About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 111 results for "Alistair Law" clear search
This agent-based model (ABM), developed in NetLogo and available on the COMSES repository, simulates a stylized, competitive electricity market to explore the effects of carbon pricing policies under conditions of technological innovation. Unlike traditional models that treat innovation as exogenous, this ABM incorporates endogenous innovation dynamics, allowing clean technology costs to evolve based on cumulative deployment (Wright’s Law) or time (Moore’s Law). Electricity generation companies act as agents, making investment decisions across coal, gas, wind, and solar PV technologies based on expected returns and market conditions. The model evaluates three policy scenarios—No Policy, Emissions Trading System (ETS), and Carbon Tax—within a merit-order market framework. It is partially empirically grounded, using real-world data for technology costs and emissions caps. By capturing emergent system behavior, this model offers a flexible and transparent tool for analyzing the transition to low-carbon electricity systems.
Peer reviewed MADTOR: Model for Assessing Drug Trafficking Organizations Resilience
Deborah Manzi | Published Friday, February 23, 2024Criminal organizations operate in complex changing environments. Being flexible and dynamic allows criminal networks not only to exploit new illicit opportunities but also to react to law enforcement attempts at disruption, enhancing the persistence of these networks over time. Most studies investigating network disruption have examined organizational structures before and after the arrests of some actors but have disregarded groups’ adaptation strategies.
MADTOR simulates drug trafficking and dealing activities by organized criminal groups and their reactions to law enforcement attempts at disruption. The simulation relied on information retrieved from a detailed court order against a large-scale Italian drug trafficking organization (DTO) and from the literature.
The results showed that the higher the proportion of members arrested, the greater the challenges for DTOs, with higher rates of disrupted organizations and long-term consequences for surviving DTOs. Second, targeting members performing specific tasks had different impacts on DTO resilience: targeting traffickers resulted in the highest rates of DTO disruption, while targeting actors in charge of more redundant tasks (e.g., retailers) had smaller but significant impacts. Third, the model examined the resistance and resilience of DTOs adopting different strategies in the security/efficiency trade-off. Efficient DTOs were more resilient, outperforming secure DTOs in terms of reactions to a single, equal attempt at disruption. Conversely, secure DTOs were more resistant, displaying higher survival rates than efficient DTOs when considering the differentiated frequency and effectiveness of law enforcement interventions on DTOs having different focuses in the security/efficiency trade-off.
Overall, the model demonstrated that law enforcement interventions are often critical events for DTOs, with high rates of both first intention (i.e., DTOs directly disrupted by the intervention) and second intention (i.e., DTOs terminating their activities due to the unsustainability of the intervention’s short-term consequences) culminating in dismantlement. However, surviving DTOs always displayed a high level of resilience, with effective strategies in place to react to threatening events and to continue drug trafficking and dealing.
FEARLUS-SPOMM
Dawn Parker Gary Polhill Nick Gotts Alistair Law Luis Izquierdio Alessandro Gimona Lee-Ann Sutherland | Published Friday, March 25, 2016This is a coupled conceptual model of agricultural land decision-making and incentivisation and species metacommunities.
Individual-based modelling as a tool for elephant poaching mitigation
Ernesto Carrella Richard Bailey Emily Neil Jens Koed Madsen Nicolas Payette | Published Tuesday, June 18, 2019 | Last modified Thursday, August 01, 2019We develop an IBM that predicts how interactions between elephants, poachers, and law enforcement affect poaching levels within a virtual protected area. The model is theoretical at this stage and is not meant to provide a realistic depiction of poaching, but instead to demonstrate how IBMs can expand upon the existing modelling work done in this field, and to provide a framework for future research. The model could be further developed into a useful management support tool to predict the outcomes of various poaching mitigation strategies at real-world locations. The model was implemented in NetLogo version 6.1.0.
We first compared a scenario in which poachers have prescribed, non-adaptive decision-making and move randomly across the landscape, to one in which poachers adaptively respond to their memories of elephant locations and where other poachers have been caught by law enforcement. We then compare a situation in which ranger effort is distributed unevenly across the protected area to one in which rangers patrol by adaptively following elephant matriarchal herds.
