Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 16 results sex clear search
Peer reviewed Urban Transport Mode Choices
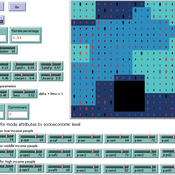
Kathleen Salazar -Serna Lorena Cadavid Carlos Franco | Published Thursday, May 22, 2025The model represents urban commuters’ transport mode choices among cars, public transit, and motorcycles—a mode highly prevalent in developing countries. Using an agent-based modeling approach, it simulates transport dynamics and serves as a testbed for evaluating policies aimed at improving mobility.
The model simulates an ecosystem of human agents who decide, at each time step, which mode of transportation to use for commuting to work. Their decision is based on a combination of personal satisfaction with their most recent journey—evaluated across a vector of individual needs—the information they crowdsource from their social network, and their personal uncertainty regarding trying new transport options.
Agents are assigned demographic attributes such as sex, age, and income level, and are distributed across city neighborhoods according to their socioeconomic status. To represent social influence in decision-making, agents are connected via a scale-free social network topology, where connections are more likely among agents within the same socioeconomic group, reflecting the tendency of individuals to form social ties with similar others.
…
Peer reviewed INOvPOP
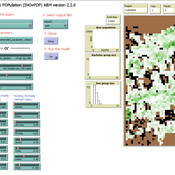
Aniruddha Belsare | Published Wednesday, June 01, 2022 | Last modified Wednesday, July 10, 2024INOvPOP is designed to simulate population dynamics (abundance, sex-age composition and distribution in the landscape) of white-tailed deer (Odocoileus virginianus) for selected Indiana counties. Updated for netLogo 6.4.0
The Levers of HIV Model
Arthur Hjorth Wouter Vermeer C. Hendricks Brown Uri Wilensky Can Gurkan | Published Tuesday, March 08, 2022 | Last modified Tuesday, October 31, 2023Chicago’s demographic, neighborhood, sex risk behaviors, sexual network data, and HIV prevention and treatment cascade information from 2015 were integrated as input to a new agent-based model (ABM) called the Levers-of-HIV-Model (LHM). This LHM, written in NetLogo, forms patterns of sexual relations among Men who have Sex with Men (MSM) based on static traits (race/ethnicity, and age) and dynamic states (sexual relations and practices) that are found in Chicago. LHM’s five modules simulate and count new infections at the two marker years of 2023 and 2030 for a wide range of distinct scenarios or levers, in which the levels of PrEP and ART linkage to care, retention, and adherence or viral load are increased over time from the 2015 baseline levels.

HyperMu’NmGA - Effect of Hypermutation Cycles in a NetLogo Minimal Genetic Algorithm
Cosimo Leuci | Published Tuesday, October 27, 2020 | Last modified Sunday, July 31, 2022A minimal genetic algorithm was previously developed in order to solve an elementary arithmetic problem. It has been modified to explore the effect of a mutator gene and the consequent entrance into a hypermutation state. The phenomenon seems relevant in some types of tumorigenesis and in a more general way, in cells and tissues submitted to chronic sublethal environmental or genomic stress.
For a long time, some scholars suppose that organisms speed up their own evolution by varying mutation rate, but evolutionary biologists are not convinced that evolution can select a mechanism promoting more (often harmful) mutations looking forward to an environmental challenge.
The model aims to shed light on these controversial points of view and it provides also the features required to check the role of sex and genetic recombination in the mutator genes diffusion.
This model was developed to test the usability of evolutionary computing and reinforcement learning by extending a well known agent-based model. Sugarscape (Epstein & Axtell, 1996) has been used to demonstrate migration, trade, wealth inequality, disease processes, sex, culture, and conflict. It is on conflict that this model is focused to demonstrate how machine learning methodologies could be applied.
The code is based on the Sugarscape 2 Constant Growback model, availble in the NetLogo models library. New code was added into the existing model while removing code that was not needed and modifying existing code to support the changes. Support for the original movement rule was retained while evolutionary computing, Q-Learning, and SARSA Learning were added.
This model extends the original Artifical Anasazi (AA) model to include individual agents, who vary in age and sex, and are aggregated into households. This allows more realistic simulations of population dynamics within the Long House Valley of Arizona from AD 800 to 1350 than are possible in the original model. The parts of this model that are directly derived from the AA model are based on Janssen’s 1999 Netlogo implementation of the model; the code for all extensions and adaptations in the model described here (the Artificial Long House Valley (ALHV) model) have been written by the authors. The AA model included only ideal and homogeneous “individuals” who do not participate in the population processes (e.g., birth and death)–these processes were assumed to act on entire households only. The ALHV model incorporates actual individual agents and all demographic processes affect these individuals. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. Thus, the ALHV model is a combination of individual processes (birth and death) and household-level processes (e.g., finding suitable agriculture plots).
As is the case for the AA model, the ALHV model makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original model (from Janssen’s Netlogo implementation) to estimate annual maize productivity of various agricultural zones within the valley. These estimates are used to determine suitable locations for households and farms during each year of the simulation.
NetLogo HIV spread model
Wouter Vermeer | Published Friday, October 25, 2019This model describes the tranmission of HIV by means of unprotected anal intercourse in a population of men-who-have-sex-with-men.
The model is parameterized based on field data from a cohort study conducted in Atlanta Georgia.
An agent-based model to simulate meat consumption behaviour of consumers in Britain
Andrea Scalco | Published Friday, October 18, 2019The current rate of production and consumption of meat poses a problem both to peoples’ health and to the environment. This work aims to develop a simulation of peoples’ meat consumption behaviour in Britain using agent-based modelling. The agents represent individual consumers. The key variables that characterise agents include sex, age, monthly income, perception of the living cost, and concerns about the impact of meat on the environment, health, and animal welfare. A process of peer influence is modelled with respect to the agents’ concerns. Influence spreads across two eating networks (i.e. co-workers and household members) depending on the time of day, day of the week, and agents’ employment status. Data from a representative sample of British consumers is used to empirically ground the model. Different experiments are run simulating interventions of application of social marketing campaigns and a rise in price of meat. The main outcome is the average weekly consumption of meat per consumer. A secondary outcome is the likelihood of eating meat.
Modeling a Victim-Centered Approach for Detection of Human Trafficking Victims within Migration Flows
Kyle Ballard Brant M Horio | Published Saturday, September 23, 2017The model employs an agent-based model for exploring the victim-centered approach to identifying human trafficking and the approach’s effectiveness in an abstract representation of migrant flows.

Peer reviewed MOOvPOP
Matthew Gompper Aniruddha Belsare Joshua J Millspaugh | Published Monday, April 10, 2017 | Last modified Saturday, April 19, 2025MOOvPOP is designed to simulate population dynamics (abundance, sex-age composition and distribution in the landscape) of white-tailed deer (Odocoileus virginianus) for a selected sampling region.
Displaying 10 of 16 results sex clear search