Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 192 results reviewed clear search
Peer reviewed Agent-Based Ramsey growth model with endogenous technical progress (ABRam-T)
Sarah Wolf Aida Sarai Figueroa Alvarez Malika Tokpanova | Published Wednesday, February 14, 2024 | Last modified Monday, February 19, 2024The Agent-Based Ramsey growth model is designed to analyze and test a decentralized economy composed of utility maximizing agents, with a particular focus on understanding the growth dynamics of the system. We consider farms that adopt different investment strategies based on the information available to them. The model is built upon the well-known Ramsey growth model, with the introduction of endogenous technical progress through mechanisms of learning by doing and knowledge spillovers.
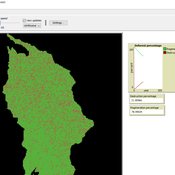
Peer reviewed Deforestation
MohammadAli Aghajani | Published Saturday, January 20, 2024 | Last modified Thursday, August 14, 2025Deforestation Simulation Model in NetLogo with GIS Layers
This model has developed in Netlogo software and utilizes
the GIS extension.
This NetLogo-based agent-based model (ABM) simulates deforestation dynamics using the GIS extension. It incorporates parameters like wood extraction, forest regeneration, agricultural expansion, and livestock impact. The model integrates spatial layers, including forest areas, agriculture zones, rural settlements, elevation, slope, and livestock distribution. Outputs include real-time graphical representations of forest loss, regeneration, and land-use changes. This model helps analyze deforestation patterns and conservation strategies using ABM and GIS.

Peer reviewed Credit and debt market of low-income families
Márton Gosztonyi | Published Tuesday, December 12, 2023 | Last modified Friday, January 19, 2024The purpose of the Credit and debt market of low-income families model is to help the user examine how the financial market of low-income families works.
The model is calibrated based on real-time data which was collected in a small disadvantaged village in Hungary it contains 159 households’ social network and attributes data.
The simulation models the households’ money liquidity, expenses and revenue structures as well as the formal and informal loan institutions based on their network connections. The model forms an intertwined system integrated in the families’ local socioeconomic context through which families handle financial crises and overcome their livelihood challenges from one month to another.
The simulation-based on the abstract model of low-income families’ financial survival system at the bottom of the pyramid, which was described in following the papers:
…
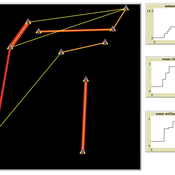
Peer reviewed Visibility of archaeological social networks
Claudine Gravel-Miguel | Published Sunday, November 26, 2023The purpose of this model is to explore the impact of combining archaeological palimpsests with different methods of cultural transmission on the visibility of prehistoric social networks. Up until recently, Paleolithic archaeologists have relied on stylistic similarities of artifacts to reconstruct social networks. However, this method - which is successfully applied to more recent ceramic assemblages - may not be applicable to Paleolithic assemblages, as several of those consist of palimpsests of occupations. Therefore, this model was created to study how palimpsests of occupation affect our social network reconstructions.
The model simplifies inter-groups interactions between populations who share cultural traits as they produce artifacts. It creates a proxy archaeological record of artifacts with stylistic traits that can then be used to reconstruct interactions. One can thus use this model to compare the networks reconstructed through stylistic similarities with direct contact.
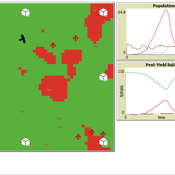
Peer reviewed Avian pest control: Yield outcome due to insectivorous birds, falconry, and integration of nest boxes.
David Jung | Published Monday, November 13, 2023 | Last modified Sunday, November 19, 2023The model aims to simulate predator-prey relationships in an agricultural setting. The focus lies on avian communities and their effect on different pest organisms (here: pest birds, rodents, and arthropod pests). Since most case studies focused on the impact on arthropod pests (AP) alone, this model attempts to include effects on yield outcome. By incorporating three treatments with different factor levels (insectivorous bird species, falconry, nest box density) an experimental setup is given that allows for further statistical analysis to identify an optimal combination of the treatments.
In light of a global decline of birds, insects, and many other groups of organisms, alternative practices of pest management are heavily needed to reduce the input of pesticides. Avian pest control therefore poses an opportunity to bridge the disconnect between humans and nature by realizing ecosystem services and emphasizing sustainable social ecological systems.

