Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 59 results income clear search

Simulating Climate Stress and Social Instability: An Agent-Based Model of Ecosystem Degradation and Violence in Coastal Communities
Jacopo A. Baggio hurtado-valdivieso | Published Sunday, April 12, 2026This model is an agent-based simulation designed to explore how climate-induced environmental degradation can contribute to the emergence of social violence in coastal communities that depend heavily on ecosystem services for their livelihoods. The model represents a coupled social–ecological system in which environmental shocks—such as sea level rise and marine ecosystem decline—affect local economic conditions, food security, and community stability.
Agents in the model represent individuals whose livelihoods depend on coastal ecosystems. Environmental degradation reduces ecosystem productivity and increases economic hardship, which can lead to the formation of grievances among agents. The model incorporates behavioral thresholds that determine how individuals respond to hardship and perceived injustice. Under certain conditions—particularly when institutional capacity and law enforcement effectiveness are limited—these grievances may escalate into violent behavior.
The simulation allows users to explore how different climate scenarios, levels of ecosystem degradation, livelihood dependence, and institutional responses influence the probability of social instability and violence. By modeling the interactions between environmental stress, socio-economic vulnerability, and governance capacity, the model provides a computational framework for examining potential pathways linking climate change and conflict in coastal social–ecological systems.
…
A simulation model for Dublin city
umesh7lowe | Published Friday, April 10, 2026An agent-based model of urban travel behaviour in Dublin, Ireland, built in NetLogo and empirically grounded in 2016 travel survey data. Each agent represents a Dublin resident initialised with real socio-demographic attributes — including age, gender, household size and car ownership, income, driving licence status, and access to local amenities — alongside observed trip characteristics such as distance, travel time, and trip type (work, shopping, leisure).
At each time step, agents choose between four transport modes (car, public transport, cycling, and walking) across short, medium, and long trips. Mode choice is governed by a preference vector that weighs personal need satisfaction against social influence from neighbouring agents reflecting consumat framework. Satisfaction evolves dynamically based on cost (incorporating Irish motor tax bands and per-km operating rates), travel time, and trip-type suitability, with an uncertainty parameter capturing variability in perceived utility over time.
The model tracks aggregate modal shares and total CO2 emission at each tick, enabling exploration of how policy interventions — such as fuel taxation, public transport pricing, or active travel incentives — might shift the city’s travel demand profile over 100 simulated days.
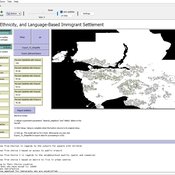
Geospatial Agent-Based Model of Immigrant Settlement Dynamics in Metro Vancouver
Liliana Perez Navid Mahdizadeh Gharakhanlou Maryam Yousefi | Published Wednesday, December 03, 2025This agent-based model simulates how new immigrant households choose where to live in Metro Vancouver under the origins diversity scenario. The model begins with 16,000 household agents, reflecting an expected annual population increase of about 42,500 people based on an average household size of 2.56. Each agent is assigned four characteristics: one of ten origin categories, income level (adjusted using NOC data and recent immigrant earnings), likelihood of having children, and preferred mode of commuting. The ten origin groups are drawn from Census patterns, including six subgroups within the broader Asian category (China, India, the Philippines, Iran, South Korea, and Other Asian countries) and two categories for immigrants from the Americas. This refined classification better captures the diversity of newcomers arriving in the region.
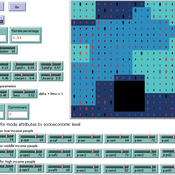
Peer reviewed Urban Transport Mode Choices
Kathleen Salazar -Serna Lorena Cadavid Carlos Franco | Published Thursday, May 22, 2025The model represents urban commuters’ transport mode choices among cars, public transit, and motorcycles—a mode highly prevalent in developing countries. Using an agent-based modeling approach, it simulates transport dynamics and serves as a testbed for evaluating policies aimed at improving mobility.
The model simulates an ecosystem of human agents who decide, at each time step, which mode of transportation to use for commuting to work. Their decision is based on a combination of personal satisfaction with their most recent journey—evaluated across a vector of individual needs—the information they crowdsource from their social network, and their personal uncertainty regarding trying new transport options.
