Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 81 results game clear search

Software for an agent-based game-theoretic model of the contact hypothesis of prejudice reduction, to accompany “Modeling Prejudice Reduction,” in the Handbook of Computational Social Psychology, adapted from Public Affairs Quarterly 19 (2) 2005.
Peer reviewed E³-MAN. An Institutionally-guided multi-agent. Model for fair and efficient negotiation.
José luis bustelo | Published Monday, September 01, 2025Negotiation plays a fundamental role in shaping human societies, underpinning conflict resolution, institutional design, and economic coordination. This article introduces E³-MAN, a novel multi-agent model for negotiation that integrates individual utility maximization with fairness and institutional legitimacy. Unlike classical approaches grounded solely in game theory, our model incorporates Bayesian opponent modeling, transfer learning from past negotiation domains, and fallback institutional rules to resolve deadlocks. Agents interact in dynamic environments characterized by strategic heterogeneity and asymmetric information, negotiating over multidimensional issues under time constraints. Through extensive simulation experiments, we compare E³-MAN against the Nash bargaining solution and equal-split baselines using key performance metrics: utilitarian efficiency, Nash social welfare, Jain fairness index, Gini coefficient, and institutional compliance. Results show that E³-MAN achieves near-optimal efficiency while significantly improving distributive equity and agreement stability. A legal application simulating multilateral labor arbitration demonstrates that institutional default rules foster more balanced outcomes and increase negotiation success rates from 58% to 98%. By combining computational intelligence with normative constraints, this work contributes to the growing field of socially aware autonomous agents. It offers a virtual laboratory for exploring how simple institutional interventions can enhance justice, cooperation, and robustness in complex socio-legal systems.
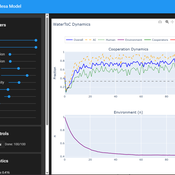
Tragedy of the Commons with Environmental Feedback: A Model of Human-AI Socio-Environmental Water Dilemma
Ivana Malcic Luka Waronig Andrew Crossley | Published Saturday, July 05, 2025 | Last modified Sunday, July 06, 2025This project is an interactive agent-based model simulating consumption of a shared, renewable resource using a game-theoretic framework with environmental feedback. The primary function of this model was to test how resource-use among AI and human agents degrades the environment, and to explore the socio-environmental feedback loops that lead to complex emergent system dynamics. We implemented a classic game theoretic matrix which decides agents´ strategies, and added a feedback loop which switches between strategies in pristine vs degraded environments. This leads to cooperation in bad environments, and defection in good ones.
Despite this use, it can be applicable for a variety of other scenarios including simulating climate disasters, environmental sensitivity to resource consumption, or influence of environmental degradation to agent behaviour.
The ABM was inspired by the Weitz et. al. (2016, https://pubmed.ncbi.nlm.nih.gov/27830651/) use of environmental feedback in their paper, as well as the Demographic Prisoner’s Dilemma on a Grid model (https://mesa.readthedocs.io/stable/examples/advanced/pd_grid.html#demographic-prisoner-s-dilemma-on-a-grid). The main innovation is the added environmental feedback with local resource replenishment.
Beyond its theoretical insights into coevolutionary dynamics, it serves as a versatile tool with several practical applications. For urban planners and policymakers, the model can function as a ”digital sandbox” for testing the impacts of locating high-consumption industrial agents, such as data centers, in proximity to residential communities. It allows for the exploration of different urban densities, and the evaluation of policy interventions—such as taxes on defection or subsidies for cooperation—by directly modifying the agents’ resource consumptions to observe effects on resource health. Furthermore, the model provides a framework for assessing the resilience of such socio-environmental systems to external shocks.
…

Peer reviewed Evolution of Conditional Cooperation in a Spatial Public Goods Game
Marco Janssen Francesca Federico Raksha Balakrishna | Published Saturday, March 15, 2025A model to investigate the Evolution of Conditional Cooperation in a Spatial Public Goods Game. We consider two conditional cooperation strategies: one based on thresholds (Battu & Srinivasan, 2020) and another based on independent decisions for each number of cooperating neighbors. We examine the effects of productivity and conditional cooperation criteria on the trajectory of cooperation. Cooperation is evolving with no need for additional mechanisms apart from spatial structure when agents follow conditional strategies. We confirm the positive influence of productivity and cluster formation on the evolution of cooperation in spatial models. Results are robust for the two types of conditional cooperation strategies.
