Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 120 results random clear search
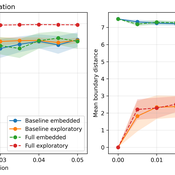
From Boundary Crossings to Global Connectivity: A Minimal Mechanism in Structured Agent-Based Landscapes
Fabio Nelli | Published Sunday, May 17, 2026This repository contains the Python implementation of an agent-based model investigating how localized boundary-crossing dynamics generate large-scale connectivity in structured multi-attractor landscapes.
Agents evolve in a continuous two-dimensional environment composed of attractor basins. A fraction of agents exhibits exploratory higher-mobility dynamics, while the remaining agents remain locally constrained. The model analyzes how localized configurational transitions accumulate into transition networks that progressively integrate the explored state space.
The repository includes:
…

Simulating Climate Stress and Social Instability: An Agent-Based Model of Ecosystem Degradation and Violence in Coastal Communities
Jacopo A. Baggio hurtado-valdivieso | Published Sunday, April 12, 2026This model is an agent-based simulation designed to explore how climate-induced environmental degradation can contribute to the emergence of social violence in coastal communities that depend heavily on ecosystem services for their livelihoods. The model represents a coupled social–ecological system in which environmental shocks—such as sea level rise and marine ecosystem decline—affect local economic conditions, food security, and community stability.
Agents in the model represent individuals whose livelihoods depend on coastal ecosystems. Environmental degradation reduces ecosystem productivity and increases economic hardship, which can lead to the formation of grievances among agents. The model incorporates behavioral thresholds that determine how individuals respond to hardship and perceived injustice. Under certain conditions—particularly when institutional capacity and law enforcement effectiveness are limited—these grievances may escalate into violent behavior.
The simulation allows users to explore how different climate scenarios, levels of ecosystem degradation, livelihood dependence, and institutional responses influence the probability of social instability and violence. By modeling the interactions between environmental stress, socio-economic vulnerability, and governance capacity, the model provides a computational framework for examining potential pathways linking climate change and conflict in coastal social–ecological systems.
…
Negotiation Lab 1.0
Julián Arévalo | Published Friday, March 20, 2026Negotiation Lab 1.0 is an agent-based model of peace negotiations that explores how the parties’ readiness — their motivation and optimism to engage in talks — evolves dynamically throughout the negotiation process. The model reconceptualizes readiness as an adaptive state variable that is continuously updated through feedback from negotiation outcomes, rather than a static precondition assessed at the onset of talks.
The model simulates two parties negotiating a multi-issue agenda. In each round, parties allocate effort to the current sub-issue; outcomes depend on their joint effort and a stochastic component representing external factors. Results feed back into each party’s readiness, shaping subsequent engagement. The negotiation ends either when all agenda items are resolved (agreement) or when a party’s readiness falls below a critical threshold (breakdown).
Key parameters include the initial readiness of each party, agenda structure (balanced, hard, easy, red, or random), type of negotiation (from highly cooperative to highly competitive), and each party’s effort strategy (always high, always low, random, or pseudo tit-for-tat). The model shows that while initial readiness is associated with negotiation outcomes, it is neither necessary nor sufficient to determine them: process variables — the type of interaction, agenda design, and adaptive effort strategies — exert comparatively larger effects on outcomes. Identical initial conditions can produce widely divergent trajectories, illustrating path dependence and sensitivity to feedback dynamics.
The model is implemented in NetLogo 7.0 and is documented using the ODD+D protocol. It is associated with the paper “Beyond Initial Conditions: How Adaptive Readiness Shapes Peace Negotiation Outcomes” (Arévalo, under review).
Peer reviewed Gradient Descent Simulation
Ilyes Azouani | Published Wednesday, March 18, 2026 | Last modified Monday, May 25, 2026This model visualizes gradient descent optimization - the fundamental algorithm used to train neural networks and other machine learning models. Agents represent different optimization algorithms searching for the minimum of a loss landscape (the “error surface” that ML models try to minimize during training).
The model demonstrates how different optimizer types (SGD, Momentum with different parameters) behave on various loss landscapes, from simple bowls to the notoriously difficult Rosenbrock “banana valley” function. This helps build intuition about why certain optimization algorithms work better than others for different problem geometries.
HOW IT WORKS
…
NetLogo Model of Spatial Eviction in Attraction-Repulsion Opinion Dynamics
poyeker | Published Friday, March 13, 2026A reproducible NetLogo implementation of a spatial attraction-repulsion opinion model with eviction-driven relocation. Agents interact locally, converge with similar neighbors, diverge from dissimilar neighbors, and may evict the most dissimilar neighbor to a random empty location. Parameter sweeps reveal transitions among extremist, mixed, and consensus regimes, with outputs including phase diagrams, opinion distributions, and Moran’s I. The model is intended to reproduce and extend results on how exclusion frequency changes polarization outcomes.
