Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 85 results for "Alessandro K Cerutti" clear search
An Agent-Based Model of Flood Risk and Insurance
J Dubbelboer I Nikolic K Jenkins J Hall | Published Monday, July 27, 2015 | Last modified Monday, October 03, 2016A model to show the effects of flood risk on a housing market; the role of flood protection for risk reduction; the working of the existing public-private flood insurance partnership in the UK, and the proposed scheme ‘Flood Re’.
The Effects of Fiscal Targets in a Currency Union: a Multi-Country Agent Based-Stock Flow Consistent Model
Ermanno Catullo Alessandro Caiani Mauro Gallegati | Published Saturday, March 11, 2017We present an Agent-Based Stock Flow Consistent Multi-Country model of a Currency Union to analyze the impact of changes in the fiscal regimes that is permanent changes in the deficit-to-GDP targets that governments commit to comply.
Peer reviewed BAMERS: Macroeconomic effect of extortion
Alejandro Platas López Alejandro Guerra-Hernández | Published Monday, March 23, 2020 | Last modified Sunday, July 26, 2020Inspired by the European project called GLODERS that thoroughly analyzed the dynamics of extortive systems, Bottom-up Adaptive Macroeconomics with Extortion (BAMERS) is a model to study the effect of extortion on macroeconomic aggregates through simulation. This methodology is adequate to cope with the scarce data associated to the hidden nature of extortion, which difficults analytical approaches. As a first approximation, a generic economy with healthy macroeconomics signals is modeled and validated, i.e., moderate inflation, as well as a reasonable unemployment rate are warranteed. Such economy is used to study the effect of extortion in such signals. It is worth mentioning that, as far as is known, there is no work that analyzes the effects of extortion on macroeconomic indicators from an agent-based perspective. Our results show that there is significant effects on some macroeconomics indicators, in particular, propensity to consume has a direct linear relationship with extortion, indicating that people become poorer, which impacts both the Gini Index and inflation. The GDP shows a marked contraction with the slightest presence of extortion in the economic system.
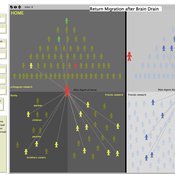
RETURN MIGRATION AFTER BRAIN DRAIN: A SIMULATION APPROACH
Alessandro Pluchino Alessio Emanuele Biondo Andrea Rapisarda | Published Friday, June 21, 2013This model, realized on the NetLogo platform, compares utility levels at home and abroad to simulate agents’ migration and their eventual return. Our model is based on two fundamental individual features, i.e. risk aversion and initial expectation, which characterize the dynamics of different agents according to the evolution of their social contacts.
Talent vs Luck: the role of randomness in success and failure
Alessandro Pluchino Alessio Emanuele Biondo Andrea Rapisarda | Published Monday, July 16, 2018The largely dominant meritocratic paradigm of highly competitive Western cultures is rooted on the belief that success is due mainly, if not exclusively, to personal qualities such as talent, intelligence, skills, smartness, efforts, willfulness, hard work or risk taking. Sometimes, we are willing to admit that a certain degree of luck could also play a role in achieving significant material success. But, as a matter of fact, it is rather common to underestimate the importance of external forces in individual successful stories. It is very well known that intelligence (or, more in general, talent and personal qualities) exhibits a Gaussian distribution among the population, whereas the distribution of wealth - often considered a proxy of success - follows typically a power law (Pareto law), with a large majority of poor people and a very small number of billionaires. Such a discrepancy between a Normal distribution of inputs, with a typical scale (the average talent or intelligence), and the scale invariant distribution of outputs, suggests that some hidden ingredient is at work behind the scenes. In a recent paper, with the help of this very simple agent-based model realized with NetLogo, we suggest that such an ingredient is just randomness. In particular, we show that, if it is true that some degree of talent is necessary to be successful in life, almost never the most talented people reach the highest peaks of success, being overtaken by mediocre but sensibly luckier individuals. As to our knowledge, this counterintuitive result - although implicitly suggested between the lines in a vast literature - is quantified here for the first time. It sheds new light on the effectiveness of assessing merit on the basis of the reached level of success and underlines the risks of distributing excessive honors or resources to people who, at the end of the day, could have been simply luckier than others. With the help of this model, several policy hypotheses are also addressed and compared to show the most efficient strategies for public funding of research in order to improve meritocracy, diversity and innovation.
