About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 175 results information clear search
Anxiety-to-Approach Agent-Based Model (Netlogo)
Marie Lisa Kogler | Published Tuesday, April 04, 2023An Agent-Based Model to simulate agent reactions to threatening information based on the anxiety-to-approach framework of Jonas et al. (2014).
The model showcases the framework of BIS/BAS (inhibitory and approach motivated behavior) for the case of climate information, including parameters for anxiety, environmental awareness, climate scepticism and pro-environmental behavior intention.
Agents receive external information according to threat-level and information frequency. The population dynamic is based on the learning from that information as well as social contagion mechanisms through a scale-free network topology.
The model uses Netlogo 6.2 and the network extension.
…
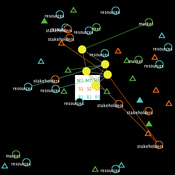
The S-uFUNK Model
Davide Secchi | Published Friday, March 17, 2023This version 2.1.0 of the uFunk model is about setting a business strategy (the S in the name) for an organization. A team of managers (or executives) meet and discuss various options on the strategy for the firm. There are three aspects that they have to agree on to set the strategic positioning of the organization.
The discussion is on market, stakeholders, and resources. The team (it could be a business strategy task force) considers various aspects of these three elements. The resources they use to develop the discussion can come from a traditional approach to strategy or from non-traditional means (e.g., so-called serious play, creativity and imagination techniques).
The S-uFunk 2.1.0 Model wants to understand to which extent cognitive means triggered by traditional and non-traditional resources affect the making of the strategy process.
World of Cows - Exploring land-use policies for a dairy-farm world (teaching modeling complex human-environment systems)
Maria Haensel Thomas Michael Schmitt Jakob Bogenreuther | Published Wednesday, January 11, 2023In the “World of Cows”, dairy farmers run their farms and interact with each other, the surrounding agricultural landscape, and the economic and political framework. The model serves as an exemplary case of an interdependent human-environment system.
With the model, users can analyze the influence of policies and markets on land use decisions of dairy farms. The land use decisions taken by farms determine the delivered ecosystem services on the landscape level. Users can choose a combination of five policy options and how strongly market prices fluctuate. Ideally, the choice of policy options fulfills the following three “political goals” 1) dairy farming stays economically viable, 2) the provision of ecosystem services is secured, and 3) government spending on subsidies is as low as possible.
The model has been designed for students to practice agent-based modeling and analyze the impacts of land use policies.
Evolutionary Model of Subculture Choice
Diogo Alves | Published Monday, December 19, 2022This is an original model of (sub)culture diffusion.
It features a set of agents (dubbed “partygoers”) organized initially in clusters, having properties such as age and a chromosome of opinions about 6 different topics. The partygoers interact with a set of cultures (also having a set of opinions subsuming those of its members), in the sense of refractory or unhappy members of each setting about to find a new culture and trading information encoded in the genetic string (originally encoded as -1, 0, and 1, resp. a negative, neutral, and positive opinion about each of the 6 traits/aspects, e.g. the use of recreational drugs). There are 5 subcultures that both influence (through the aforementioned genetic operations of mutation and recombination of chromosomes simulating exchange of opinions) and are influenced by its members (since a group is a weighted average of the opinions and actions of its constituents). The objective of this feedback loop is to investigate under which conditions certain subculture sizes emerge, but the model is open to many other kinds of explorations as well.

Peer reviewed Share: bottom-up disaster information management
Vittorio Nespeca Tina Comes Frances Brazier | Published Monday, December 05, 2022This model is intended to study the way information is collectively managed (i.e. shared, collected, processed, and stored) in a system and how it performs during a crisis or disaster. Performance is assessed in terms of the system’s ability to provide the information needed to the actors who need it when they need it. There are two main types of actors in the simulation, namely communities and professional responders. Their ability to exchange information is crucial to improve the system’s performance as each of them has direct access to only part of the information they need.
In a nutshell, the following occurs during a simulation. Due to a disaster, a series of randomly occurring disruptive events takes place. The actors in the simulation need to keep track of such events. Specifically, each event generates information needs for the different actors, which increases the information gaps (i.e. the “piles” of unaddressed information needs). In order to reduce the information gaps, the actors need to “discover” the pieces of information they need. The desired behavior or performance of the system is to keep the information gaps as low as possible, which is to address as many information needs as possible as they occur.

