Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 44 results replication clear search
ZIP-Level Housing Supply Elasticity and Crash Dynamics: A GIS-Based Agent-Based Model of the Washington DC and Northern Virginia Metro Region
Mansoor Abdul Bari | Published Saturday, August 01, 2026 | Last modified Sunday, August 02, 2026This model tests whether local housing supply elasticity governs crash severity inside a single metropolitan housing market. Saiz (2010) established that across US metros, regions constrained by geography and regulation experience deeper boom-bust cycles than flexible ones. That finding is routinely applied downward to neighborhoods and ZIP codes as though the mechanism scaled without qualification.
The empirical record for the Washington DC and Northern Virginia region says it does not. Across 84 ZIP codes, measured supply elasticity ranges from 0.35 to 4.95 with a median of 1.21. The worst single-year price decline between 2007 and 2012 averaged 9.6 percent in constrained ZIP codes and 9.0 percent in flexible ones, a gap that cannot be distinguished from noise. Wide variation in the proposed cause, no meaningful separation in the proposed effect.
The model embeds households, houses and a metro-wide credit condition in the real ZIP geography of the region using three GIS layers and an empirical price panel. Local elasticity governs construction, exactly as theory predicts. Prices are driven by a shared macro drift schedule and, under the credit-amplified mode, by a leverage cycle with a financial accelerator and a deviation penalty. The design question is whether those shared forces are sufficient to override local supply differences at the sub-metropolitan scale.
…
MOSAIC: Mission-Oriented Self-Organization through Auctions, Incentives, and Coalitions
Katherin Molina Lorena Holguin | Published Friday, July 31, 2026MOSAIC is an agent-based NetLogo model of decentralized mission coordination among heterogeneous robots operating under partial observability, limited energy, spatially variable risk, dynamic communication, and individual and cooperative task requirements. Robots discover tasks locally, exchange task information through temporary communication links, submit capability-, energy-, deadline-, and risk-aware bids, compete for individual contracts, and form temporary coalitions for cooperative tasks.
The model integrates decentralized auctions, greedy capability-based coalition formation, contract release and reassignment, four reward regimes, reputation, adaptive bidding strategies, failure traceability, and mission-, network-, information-, inequality-, and coalition-level metrics. It operates without a centralized mission planner or global combinatorial assignment solver.
Seven paired-seed BehaviorSpace experiments comprising 690 official simulation runs evaluate baseline mission viability, reward regimes, communication structure, capability heterogeneity, cooperative-task demand, reputation and adaptive strategies, and mission-incentive strength. The results indicate that structural coordination capacity—particularly information reach, capability compatibility, and feasible coalition construction—has a stronger effect on mission completion than increasing incentive intensity within the tested architecture and parameter ranges.
…
An Agent-Based Model of Saving under Quasi-Hyperbolic Discounting on a Social Network.
Jose Alejandro Velazquez Monzon | Published Wednesday, June 24, 2026An agent-based model of saving and dissaving behaviour under quasi-hyperbolic (β–δ) discounting. Building on the individual decision problem of Cao and Werning (2018), the model embeds present-biased agents in a Watts–Strogatz small-world network and adds three configurable mechanisms of social influence — information diffusion, peer comparison, and social-norm conformity — across five heterogeneous behavioural profiles (Planners, Moderates, Procrastinators, Inverse Procrastinators, and Impulsive agents).
Each profile’s saving policy is approximated by value-function iteration over a discretised wealth grid; the solved policies are cached and applied as agents interact over their network neighbourhoods. The model tests whether each social mechanism can alter the saving and wealth trajectories that present-biased agents would otherwise follow in isolation, and characterises the direction and size of each effect on median wealth, wealth inequality (Gini), and the incidence of severely depleted agents.
The deposit includes the core model (Model.py), an analysis and visualisation pipeline (analyze_results.py), a standalone ODD description (ODD.md), and pinned dependencies.