Peer reviewed COMMONSIM: Simulating the utopia of COMMONISM
Lena Gerdes Manuel Scholz-Wäckerle Ernest Aigner Stefan Meretz Jens Schröter Hanno Pahl Annette Schlemm Simon Sutterlütti | Published Sunday, November 05, 2023This research article presents an agent-based simulation hereinafter called COMMONSIM. It builds on COMMONISM, i.e. a large-scale commons-based vision for a utopian society. In this society, production and distribution of means are not coordinated via markets, exchange, and money, or a central polity, but via bottom-up signalling and polycentric networks, i.e. ex-ante coordination via needs. Heterogeneous agents care for each other in life groups and produce in different groups care, environmental as well as intermediate and final means to satisfy sensual-vital needs. Productive needs decide on the magnitude of activity in groups for a common interest, e.g. the production of means in a multi-sectoral artificial economy. Agents share cultural traits identified by different behaviour: a propensity for egoism, leisure, environmentalism, and productivity. The narrative of this utopian society follows principles of critical psychology and sociology, complexity and evolution, the theory of commons, and critical political economy. The article presents the utopia and an agent-based study of it, with emphasis on culture-dependent allocation mechanisms and their social and economic implications for agents and groups.
Peer reviewed Yards
srailsback Emily Minor Soraida Garcia Philip Johnson | Published Thursday, November 02, 2023This is a model of plant communities in urban and suburban residential neighborhoods. These plant communities are of interest because they provide many benefits to human residents and also provide habitat for wildlife such as birds and pollinators. The model was designed to explore the social factors that create spatial patterns in biodiversity in yards and gardens. In particular, the model was originally developed to determine whether mimicry behaviors–-or neighbors copying each other’s yard design–-could produce observed spatial patterns in vegetation. Plant nurseries and socio-economic constraints were also added to the model as other potential sources of spatial patterns in plant communities.
The idea for the model was inspired by empirical patterns of spatial autocorrelation that have been observed in yard vegetation in Chicago, Illinois (USA), and other cities, where yards that are closer together are more similar than yards that are farther apart. The idea is further supported by literature that shows that people want their yards to fit into their neighborhood. Currently, the yard attribute of interest is the number of plant species, or species richness. Residents compare the richness of their yards to the richness of their neighbors’ yards. If a resident’s yard is too different from their neighbors, the resident will be unhappy and change their yard to make it more similar.
The model outputs information about the diversity and identity of plant species in each yard. This can be analyzed to look for spatial autocorrelation patterns in yard diversity and to explore relationships between mimicry behaviors, yard diversity, and larger scale diversity.
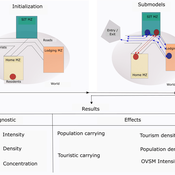
Peer reviewed ABM Overtourism Santa Marta
Janwar Moreno | Published Monday, October 23, 2023This model presents the simulation model of a city in the context of overtourism. The study area is the city of Santa Marta in Colombia. The purpose is to illustrate the spatial and temporal distribution of population and tourists in the city. The simulation analyzes emerging patterns that result from the interaction between critical components in the touristic urban system: residents, urban space, touristic sites, and tourists. The model is an Agent-Based Model (ABM) with the GAMA software. Also, it used public input data from statistical centers, geographical information systems, tourist websites, reports, and academic articles. The ABM includes assessing some measures used to address overtourism. This is a field of research with a low level of analysis for destinations with overtourism, but the ABM model allows it. The results indicate that the city has a high risk of overtourism, with spatial and temporal differences in the population distribution, and it illustrates the effects of two management measures of the phenomenon on different scales. Another interesting result is the proposed tourism intensity indicator (OVsm), taking into account that the tourism intensity indicators used by the literature on overtourism have an overestimation of tourism pressures.

Peer reviewed HUMLAND: HUMan impact on LANDscapes agent-based model
Fulco Scherjon Anastasia Nikulina Anhelina Zapolska Maria Antonia Serge Marco Davoli Dave van Wees Katharine MacDonald | Published Monday, October 16, 2023The HUMan impact on LANDscapes (HUMLAND) model has been developed to track and quantify the intensity of different impacts on landscapes at the continental level. This agent-based model focuses on determining the most influential factors in the transformation of interglacial vegetation with a specific emphasis on burning organized by hunter-gatherers. HUMLAND integrates various spatial datasets as input and target for the agent-based model results. Additionally, the simulation incorporates recently obtained continental-scale estimations of fire return intervals and the speed of vegetation regrowth. The obtained results include maps of possible scenarios of modified landscapes in the past and quantification of the impact of each agent, including climate, humans, megafauna, and natural fires.
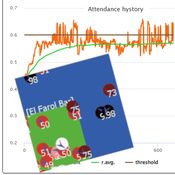
Peer reviewed Flibs’NFarol: Self-Organized Efficiency and Fairness Emergence in an Evolutive Game
Cosimo Leuci | Published Thursday, October 12, 2023According to the philosopher of science K. Popper “All life is problem solving”. Genetic algorithms aim to leverage Darwinian selection, a fundamental mechanism of biological evolution, so as to tackle various engineering challenges.
Flibs’NFarol is an Agent Based Model that embodies a genetic algorithm applied to the inherently ill-defined “El Farol Bar” problem. Within this context, a group of agents operates under bounded rationality conditions, giving rise to processes of self-organization involving, in the first place, efficiency in the exploitation of available resources. Over time, the attention of scholars has shifted to equity in resource distribution, as well. Nowadays, the problem is recognized as paradigmatic within studies of complex evolutionary systems.
Flibs’NFarol provides a platform to explore and evaluate factors influencing self-organized efficiency and fairness. The model represents agents as finite automata, known as “flibs,” and offers flexibility in modifying the number of internal flibs states, which directly affects their behaviour patterns and, ultimately, the diversity within populations and the complexity of the system.
Displaying 10 of 192 results reviewed clear search