Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1138 results for "Clint A Penick" clear search
Opinions on contested energy infrastructures
Annalisa Stefanelli | Published Thursday, June 23, 2016This ABM simulates opinions on a topic (originally contested infrastructures) through the interactions between paired agents and based on the sociopsychological assumptions of social judgment theory (SJT; Sherif & Hovland, 1961).
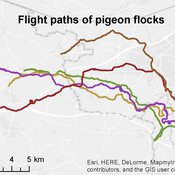
Homing pigeon model
Gudrun Wallentin | Published Saturday, October 29, 2016This model represents the flight paths of a flock of homing pigeons according to their flocking-, orientation- and leadership behaviour.
The Bronze Age Collapse model (BACO model)
Marco Vidal-Cordasco | Published Friday, October 09, 2020The Bronze Age Collapse model (BACO model) is written using free NetLogo software v.6.0.3. The purpose of using the BACO model is to develop a tool to identify and analyse the main factors that made the Late Bronze Age and Early Iron Age socio-ecological system resilient or vulnerable in the face of the environmental aridity recorded in the Aegean. The model explores the relationship between dependent and independent variables. Independent variables are: a) inter-annual rainfall variability for the Late Bronze Age and Early Iron Age in the eastern Mediterranean, b) intensity of raiding, c) percentage of marine, agricultural and other calorie sources included in the diet, d) soil erosion processes, e) farming assets, and d) storage capacity. Dependent variables are: a) human pressure for land, b) settlement patterns, c) number of commercial exchanges, d) demographic behaviour, and e) number of migrations.

Local extinctions, connectedness, and cultural evolution in structured populations
Luke Premo | Published Tuesday, May 25, 2021This model is designed to address the following research question: How does the amount and topology of intergroup cultural transmission modulate the effect of local group extinction on selectively neutral cultural diversity in a geographically structured population? The experimental design varies group extinction rate, the amount of intergroup cultural transmission, and the topology of intergroup cultural transmission while measuring the effects of local group extinction on long-term cultural change and regional cultural differentiation in a constant-size, spatially structured population. The results show that for most of the intergroup social network topologies tested here, increasing the amount of intergroup cultural transmission (similar to increasing gene flow in a genetic model) erases the negative effect of local group extinction on selectively neutral cultural diversity. The stochastic (i.e., preference attachment) network seems to stand out as an exception.
Wildlife-Human Interactions in Shared Landscapes (WHISL)
Nicholas Magliocca Neil Carter Andres Baeza-Castro | Published Friday, May 22, 2020This model simulates a group of farmers that have encounters with individuals of a wildlife population. Each farmer owns a set of cells that represent their farm. Each farmer must decide what cells inside their farm will be used to produce an agricultural good that is self in an external market at a given price. The farmer must decide to protect the farm from potential encounters with individuals of the wildlife population. This decision in the model is called “fencing”. Each time that a cell is fenced, the chances of a wildlife individual to move to that cell is reduced. Each encounter reduces the productive outcome obtained of the affected cell. Farmers, therefore, can reduce the risk of encounters by exclusion. The decision of excluding wildlife is made considering the perception of risk of encounters. In the model, the perception of risk is subjective, as it depends on past encounters and on the perception of risk from other farmers in the community. The community of farmers passes information about this risk perception through a social network. The user (observer) of the model can control the importance of the social network on the individual perception of risk.
RecovUS: An Agent-Based Model of Post-Disaster Household Recovery
Saeed Moradi | Published Thursday, July 30, 2020The purpose of this model is to explain the post-disaster recovery of households residing in their own single-family homes and to predict households’ recovery decisions from drivers of recovery. Herein, a household’s recovery decision is repair/reconstruction of its damaged house to the pre-disaster condition, waiting without repair/reconstruction, or selling the house (and relocating). Recovery drivers include financial conditions and functionality of the community that is most important to a household. Financial conditions are evaluated by two categories of variables: costs and resources. Costs include repair/reconstruction costs and rent of another property when the primary house is uninhabitable. Resources comprise the money required to cover the costs of repair/reconstruction and to pay the rent (if required). The repair/reconstruction resources include settlement from the National Flood Insurance (NFI), Housing Assistance provided by the Federal Emergency Management Agency (FEMA-HA), disaster loan offered by the Small Business Administration (SBA loan), a share of household liquid assets, and Community Development Block Grant Disaster Recovery (CDBG-DR) fund provided by the Department of Housing and Urban Development (HUD). Further, household income determines the amount of rent that it can afford. Community conditions are assessed for each household based on the restoration of specific anchors. ASNA indexes (Nejat, Moradi, & Ghosh 2019) are used to identify the category of community anchors that is important to a recovery decision of each household. Accordingly, households are indexed into three classes for each of which recovery of infrastructure, neighbors, or community assets matters most. Further, among similar anchors, those anchors are important to a household that are located in its perceived neighborhood area (Moradi, Nejat, Hu, & Ghosh 2020).
AncientS-ABM: Agent-Based Modeling of Past Societies Social Organization
Angelos Chliaoutakis | Published Thursday, April 09, 2020AncientS-ABM is an agent-based model for simulating and evaluating the potential social organization of an artificial past society, configured by available archaeological data. Unlike most existing agent-based models used in archaeology, our ABM framework includes completely autonomous, utility-based agents. It also incorporates different social organization paradigms, different decision-making processes, and also different cultivation technologies used in ancient societies. Equipped with such paradigms, the model allows us to explore the transition from a simple to a more complex society by focusing on the historical social dynamics; and to assess the influence of social organization on agents’ population growth, agent community numbers, sizes and distribution.
AncientS-ABM also blends ideas from evolutionary game theory with multi-agent systems’ self-organization. We model the evolution of social behaviours in a population of strategically interacting agents in repeated games where they exchange resources (utility) with others. The results of the games contribute to both the continuous re-organization of the social structure, and the progressive adoption of the most successful agent strategies. Agent population is not fixed, but fluctuates over time, while agents in stage games also receive non-static payoffs, in contrast to most games studied in the literature. To tackle this, we defined a novel formulation of the evolutionary dynamics via assessing agents’ rather than strategies’ fitness.
As a case study, we employ AncientS-ABM to evaluate the impact of the implemented social organization paradigms on an artificial Bronze Age “Minoan” society, located at different geographical parts of the island of Crete, Greece. Model parameter choices are based on archaeological evidence and studies, but are not biased towards any specific assumption. Results over a number of different simulation scenarios demonstrate better sustainability for settlements consisting of and adopting a socio-economic organization model based on self-organization, where a “heterarchical” social structure emerges. Results also demonstrate that successful agent societies adopt an evolutionary approach where cooperation is an emergent strategic behaviour. In simulation scenarios where the natural disaster module was enabled, we observe noticeable changes in the settlements’ distribution, relating to significantly higher migration rates immediately after the modeled Theran eruption. In addition, the initially cooperative behaviour is transformed to a non-cooperative one, thus providing support for archaeological theories suggesting that the volcanic eruption led to a clear breakdown of the Minoan socio-economic system.
…