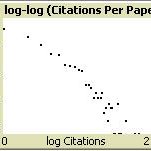
Citation Agents: A model of collective learning through scientific publication
Christopher Watts | Published Friday, July 31, 2015Simulates the construction of scientific journal publications, including authors, references, contents and peer review. Also simulates collective learning on a fitness landscape. Described in: Watts, Christopher & Nigel Gilbert (forthcoming) “Does cumulative advantage affect collective learning in science? An agent-based simulation”, Scientometrics.
This is a social trust model for investigating the social relationships and social networks in the real world and in social media.
Active Shooter: An Agent-Based Model of Unarmed Resistance
William Kennedy Tom Briggs | Published Thursday, December 29, 2016 | Last modified Tuesday, April 04, 2017A NetLogo ABM developed to explore unarmed resistance to an active shooter. The landscape is a generalized open outdoor area. Parameters enable the user to set shooter armament and control for assumptions with regard to shooter accuracy.
Talent vs Luck: the role of randomness in success and failure
Alessandro Pluchino Alessio Emanuele Biondo Andrea Rapisarda | Published Monday, July 16, 2018The largely dominant meritocratic paradigm of highly competitive Western cultures is rooted on the belief that success is due mainly, if not exclusively, to personal qualities such as talent, intelligence, skills, smartness, efforts, willfulness, hard work or risk taking. Sometimes, we are willing to admit that a certain degree of luck could also play a role in achieving significant material success. But, as a matter of fact, it is rather common to underestimate the importance of external forces in individual successful stories. It is very well known that intelligence (or, more in general, talent and personal qualities) exhibits a Gaussian distribution among the population, whereas the distribution of wealth - often considered a proxy of success - follows typically a power law (Pareto law), with a large majority of poor people and a very small number of billionaires. Such a discrepancy between a Normal distribution of inputs, with a typical scale (the average talent or intelligence), and the scale invariant distribution of outputs, suggests that some hidden ingredient is at work behind the scenes. In a recent paper, with the help of this very simple agent-based model realized with NetLogo, we suggest that such an ingredient is just randomness. In particular, we show that, if it is true that some degree of talent is necessary to be successful in life, almost never the most talented people reach the highest peaks of success, being overtaken by mediocre but sensibly luckier individuals. As to our knowledge, this counterintuitive result - although implicitly suggested between the lines in a vast literature - is quantified here for the first time. It sheds new light on the effectiveness of assessing merit on the basis of the reached level of success and underlines the risks of distributing excessive honors or resources to people who, at the end of the day, could have been simply luckier than others. With the help of this model, several policy hypotheses are also addressed and compared to show the most efficient strategies for public funding of research in order to improve meritocracy, diversity and innovation.
06b EiLab_Model_I_V5.00 NL
Garvin Boyle | Published Saturday, October 05, 2019EiLab - Model I - is a capital exchange model. That is a type of economic model used to study the dynamics of modern money which, strangely, is very similar to the dynamics of energetic systems. It is a variation on the BDY models first described in the paper by Dragulescu and Yakovenko, published in 2000, entitled “Statistical Mechanics of Money”. This model demonstrates the ability of capital exchange models to produce a distribution of wealth that does not have a preponderance of poor agents and a small number of exceedingly wealthy agents.
This is a re-implementation of a model first built in the C++ application called Entropic Index Laboratory, or EiLab. The first eight models in that application were labeled A through H, and are the BDY models. The BDY models all have a single constraint - a limit on how poor agents can be. That is to say that the wealth distribution is bounded on the left. This ninth model is a variation on the BDY models that has an added constraint that limits how wealthy an agent can be? It is bounded on both the left and right.
EiLab demonstrates the inevitable role of entropy in such capital exchange models, and can be used to examine the connections between changing entropy and changes in wealth distributions at a very minute level.
…
Income and Expenditure
Tony Lawson | Published Thursday, October 06, 2011 | Last modified Saturday, April 27, 2013How do households alter their spending patterns when they experience changes in income? This model answers this question using a random assignment scheme where spending patterns are copied from a household in the new income bracket.
Displaying 10 of 111 results for "Alistair Law" clear search