About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 451 results agent based model clear search
An agent-based model of cultural change for a low-carbon transition
Daniel Torren-Peraire | Published Friday, November 10, 2023An ABM of changes in individuals’ lifestyles which considers their
evolving behavioural choices. Individuals have a set of environmental behavioural traits that spread through a fixed Watts–Strogatz graph via social interactions with their neighbours. These exchanges are mediated by transmission biases informing from whom an individual learns and
how much attention is paid. The influence of individuals on each other is a function of their similarity in environmental identity, where we represent environmental identity computationally by aggregating past agent attitudes towards multiple environmentally related behaviours. To perform a behaviour, agents must both have
a sufficiently positive attitude toward a behaviour and overcome a corresponding threshold. This threshold
structure, where the desire to perform a behaviour does not equal its enactment, allows for a lack of coherence
between attitudes and actual emissions. This leads to a disconnect between what people believe and what
…
Peer reviewed ABM Overtourism Santa Marta
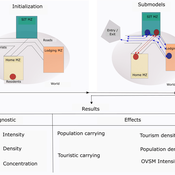
Janwar Moreno | Published Monday, October 23, 2023This model presents the simulation model of a city in the context of overtourism. The study area is the city of Santa Marta in Colombia. The purpose is to illustrate the spatial and temporal distribution of population and tourists in the city. The simulation analyzes emerging patterns that result from the interaction between critical components in the touristic urban system: residents, urban space, touristic sites, and tourists. The model is an Agent-Based Model (ABM) with the GAMA software. Also, it used public input data from statistical centers, geographical information systems, tourist websites, reports, and academic articles. The ABM includes assessing some measures used to address overtourism. This is a field of research with a low level of analysis for destinations with overtourism, but the ABM model allows it. The results indicate that the city has a high risk of overtourism, with spatial and temporal differences in the population distribution, and it illustrates the effects of two management measures of the phenomenon on different scales. Another interesting result is the proposed tourism intensity indicator (OVsm), taking into account that the tourism intensity indicators used by the literature on overtourism have an overestimation of tourism pressures.

Peer reviewed HUMLAND: HUMan impact on LANDscapes agent-based model
Fulco Scherjon Anastasia Nikulina Anhelina Zapolska Maria Antonia Serge Marco Davoli Dave van Wees Katharine MacDonald | Published Monday, October 16, 2023The HUMan impact on LANDscapes (HUMLAND) model has been developed to track and quantify the intensity of different impacts on landscapes at the continental level. This agent-based model focuses on determining the most influential factors in the transformation of interglacial vegetation with a specific emphasis on burning organized by hunter-gatherers. HUMLAND integrates various spatial datasets as input and target for the agent-based model results. Additionally, the simulation incorporates recently obtained continental-scale estimations of fire return intervals and the speed of vegetation regrowth. The obtained results include maps of possible scenarios of modified landscapes in the past and quantification of the impact of each agent, including climate, humans, megafauna, and natural fires.
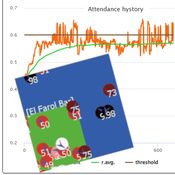
Peer reviewed Flibs’NFarol: Self-Organized Efficiency and Fairness Emergence in an Evolutive Game
Cosimo Leuci | Published Thursday, October 12, 2023According to the philosopher of science K. Popper “All life is problem solving”. Genetic algorithms aim to leverage Darwinian selection, a fundamental mechanism of biological evolution, so as to tackle various engineering challenges.
Flibs’NFarol is an Agent Based Model that embodies a genetic algorithm applied to the inherently ill-defined “El Farol Bar” problem. Within this context, a group of agents operates under bounded rationality conditions, giving rise to processes of self-organization involving, in the first place, efficiency in the exploitation of available resources. Over time, the attention of scholars has shifted to equity in resource distribution, as well. Nowadays, the problem is recognized as paradigmatic within studies of complex evolutionary systems.
Flibs’NFarol provides a platform to explore and evaluate factors influencing self-organized efficiency and fairness. The model represents agents as finite automata, known as “flibs,” and offers flexibility in modifying the number of internal flibs states, which directly affects their behaviour patterns and, ultimately, the diversity within populations and the complexity of the system.

Peer reviewed A Bayesian Nash Equilibrium (BNE)-informed ABM for pedestrian evacuation in different constricted spaces
Jiaqi Ge Yiyu Wang Alexis Comber | Published Wednesday, October 11, 2023This BNE-informed ABM ultimately aims to provide a more realistic description of complicated pedestrian behaviours especially in high-density and life-threatening situations. Bayesian Nash Equilibrium (BNE) was adopted to reproduce interactive decision-making process among rational and game-playing agents. The implementations of 3 behavioural models, which are Shortest Route (SR) model, Random Follow (RF) model, and BNE model, make it possible to simulate emergent patterns of pedestrian behaviours (e.g. herding and self-organised queuing behaviours, etc.) in emergency situations.
According to the common features of previous mass trampling accidents, a series of simulation experiments were performed in space with 3 types of barriers, which are Horizontal Corridors, Vertical Corridors, and Random Squares, standing for corridors, bottlenecks and intersections respectively, to investigate emergent behaviours of evacuees in varied constricted spatial environments. The output of this ABM has been available at https://data.mendeley.com/datasets/9v4byyvgxh/1.