The PARSO_demo Model
Davide Secchi | Published Tuesday, November 05, 2019This model explores different aspects of the formation of urban neighbourhoods where residents believe in values distant from those dominant in society. Or, at least, this is what the Danish government beliefs when they discuss their politics about parallel societies. This simulation is set to understand (a) whether these alternative values areas form and what determines their formation, (b) if they are linked to low or no income residents, and (c) what happens if they disappear from the map. All these three points are part of the Danish government policy. This agent-based model is set to understand the boundaries and effects of this policy.
Exploring Urban Shrinkage
Andrew Crooks | Published Thursday, March 19, 2020While the world’s total urban population continues to grow, this growth is not equal. Some cities are declining, resulting in urban shrinkage which is now a global phenomenon. Many problems emerge due to urban shrinkage including population loss, economic depression, vacant properties and the contraction of housing markets. To explore this issue, this paper presents an agent-based model stylized on spatially explicit data of Detroit Tri-county area, an area witnessing urban shrinkage. Specifically, the model examines how micro-level housing trades impact urban shrinkage by capturing interactions between sellers and buyers within different sub-housing markets. The stylized model results highlight not only how we can simulate housing transactions but the aggregate market conditions relating to urban shrinkage (i.e., the contraction of housing markets). To this end, the paper demonstrates the potential of simulation to explore urban shrinkage and potentially offers a means to test polices to alleviate this issue.

Peer reviewed DogPopDy: ABM for ABC planning
Aniruddha Belsare Abi Vanak | Published Saturday, August 01, 2020An agent-based model designed as a tool to assess and plan free-ranging dog population management programs that implement Animal Birth Control (ABC). The time, effort, financial resources and conditions needed to successfully control dog populations and achieve rabies control can be determined by performing virtual experiments using DogPopDy.
Displaying 10 of 1138 results for "Clint A Penick" clear search