Peer reviewed Green Consumption Tipping Point
Mario | Published Thursday, February 26, 2026This model is a minimal agent-based model (ABM) of green consumption and market tipping dynamics in a stylised two-firm economy. It is designed as an existence proof to illustrate how weak individual preferences, when combined with habit formation, social influence, and firm price adaptation, can generate non-linear transitions (tipping points) in market outcomes.
The economy consists of:
1) Two firms, each supplying a differentiated consumption bundle that differs in its fixed green share (one relatively greener, one less green).
2) Many households, each consuming a unit mass per period and allocating consumption between the two firms.
…
Peer reviewed MicroAnts 2.5
Diogo Alves | Published Thursday, October 16, 2025MicroAnts 2.5 is a general-purpose agent-based model designed as a flexible workhorse for simulating ecological and evolutionary dynamics in artificial populations, as well as, potentially, the emergence of political institutions and economic regimes. It builds on and extends Stephen Wright’s original MicroAnts 2.0 by introducing configurable predators, inequality tracking, and other options.
Ant agents are of two tyes/casts and controlled by 16-bit chromosomes encoding traits such as vision, movement, mating thresholds, sensing, and combat strength. Predators (anteaters) operate in static, random, or targeted predatory modes. Ants reproduce, mutate, cooperate, fight, and die based on their traits and interactions. Environmental pressures (poison and predators) and social dynamics (sharing, mating, combat) drive emergent behavior across red and black ant populations.
The model supports insertion of custom agents at runtime, configurable mutation/inversion rates, and exports detailed statistics, including inequality metrics (e.g., Gini coefficients), trait frequencies, predator kills, and lineage data. Intended for rapid testing and educational experimentation, MicroAnts 2.5 serves as a modular base for more complex ecological and social simulations.
Netlogo model ` Effect of Network Homophily and Partisanship on Social Media to “Oil Spill” Polarizations’
takuya nagura | Published Saturday, September 13, 2025This model was utilized for the simulation in the paper titled Effect of Network Homophily and Partisanship on Social Media to “Oil Spill” Polarizations. It allows you to examine whether oil spill polarization occurs through people’s communication under various conditions.
・Choose the network construction conditions you’d like to examine from the “rewire-style” chooser box.
・Select the desired strength of partisanship from the “partisanlevel” chooser box. You can also set the strength manually in the code tab.
・You can set the number of dynamic topics using the “number-of-topics” slider.
・Use the “divers-of-opinion” slider to set the number of preference types for each dynamic topic.
…
FilterBubbles_in_Carley1991
Benoît Desmarchelier | Published Wednesday, May 21, 2025The model is an extension of: Carley K. (1991) “A theory of group stability”, American Sociological Review, vol. 56, pp. 331-354.
The original model from Carley (1991) works as follows:
- Agents know or ignore a series of knowledge facts;
- At each time step, each agent i choose a partner j to interact with at random, with a probability of choice proportional to the degree of knowledge facts they have in common.
- Agents interact synchronously. As such, interaction happens only if the partnert j is not already busy interacting with someone else.
…
Agent-Based Model for Multiple Team Membership (ABMMTM)
Andrew Collins | Published Thursday, April 03, 2025The Agent-Based Model for Multiple Team Membership (ABMMTM) simulates design teams searching for viable design solutions, for a large design project that requires multiple design teams that are working simultaneously, under different organizational structures; specifically, the impact of multiple team membership (MTM). The key mechanism under study is how individual agent-level decision-making impacts macro-level project performance, specifically, wage cost. Each agent follows a stochastic learning approach, akin to simulated annealing or reinforcement learning, where they iteratively explore potential design solutions. The agent evaluates new solutions based on a random-walk exploration, accepting improvements while rejecting inferior designs. This iterative process simulates real-world problem-solving dynamics where designers refine solutions based on feedback.
As a proof-of-concept demonstration of assessing the macro-level effects of MTM in organizational design, we developed this agent-based simulation model which was used in a simulation experiment. The scenario is a system design project involving multiple interdependent teams of engineering designers. In this scenario, the required system design is split into three separate but interdependent systems, e.g., the design of a satellite could (trivially) be split into three components: power source, control system, and communication systems; each of three design team is in charge of a design of one of these components. A design team is responsible for ensuring its proposed component’s design meets the design requirement; they are not responsible for the design requirements of the other components. If the design of a given component does not affect the design requirements of the other components, we call this the uncoupled scenario; otherwise, it is a coupled scenario.
Displaying 10 of 120 results random clear search