Gender Disparity in COVID-19’s Impact on Academic Careers: An Agent-Based Model
S.R. Aurora (a.k.a. Mai P. Trinh) Chantal van Esch | Published Tuesday, September 26, 2023Prior to COVID-19, female academics accounted for 45% of assistant professors, 37% of associate professors, and 21% of full professors in business schools (Morgan et al., 2021). The pandemic arguably widened this gender gap, but little systemic data exists to quantify it. Our study set out to answer two questions: (1) How much will the COVID-19 pandemic have impacted the gender gap in U.S. business school tenured and tenure-track faculty? and (2) How much will institutional policies designed to help faculty members during the pandemic have affected this gender gap? We used agent-based modeling coupled with archival data to develop a simulation of the tenure process in business schools in the U.S. and tested how institutional interventions would affect this gender gap. Our simulations demonstrated that the gender gap in U.S. business schools was on track to close but would need further interventions to reach equality (50% females). In the long-term picture, COVID-19 had a small impact on the gender gap, as did dependent care assistance and tenure extensions (unless only women received tenure extensions). Changing performance evaluation methods to better value teaching and service activities and increasing the proportion of female new hires would help close the gender gap faster.
An Agent-Based Model of an Insurance Market driven by Supply and Demand with Imperfectly Estimated Strategies in C#
Rei England | Published Sunday, September 24, 2023This is a simulation of an insurance market where the premium moves according to the balance between supply and demand. In this model, insurers set their supply with the aim of maximising their expected utility gain while operating under imperfect information about both customer demand and underlying risk distributions.
There are seven types of insurer strategies. One type follows a rational strategy within the bounds of imperfect information. The other six types also seek to maximise their utility gain, but base their market expectations on a chartist strategy. Under this strategy, market premium is extrapolated from trends based on past insurance prices. This is subdivided according to whether the insurer is trend following or a contrarian (counter-trend), and further depending on whether the trend is estimated from short-term, medium-term, or long-term data.
Customers are modelled as a whole and allocated between insurers according to available supply. Customer demand is calculated according to a logit choice model based on the expected utility gain of purchasing insurance for an average customer versus the expected utility gain of non-purchase.
An Agent-Based Model of an Insurer's Estimated Capital Requirement in a Simple Insurance Market with Imperfect Information in C#
Rei England | Published Sunday, September 24, 2023This is an agent-based model of a simple insurance market with two types of agents: customers and insurers. Insurers set premium quotes for each customer according to an estimation of their underlying risk based on past claims data. Customers either renew existing contracts or else select the cheapest quote from a subset of insurers. Insurers then estimate their resulting capital requirement based on a 99.5% VaR of their aggregate loss distributions. These estimates demonstrate an under-estimation bias due to the winner’s curse effect.
An Agent-Based Model for Skilled Workers Migration
Hassan Bashiri | Published Thursday, September 21, 2023This documentation provides an overview and explanation of the NetLogo simulation code for modeling skilled workers’ migration in Iran. The simulation aims to explore the dynamics of skilled workers’ migration and their transition through various states, including training, employment, and immigration.
The flow of elite and talent migration, or “brain drain,” is a complex issue with far-reaching implications for developing countries. The decision to migrate is made due to various factors including economic opportunities, political stability, social factors and personal circumstances.
Measuring individual interests in the field of immigration is a complex task that requires careful consideration of various factors. The agent-based model is a useful tool for understanding the complex factors that are involved in talent migration. By considering the various social, economic, and personal factors that influence migration decisions, policymakers can provide more effective strategies to retain skilled and talented labor and promote sustainable growth in developing countries. One of the main challenges in studying the flow of elite migration is the complexity of the decision-making process and a set of factors that lead to migration decisions. Agent-based modeling is a useful tool for understanding how individual decisions can lead to large-scale migration patterns.
The Targeted Subsidies Plan Model
Hassan Bashiri | Published Thursday, September 21, 2023The targeted subsidies plan model is based on the economic concept of targeted subsidies.
The targeted subsidies plan model simulates the distribution of subsidies among households in a community over several years. The model assumes that the government allocates a fixed amount of money each year for the purpose of distributing cash subsidies to eligible households. The eligible households are identified by dividing families into 10 groups based on their income, property, and wealth. The subsidy is distributed to the first four groups, with the first group receiving the highest subsidy amount. The model simulates the impact of the subsidy distribution process on the income and property of households in the community over time.
The model simulates a community of 230 households, each with a household income and wealth that follows a power-law distribution. The number of household members is modeled by a normal distribution. The model allocates a fixed amount of money each year for the purpose of distributing cash subsidies among eligible households. The eligible households are identified by dividing families into 10 groups based on their income, property, and wealth. The subsidy is distributed to the first four groups, with the first group receiving the highest subsidy amount.
The model runs for a period of 10 years, with the subsidy distribution process occurring every month. The subsidy received by each household is assumed to be spent, and a small portion may be saved and added to the household’s property. At the end of each year, the grouping of households based on income and assets is redone, and a number of families may be moved from one group to another based on changes in their income and property.
…
Displaying 10 of 451 results agent based model clear search