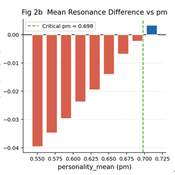
Zensei Wago: A Wealth-Integrated Social Capital Model
hiiki | Published Friday, May 15, 2026Interest-based compound economies generate monotonically increasing wealth inequality through multiplicative accumulation dynamics, yet the conditions under which gift-based reciprocal exchange outperforms such systems in collective well-being remain unquantified. We present Zensei Wago (全生和合), a seven-layer agent-based model comparing a Gift Resource Circulation (GRC) economy with a Compound Interest Circulation (CIC) economy under identical initial conditions. Across N = 5000 Monte Carlo replications (T = 700 ticks, N = 100 agents), GRC produced significantly higher collective resonance than CIC (p < 0.001, Cohen’s d = +0.171), above a critical prosocial threshold pm ≈ 0.698. Cohen’s d grows monotonically with duration — d = +1.943 at T = 1500 and d = +4.126 at T = 3000 — driven primarily by structural collapse of CIC resonance as inequality exceeds a critical Gini threshold (G > 0.333), while GRC resonance remains stable. The gift mechanism further decouples collective well-being from distributional outcomes, generating resonance through relational quality rather than material redistribution. Network topology analysis across seven configurations — combining a Watts-Strogatz rewiring sweep and a T = 1500 longitudinal replication — reveals that ring topology maximises GRC advantage (d = +1.17), that most topology-dependent reversals are transient (sparse and small-world both transition to significantly positive by T = 1500), and that a critical rewiring threshold of p ≈ 0.10–0.20 separates GRC-advantaged from GRC-disadvantaged network configurations. Scale-free networks remain persistently adverse (d = -7.24*), requiring structural redesign for gift-economy viability.
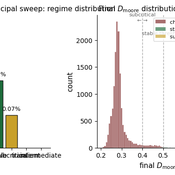
The Informational Assumptions of Schelling Segregation: An Agent-Based Decomposition of Cue Inference, Cultural Schemas, and Residential Sorting
Eric Gladstone | Published Wednesday, May 13, 2026This computational model accompanies the article “The Informational Assumptions of Schelling Segregation: An Agent-Based Decomposition of Cue Inference, Cultural Schemas, and Residential Sorting.” It implements an agent-based model in which agents infer latent neighborhood-type classes from noisy non-demographic cues through schema-specific diagnostic mappings, update beliefs, and relocate when satisfaction on a preferred latent class falls below a threshold.
The model serves as a mechanism-isolation device for studying the informational architecture underlying Schelling-style residential sorting. It includes the principal sweep configuration (14,400 runs across a seven-parameter grid), a disagreement-metric sub-sweep with permutation-minimized Jensen-Shannon divergence recorded natively, controls (positive, negative, and frozen-belief), a paired-seed cue-channel perturbation experiment, and selected-cell sensitivity sweeps for cue persistence and home-biased mobility.
The full ODD protocol, parameter manifests, deterministic seed schedules, processed outputs, regenerable figure scripts, the verification test suite, and the satisfaction-mapping audit document are included. Every reported run is deterministic given a (config, seed) pair, and an included audit script verifies bit-for-bit replay on sampled runs.
Peer reviewed Kenya ITN Agent-Based Microsimulation (2003–2024)
Wooyoung Kim Hosang Shin | Published Saturday, April 18, 2026 | Last modified Tuesday, June 16, 2026An agent-based microsimulation of insecticide-treated net (ITN) distribution and adoption in Kenya (2003–2024), integrating the Theory of Planned Behaviour, Rogers diffusion, Weibull net decay, and a GPS-based two-layer social network. 8,561 household agents calibrated via Approximate Bayesian Computation to six DHS/MIS survey waves, achieving 2.42 pp mean absolute error on Kenya-level ownership. The analysis chain supports mechanism counterfactuals and policy experiments on equity outcomes of ITN distribution strategies.

Simulating Climate Stress and Social Instability: An Agent-Based Model of Ecosystem Degradation and Violence in Coastal Communities
Jacopo A. Baggio hurtado-valdivieso | Published Sunday, April 12, 2026This model is an agent-based simulation designed to explore how climate-induced environmental degradation can contribute to the emergence of social violence in coastal communities that depend heavily on ecosystem services for their livelihoods. The model represents a coupled social–ecological system in which environmental shocks—such as sea level rise and marine ecosystem decline—affect local economic conditions, food security, and community stability.
Agents in the model represent individuals whose livelihoods depend on coastal ecosystems. Environmental degradation reduces ecosystem productivity and increases economic hardship, which can lead to the formation of grievances among agents. The model incorporates behavioral thresholds that determine how individuals respond to hardship and perceived injustice. Under certain conditions—particularly when institutional capacity and law enforcement effectiveness are limited—these grievances may escalate into violent behavior.
