About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 10 results for "Kevin Chapuis" clear search
Managing ecological disturbances: Learning and the structure of social-ecological networks
Jacopo A. Baggio Vicken Hillis | Published Friday, March 03, 2017 | Last modified Thursday, August 02, 2018The aim of this model is to explore and understand the factors driving adoption of treatment strategies for ecological disturbances, considering payoff signals, learning strategies and social-ecological network structure
CPNorm
Ruth Meyer | Published Sunday, June 04, 2017 | Last modified Tuesday, June 13, 2017CPNorm is a model of a community of harvesters using a common pool resource where adhering to the optimal extraction level has become a social norm. The model can be used to explore the robustness of norm-driven cooperation in the commons.

Peer reviewed Social Consequences of Past Compound Events - Laacher See Eruption
Kevin Su Brennen Bouwmeester | Published Monday, May 17, 2021Resilience of humans in the Upper Paleolithic could provide insights in how to defend against today’s environmental threats. Approximately 13,000 years ago, the Laacher See volcano located in present-day western Germany erupted cataclysmically. Archaeological evidence suggests that this is eruption – potentially against the background of a prolonged cold spell – led to considerable culture change, especially at some distance from the eruption (Riede, 2017). Spatially differentiated and ecologically mediated effects on contemporary social networks as well as social transmission effects mediated by demographic changes in the eruption’s wake have been proposed as factors that together may have led to, in particular, the loss of complex technologies such as the bow-and-arrow (Riede, 2014; Riede, 2009).
This model looks at the impact of the interaction between climate change trajectory and an extreme event, such as the Laacher See eruption, on the generational development of hunter-gatherer bands. Historic data is used to model the distribution and population dynamics of hunter-gatherer bands during these circumstances.

Maze with Q-Learning NetLogo extension
Kevin Kons Fernando Santos | Published Tuesday, December 10, 2019This is a re-implementation of a the NetLogo model Maze (ROOP, 2006).
This re-implementation makes use of the Q-Learning NetLogo Extension to implement the Q-Learning, which is done only with NetLogo native code in the original implementation.
Cliff Walking with Q-Learning NetLogo Extension
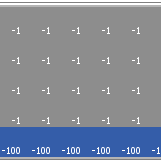
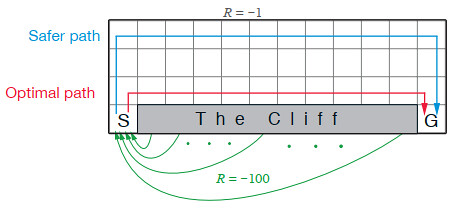
Kevin Kons Fernando Santos | Published Tuesday, December 10, 2019This model implements a classic scenario used in Reinforcement Learning problem, the “Cliff Walking Problem”. Consider the gridworld shown below (SUTTON; BARTO, 2018). This is a standard undiscounted, episodic task, with start and goal states, and the usual actions causing movement up, down, right, and left. Reward is -1 on all transitions except those into the region marked “The Cliff.” Stepping into this region incurs a reward of -100 and sends the agent instantly back to the start (SUTTON; BARTO, 2018).
The problem is solved in this model using the Q-Learning algorithm. The algorithm is implemented with the support of the NetLogo Q-Learning Extension
Emission Trading Impact On Power Generation Model
Emile Chappin | Published Friday, June 19, 2020Under the Kyoto Protocol, governments agreed on and accepted CO2 reduction targets in order to counter climate change. In Europe one of the main policy instruments to meet the agreed reduction targets is CO2 emission-trading (CET), which was implemented as of January 2005. In this system, companies active in specific sectors must be in the possession of CO2 emission rights to an amount equal to their CO2 emission. In Europe, electricity generation accounts for one-third of CO2 emissions. Since the power generation sector, has been liberalized, reregulated and privatized in the last decade, around Europe autonomous companies determine the sectors’ CO2 emission. Short-term they adjust their operation, long-term they decide on (dis)investment in power generation facilities and technology selection. An agent-based model is presented to elucidate the effect of CET on the decisions of power companies in an oligopolistic market. Simulations over an extensive scenario-space show that there CET does have an impact. A long-term portfolio shift towards less-CO2 intensive power generation is observed. However, the effect of CET is relatively small and materializes late. The absolute emissions from power generation rise under most scenarios. This corresponds to the dominant character of current capacity expansion planned in the Netherlands (50%) and in Germany (68%), where companies have announced many new coal based power plants. Coal is the most CO2 intensive option available and it seems surprising that even after the introduction of CET these capacity expansion plans indicate a preference for coal. Apparently in power generation the economic effect of CO2 emission-trading is not sufficient to outweigh the economic incentives to choose for coal.
Peer reviewed COMOKIT
Patrick Taillandier Alexis Drogoul Benoit Gaudou Kevin Chapuis Nghi Huyng Quang Doanh Nguyen Ngoc Arthur Brugière Pierre Larmande Marc Choisy Damien Philippon | Published Tuesday, May 26, 2020 | Last modified Wednesday, July 01, 2020In the face of the COVID-19 pandemic, public health authorities around the world have experimented, in a short period of time, with various combinations of interventions at different scales. However, as the pandemic continues to progress, there is a growing need for tools and methodologies to quickly analyze the impact of these interventions and answer concrete questions regarding their effectiveness, range and temporality.
COMOKIT, the COVID-19 modeling kit, is such a tool. It is a computer model that allows intervention strategies to be explored in silico before their possible implementation phase. It can take into account important dimensions of policy actions, such as the heterogeneity of individual responses or the spatial aspect of containment strategies.
In COMOKIT, built using the agent-based modeling and simulation platform GAMA, the profiles, activities and interactions of people, person-to-person and environmental transmissions, individual clinical statuses, public health policies and interventions are explicitly represented and they all serve as a basis for describing the dynamics of the epidemic in a detailed and realistic representation of space.
…
Ant Colony Optimization for infrastructure routing
Igor Nikolic Emile Chappin P W Heijnen | Published Wednesday, March 05, 2014 | Last modified Saturday, March 24, 2018The mode implements a variant of Ant Colony Optimization to explore routing on infrastructures through a landscape with forbidden zones, connecting multiple sinks to one source.
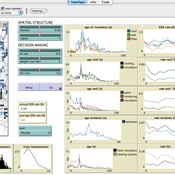
Exploring homeowners' insulation activity
Georg Holtz Emile Chappin Jonas Friege | Published Monday, June 01, 2015 | Last modified Monday, April 08, 2019We built an agent-based model to foster the understanding of homeowners’ insulation activity.

Animal territory formation (Reusable Building Block RBB)
Volker Grimm Stephanie Kramer-Schadt Robert Zakrzewski | Published Sunday, November 12, 2023This is a generic sub-model of animal territory formation. It is meant to be a reusable building block, but not in the plug-and-play sense, as amendments are likely to be needed depending on the species and region. The sub-model comprises a grid of cells, reprenting the landscape. Each cell has a “quality” value, which quantifies the amount of resources provided for a territory owner, for example a tiger. “Quality” could be prey density, shelter, or just space. Animals are located randomly in the landscape and add grid cells to their intial cell until the sum of the quality of all their cells meets their needs. If a potential new cell to be added is owned by another animal, competition takes place. The quality values are static, and the model does not include demography, i.e. mortality, mating, reproduction. Also, movement within a territory is not represented.