Agents are assigned demographic attributes such as sex, age, and income level, and are distributed across city neighborhoods according to their socioeconomic status. To represent social influence in decision-making, agents are connected via a scale-free social network topology, where connections are more likely among agents within the same socioeconomic group, reflecting the tendency of individuals to form social ties with similar others.
…
Finance and Market Concentration Using Agent-Based Modeling: Evidence from South Korea
Yunkyeong Seo Zeynep Elif Altiner Sumin Lee Ilchul Moon Taesub Yun | Published Friday, March 28, 2025Amidst the global trend of increasing market concentration, this paper examines the role of finance
in shaping it. Using Agent-Based Modeling (ABM), we analyze the impact of financial policies on market concentration
and its closely related variables: economic growth and labor income share. We extend the Keynes
meets Schumpeter (K+S) model by incorporating two critical assumptions that influence market concentration.
Policy experiments are conducted with a model validated against historical trends in South Korea. For policy
variables, the Debt-to-Sales Ratio (DSR) limit and interest rate are used as levers to regulate the quantity and
…
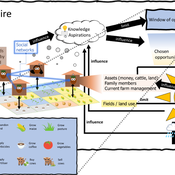
3spire: an agent-based model for exploring aspiration adaptation theory and its implications on smallholder farmers in Ethiopia
ateeuw Yue Dou Markus A Meyer Andrew Nelson | Published Sunday, February 16, 20253spire is an ABM where farming households make management decisions aimed at satisficing along the aspirational dimensions: food self-sufficiency, income, and leisure. Households decision outcomes depend on their social networks, knowledge, assets, household needs, past management, and climate/market trends
Gini Palma microsimulation
Edgar Oliveira | Published Wednesday, December 11, 2024The model is a microsimulation, where the agents don’t Interact with each other. It simulates income distribution, unemployment dynamics, education, and Family grant in Brazil, focusing on the impact on social inequality. It tracks the indicators Gini index, Lorenz curve, and Palma ratio. The objective is to explore how these factors influence wealth distribution and social inequality over time.
This work was developed in partnership with the Graduate Program in Computational Modeling, in the Universidade Federal do Rio Grande - FURG, in Brazil.
The effects of complementary microfinance service on income and lifting poor out of poverty: An agent-based modeling study
Mohammad Reza Sadeghi Moghaddam Mehrdad Hamidi Hedayat | Published Thursday, June 27, 2024This model simulate the process of borrowing from an Microfinance Institute (MFI) and starting a business within a poor household.
Critical Sustainability Transitions: Relaunching local agriculture after decline (Model code and description)
Pedro Lopez-Merino | Published Tuesday, April 30, 2024This model simulates the dynamics of agricultural land use change, specifically the transition between agricultural and non-agricultural land use in a spatial context. It explores the influence of various factors such as agricultural profitability, path dependency, and neighborhood effects on land use decisions.
The model operates on a grid of patches representing land parcels. Each patch can be in one of two states: exploited (green, representing agricultural land) or unexploited (brown, representing non-agricultural land). Agents (patches) transition between these states based on probabilistic rules. The main factors affecting these transitions are agricultural profitability, path dependency, and neighborhood effects.
-Agricultural Profitability: This factor is determined by the prob-agri function, which calculates the probability of a non-agricultural patch converting to agricultural based on income differences between agriculture and other sectors. -Path Dependency: Represented by the path-dependency parameter, it influences the likelihood of patches changing their state based on their current state. It’s a measure of inertia or resistance to change. -Neighborhood Effects: The neighborhood function calculates the number of exploited (agricultural) neighbors of a patch. This influences the decision of a patch to convert to agricultural land, representing the influence of surrounding land use on the decision-making process.
AgriAdopt
Sebastian Rasch | Published Tuesday, March 26, 2024The purpose of this model is to project the dynamics of technology adoption of autonomous weeding robots by sugar beet producing farmers in North Rhine-Westphalia (NRW). Moreover, the design of the model serves the purpose to investigate second-order effects of robot adoption on shifts in farm income and on production quantities of main crops produced in North Rhine-Westphalia. One aim is to analyse the impact of technology attributes and costs of pesticides on adoption patterns.
Displaying 10 of 59 results income clear search