A land-use model to illustrate ambiguity in design
Julia Schindler | Published Monday, October 15, 2012 | Last modified Friday, January 13, 2017This is an agent-based model that allows to test alternative designs for three model components. The model was built using the LUDAS design strategy, while each alternative is in line with the strategy. Using the model, it can be shown that alternative designs, though built on the same strategy, lead to different land-use patterns over time.
A Consumer in the Jungle of Product Differentiation
Alessandro Pluchino Andrea Rapisarda Alessio Emanuele Biondo Alfio Giarlotta | Published Tuesday, December 22, 2015Building upon the distance-based Hotelling’s differentiation idea, we describe the behavioral experience of several prototypes of consumers, who walk a hypothetical cognitive path in an attempt to maximize their satisfaction.
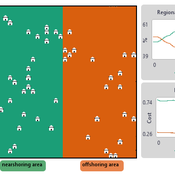
NOMAD: Near–Off Mobility under Aspiration Dynamics
Alejandro Platas López | Published Wednesday, December 17, 2025NOMAD is an agent-based model of firm location choice between two aggregate regions (“near” and “off”) under logistics uncertainty. Firms occupy sites characterised by attractiveness and logistics risk, earn a risk-adjusted payoff that depends on regional costs (wages plus congestion) and an individual risk-tolerance trait, and update location choices using aspiration-based satisficing rules with switching frictions. Logistics risk evolves endogenously on occupied sites through a region-specific absorption mechanism (good/bad events that reduce/increase risk), while congestion feeds back into regional costs via regional shares and local crowding. Runs stop endogenously once the near-region share becomes quasi-stable after burn-in, and the model records time series and quasi-stable outcomes such as near/off composition, switching intensity, costs, average risk, and average risk tolerance.
FilterBubbles_in_Carley1991
Benoît Desmarchelier | Published Wednesday, May 21, 2025The model is an extension of: Carley K. (1991) “A theory of group stability”, American Sociological Review, vol. 56, pp. 331-354.
The original model from Carley (1991) works as follows:
- Agents know or ignore a series of knowledge facts;
- At each time step, each agent i choose a partner j to interact with at random, with a probability of choice proportional to the degree of knowledge facts they have in common.
- Agents interact synchronously. As such, interaction happens only if the partnert j is not already busy interacting with someone else.
…
An Agent-Based Model of Saving under Quasi-Hyperbolic Discounting on a Social Network.
Jose Alejandro Velazquez Monzon | Published Wednesday, June 24, 2026An agent-based model of saving and dissaving behaviour under quasi-hyperbolic (β–δ) discounting. Building on the individual decision problem of Cao and Werning (2018), the model embeds present-biased agents in a Watts–Strogatz small-world network and adds three configurable mechanisms of social influence — information diffusion, peer comparison, and social-norm conformity — across five heterogeneous behavioural profiles (Planners, Moderates, Procrastinators, Inverse Procrastinators, and Impulsive agents).
Each profile’s saving policy is approximated by value-function iteration over a discretised wealth grid; the solved policies are cached and applied as agents interact over their network neighbourhoods. The model tests whether each social mechanism can alter the saving and wealth trajectories that present-biased agents would otherwise follow in isolation, and characterises the direction and size of each effect on median wealth, wealth inequality (Gini), and the incidence of severely depleted agents.
The deposit includes the core model (Model.py), an analysis and visualisation pipeline (analyze_results.py), a standalone ODD description (ODD.md), and pinned dependencies.
Displaying 10 of 85 results for "Alessandro K Cerutti" clear search