The simulation allows users to explore how different climate scenarios, levels of ecosystem degradation, livelihood dependence, and institutional responses influence the probability of social instability and violence. By modeling the interactions between environmental stress, socio-economic vulnerability, and governance capacity, the model provides a computational framework for examining potential pathways linking climate change and conflict in coastal social–ecological systems.
…
Agent-Based Model of Transhumant Decision-Making Processes in Senegal
Cheick Amed Diloma Gabriel TRAORE Etienne DELAY Alassane Bah Djibril Diop | Published Wednesday, July 03, 2024Sahelian transhumance is a type of socio-economic and environmental pastoral mobility. It involves the movement of herds from their terroir of origin (i.e., their original pastures) to one or more host terroirs, followed by a return to the terroir of origin. According to certain pastoralists, the mobility of herds is planned to prevent environmental degradation, given the continuous dependence of these herds on their environment. However, these herds emit Greenhouse Gases (GHGs) in the spaces they traverse. Given that GHGs contribute to global warming, our long-term objective is to quantify the GHGs emitted by Sahelian herds. The determination of these herds’ GHG emissions requires: (1) the artificial replication of the transhumance, and (2) precise knowledge of the space used during their transhumance.
This article presents the design of an artificial replication of the transhumance through an agent-based model named MSTRANS. MSTRANS determines the space used by transhumant herds, based on the decision-making process of Sahelian transhumants.
MSTRANS integrates a constrained multi-objective optimization problem and algorithms into an agent-based model. The constrained multi-objective optimization problem encapsulates the rationality and adaptability of pastoral strategies. Interactions between a transhumant and its socio-economic network are modeled using algorithms, diffusion processes, and within the multi-objective optimization problem. The dynamics of pastoral resources are formalized at various spatio-temporal scales using equations that are integrated into the algorithms.
The results of MSTRANS are validated using GPS data collected from transhumant herds in Senegal. MSTRANS results highlight the relevance of integrated models and constrained multi-objective optimization for modeling and monitoring the movements of transhumant herds in the Sahel. Now specialists in calculating greenhouse gas emissions have a reproducible and reusable tool for determining the space occupied by transhumant herds in a Sahelian country. In addition, decision-makers, pastoralists, veterinarians and traders have a reproducible and reusable tool to help them make environmental and socio-economic decisions.
A replication and extension of the Taylor's Simulation Model of Insurance Market Dynamics in C#
Rei England | Published Sunday, September 24, 2023A simple model is constructed using C# in order to to capture key features of market dynamics, while also producing reasonable results for the individual insurers. A replication of Taylor’s model is also constructed in order to compare results with the new premium setting mechanism. To enable the comparison of the two premium mechanisms, the rest of the model set-up is maintained as in the Taylor model. As in the Taylor example, homogeneous customers represented as a total market exposure which is allocated amongst the insurers.
In each time period, the model undergoes the following steps:
1. Insurers set competitive premiums per exposure unit
2. Losses are generated based on each insurer’s share of the market exposure
3. Accounting results are calculated for each insurer
…

Peer reviewed SequiaBasalto model
Marco Janssen Irene Perez Ibarra Pierre Bommel Diego J. Soler-Navarro Alicia Tenza Peral Francisco Dieguez Cameroni | Published Friday, May 26, 2023This is a replication of the SequiaBasalto model, originally built in Cormas by Dieguez Cameroni et al. (2012, 2014, Bommel et al. 2014 and Morales et al. 2015). The model aimed to test various adaptations of livestock producers to the drought phenomenon provoked by climate change. For that purpose, it simulates the behavior of one livestock farm in the Basaltic Region of Uruguay. The model incorporates the price of livestock, fodder and paddocks, as well as the growth of grass as a function of climate and seasons (environmental submodel), the life cycle of animals feeding on the pasture (livestock submodel), and the different strategies used by farmers to manage their livestock (management submodel). The purpose of the model is to analyze to what degree the common management practices used by farmers (i.e., proactive and reactive) to cope with seasonal and interannual climate variations allow to maintain a sustainable livestock production without depleting the natural resources (i.e., pasture). Here, we replicate the environmental and livestock submodel using NetLogo.
One year is 368 days. Seasons change every 92 days. Each day begins with the growth of grass as a function of climate and season. This is followed by updating the live weight of cows according to the grass height of their patch, and grass consumption, which is determined based on the updated live weight. After consumption, cows grow and reproduce, and a new grass height is calculated. Cows then move to the patch with less cows and with the highest grass height. This updated grass height value will be the initial grass height for the next day.
Displaying 10 of 44 results replication clear search