowed us to simulate various hypothetical management scenarios in a context of forest insect infestations. The social and ecological components of this model are developed in two different environments. In order to establish the connection between those components, this model is equipped with a ‘FlipFlop’ - a structure of storage directories and communication protocols which allows each of the models to process its inputs, send an output message to the other, and/or wait for an input message from the other, when necessary. To see the publications associated with the social and ecological components of this coupled model please see the References section.
This model was developed to test the usability of evolutionary computing and reinforcement learning by extending a well known agent-based model. Sugarscape (Epstein & Axtell, 1996) has been used to demonstrate migration, trade, wealth inequality, disease processes, sex, culture, and conflict. It is on conflict that this model is focused to demonstrate how machine learning methodologies could be applied.
The code is based on the Sugarscape 2 Constant Growback model, availble in the NetLogo models library. New code was added into the existing model while removing code that was not needed and modifying existing code to support the changes. Support for the original movement rule was retained while evolutionary computing, Q-Learning, and SARSA Learning were added.
Auctionsimulation
Deniz Kayar | Published Wednesday, August 12, 2020This repository the multi-agent simulation software for the paper “Comparison of Competing Market Mechanisms with Reinforcement Learning in a CarPooling Scenario”. It’s a mutlithreaded Javaapplication.
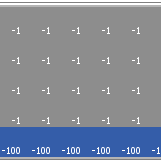
Cliff Walking with Q-Learning NetLogo Extension
Kevin Kons Fernando Santos | Published Tuesday, December 10, 2019This model implements a classic scenario used in Reinforcement Learning problem, the “Cliff Walking Problem”. Consider the gridworld shown below (SUTTON; BARTO, 2018). This is a standard undiscounted, episodic task, with start and goal states, and the usual actions causing movement up, down, right, and left. Reward is -1 on all transitions except those into the region marked “The Cliff.” Stepping into this region incurs a reward of -100 and sends the agent instantly back to the start (SUTTON; BARTO, 2018).
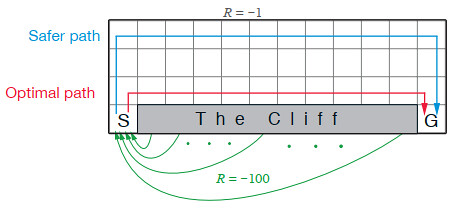
The problem is solved in this model using the Q-Learning algorithm. The algorithm is implemented with the support of the NetLogo Q-Learning Extension
Hedonic and Eudaimonic Well-being Based Reward for Intrinsic Motivated Reinforcement Learning Agents
Yue Gao Shimon Edelman | Published Monday, March 21, 2016The code contains four experiments for well-being based IMRL reward features.