Status hierarchies and the emergence of cooperation in task groups
Hsuan-Wei Lee | Published Thursday, January 02, 2025This repository contains an agent-based simulation model exploring how status hierarchies influence the emergence and sustainability of cooperation in task-oriented groups. The model builds on evolutionary game theory to examine the dynamics of cooperation under single-leader and multi-leader hierarchies, investigating factors such as group size, assortativity, and hierarchical clarity. Key findings highlight the trade-offs between different leadership structures in fostering group cooperation and reveal the conditions under which cooperation is most stable.
The repository includes code for simulations, numerical analysis scripts, and visualization tools to replicate the results presented in the manuscript titled “Status hierarchies and the emergence of cooperation in task groups.”
Feel free to explore, reproduce the findings, or adapt the model for further research!
Using Agent-Based Modelling and Reinforcement Learning to Study Hybrid Threats
kpadur | Published Friday, September 20, 2024Hybrid attacks coordinate the exploitation of vulnerabilities across domains to undermine trust in authorities and cause social unrest. Whilst such attacks have primarily been seen in active conflict zones, there is growing concern about the potential harm that can be caused by hybrid attacks more generally and a desire to discover how better to identify and react to them. In addressing such threats, it is important to be able to identify and understand an adversary’s behaviour. Game theory is the approach predominantly used in security and defence literature for this purpose. However, the underlying rationality assumption, the equilibrium concept of game theory, as well as the need to make simplifying assumptions can limit its use in the study of emerging threats. To study hybrid threats, we present a novel agent-based model in which, for the first time, agents use reinforcement learning to inform their decisions. This model allows us to investigate the behavioural strategies of threat agents with hybrid attack capabilities as well as their broader impact on the behaviours and opinions of other agents.
GODS: Gossip-Oriented Dilemma Simulator
Jan Majewski | Published Wednesday, September 04, 2024 | Last modified Monday, September 29, 2025Model of influence of access to social information spread via social network on decisions in a two-person game.
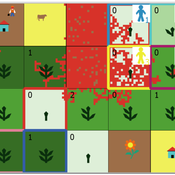
Peer reviewed A Picit Jeu: an Agent-Based Model for role-playing game
James Millington Ingrid Vigna | Published Friday, May 24, 2024A Picit Jeu is an agent-based model (ABM) developed as a supporting tool for a role-playing game of the same name. The game is intended for stakeholders involved in land management and fire prevention at a municipality level. It involves four different roles: farmers, forest technicians, municipal administrators and forest private owners. The model aims to show the long-term effects of their different choices about forest and pasture management on fire hazard, letting them test different management strategies in an economically constraining context. It also allows the players to explore different climatic and economic scenarios. A Picit Jeu ABM reproduces the ecological, social and economic characteristics and dynamics of an Alpine valley in north-west Italy. The model should reproduce a primary general pattern: the less players undertake landscape management actions, by thinning and cutting forests or grazing pastures, the higher the probability that a fire will burn a large area of land.
Model supporting the serious game RÁC
Patrick Taillandier Alexis Drogoul Léo Biré | Published Thursday, January 25, 2024This model is supporting the serious game RÁC (“waste” in Vietnamese), dedicated to foster discussion about solid waste management in a Vietnamese commune in the Bắc Hưng Hải irrigation system.
The model is replicating waste circulation and environmental impact in four fictive villages. During the game, the players take actions and see how their decisions have an impact on the model.
This model was implemented using the GAMA platform, using gaml language.
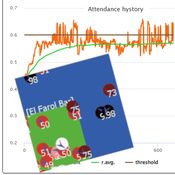
Peer reviewed Flibs’NFarol: Self-Organized Efficiency and Fairness Emergence in an Evolutive Game
Cosimo Leuci | Published Thursday, October 12, 2023According to the philosopher of science K. Popper “All life is problem solving”. Genetic algorithms aim to leverage Darwinian selection, a fundamental mechanism of biological evolution, so as to tackle various engineering challenges.
Flibs’NFarol is an Agent Based Model that embodies a genetic algorithm applied to the inherently ill-defined “El Farol Bar” problem. Within this context, a group of agents operates under bounded rationality conditions, giving rise to processes of self-organization involving, in the first place, efficiency in the exploitation of available resources. Over time, the attention of scholars has shifted to equity in resource distribution, as well. Nowadays, the problem is recognized as paradigmatic within studies of complex evolutionary systems.
Flibs’NFarol provides a platform to explore and evaluate factors influencing self-organized efficiency and fairness. The model represents agents as finite automata, known as “flibs,” and offers flexibility in modifying the number of internal flibs states, which directly affects their behaviour patterns and, ultimately, the diversity within populations and the complexity of the system.
Displaying 10 of 81 results game clear search