Peer reviewed A Computational Simulation for Task Allocation Influencing Performance in the Team System
Shaoni Wang | Published Friday, November 11, 2022 | Last modified Thursday, April 06, 2023This model system aims to simulate the whole process of task allocation, task execution and evaluation in the team system through a feasible method. On the basis of Complex Adaptive Systems (CAS) theory and Agent-based Modelling (ABM) technologies and tools, this simulation system attempts to abstract real-world teams into MAS models. The author designs various task allocation strategies according to different perspectives, and the interaction among members is concerned during the task-performing process. Additionally, knowledge can be acquired by such an interaction process if members encounter tasks they cannot handle directly. An artificial computational team is constructed through ABM in this simulation system, to replace real teams and carry out computational experiments. In all, this model system has great potential for studying team dynamics, and model explorers are encouraged to expand on this to develop richer models for research.

The purpose of the study is to unpack and explore a potentially beneficial role of sharing metacognitive information within a group when making repeated decisions about common pool resource (CPR) use.
We explore the explanatory power of sharing metacognition by varying (a) the individual errors in judgement (myside-bias); (b) the ways of reaching a collective judgement (metacognition-dependent), (c) individual knowledge updating (metacognition- dependent) and d) the decision making context.
The model (AgentEx-Meta) represents an extension to an existing and validated model reflecting behavioural CPR laboratory experiments (Schill, Lindahl & Crépin, 2015; Lindahl, Crépin & Schill, 2016). AgentEx-Meta allows us to systematically vary the extent to which metacognitive information is available to agents, and to explore the boundary conditions of group benefits of metacognitive information.
Perspectives on the Information-Based Economy
Vladimir Gazda Jana Zausinova Marcel Volosin | Published Monday, October 24, 2022This is the agent-based model of information market evolution. It simulates the influences of the transition from material to electronic carriers of information, which is modelled by the falling price of variable production factor. It demonstrates that due to zero marginal production costs, the competition increases, the market becomes unstable, and experience various phases of evolution leading to market monopolization.
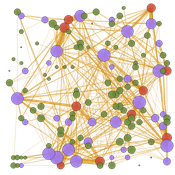
Peer reviewed TRANSOPE: a multi-agent model to simulate outsourcing networks in road freight transport.
Aitor Salas-Peña Blanca Rosa Cases Gutiérrez | Published Friday, October 21, 2022A road freight transport (RFT) operation involves the participation of several types of companies in its execution. The TRANSOPE model simulates the subcontracting process between 3 types of companies: Freight Forwarders (FF), Transport Companies (TC) and self-employed carriers (CA). These companies (agents) form transport outsourcing chains (TOCs) by making decisions based on supplier selection criteria and transaction acceptance criteria. Through their participation in TOCs, companies are able to learn and exchange information, so that knowledge becomes another important factor in new collaborations. The model can replicate multiple subcontracting situations at a local and regional geographic level.
The succession of n operations over d days provides two types of results: 1) Social Complex Networks, and 2) Spatial knowledge accumulation environments. The combination of these results is used to identify the emergence of new logistics clusters. The types of actors involved as well as the variables and parameters used have their justification in a survey of transport experts and in the existing literature on the subject.
As a result of a preferential selection process, the distribution of activity among agents shows to be highly uneven. The cumulative network resulting from the self-organisation of the system suggests a structure similar to scale-free networks (Albert & Barabási, 2001). In this sense, new agents join the network according to the needs of the market. Similarly, the network of preferential relationships persists over time. Here, knowledge transfer plays a key role in the assignment of central connector roles, whose participation in the outsourcing network is even more decisive in situations of scarcity of transport contracts.
Agent-based simulation of discussion processes in risk workshops with quantitative skepticism
Matthias Meyer Clemens Harten Lucia Bellora-Bienengräber | Published Sunday, August 14, 2022The model measures drivers of effectiveness of risk assessments in risk workshops where a calculative culture of quantitative skepticism is present. We model the limits to information transfer, incomplete discussions, group characteristics, and interaction patterns and investigate their effect on risk assessment in risk workshops, in order to contrast results to a previous model focused on a calculative culture of quantitative enthusiasm.
The model simulates a discussion in the context of a risk workshop with 9 participants. The participants use constraint satisfaction networks to assess a given risk individually and as a group.
Displaying 10 of 175 results information clear search