Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 148 results networks clear search
ABMIND: An Empirically Informed Agent-Based Model of Psychological Distance and Environmental Protection Behavior
Wenhan Feng | Published Saturday, June 13, 2026ABMIND, the Agent-Based Model of Individual Psychological Distance, is a modeling framework developed to examine how psychological distance influences environmental protection behavior in coastal farming communities in southern China. Using household survey data and empirically estimated behavioral pathways, the model represents how uncertainty shapes four dimensions of psychological distance, namely temporal, spatial, social and hypothetical distance, and how these dimensions guide protection and degradation decisions. Agents include households, government actors and mangrove ecosystem patches, connected through social networks and ecological feedbacks that affect learning, expectations and perceived benefits. Policy interventions such as rewards, penalties and publicity guidance efforts work by modifying uncertainty and psychological distance rather than directly controlling behavior. ABMIND is implemented as a spatially explicit model following the ODD protocol, and a concise user guide is provided. In developing ABMIND we introduce a structured validation workflow that links statistical mediation analysis with simulation-based diagnostics, allowing empirical cognitive mechanisms to be systematically embedded and tested within the ABM. This integrated approach strengthens the credibility of psychological-mechanism models and supports their use in policy evaluation. The framework offers a methodological platform for integrating cognitive mechanisms into agent-based environmental behavior modeling and for evaluating policy strategies that support ecosystem protection.
Model paper:
ABMIND: An empirically informed agent-based model of psychological distance and environmental protection behaviour
Ecological Modelling
https://doi.org/10.1016/j.ecolmodel.2026.111700
From Boundary Crossings to Global Connectivity: A Minimal Mechanism in Structured Agent-Based Landscapes
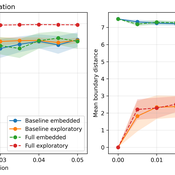
Fabio Nelli | Published Sunday, May 17, 2026This repository contains the Python implementation of an agent-based model investigating how localized boundary-crossing dynamics generate large-scale connectivity in structured multi-attractor landscapes.
Agents evolve in a continuous two-dimensional environment composed of attractor basins. A fraction of agents exhibits exploratory higher-mobility dynamics, while the remaining agents remain locally constrained. The model analyzes how localized configurational transitions accumulate into transition networks that progressively integrate the explored state space.
The repository includes:
…
Zensei Wago: A Wealth-Integrated Social Capital Model
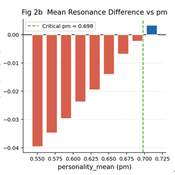
hiiki | Published Friday, May 15, 2026Interest-based compound economies generate monotonically increasing wealth inequality through multiplicative accumulation dynamics, yet the conditions under which gift-based reciprocal exchange outperforms such systems in collective well-being remain unquantified. We present Zensei Wago (全生和合), a seven-layer agent-based model comparing a Gift Resource Circulation (GRC) economy with a Compound Interest Circulation (CIC) economy under identical initial conditions. Across N = 5000 Monte Carlo replications (T = 700 ticks, N = 100 agents), GRC produced significantly higher collective resonance than CIC (p < 0.001, Cohen’s d = +0.171), above a critical prosocial threshold pm ≈ 0.698. Cohen’s d grows monotonically with duration — d = +1.943 at T = 1500 and d = +4.126 at T = 3000 — driven primarily by structural collapse of CIC resonance as inequality exceeds a critical Gini threshold (G > 0.333), while GRC resonance remains stable. The gift mechanism further decouples collective well-being from distributional outcomes, generating resonance through relational quality rather than material redistribution. Network topology analysis across seven configurations — combining a Watts-Strogatz rewiring sweep and a T = 1500 longitudinal replication — reveals that ring topology maximises GRC advantage (d = +1.17), that most topology-dependent reversals are transient (sparse and small-world both transition to significantly positive by T = 1500), and that a critical rewiring threshold of p ≈ 0.10–0.20 separates GRC-advantaged from GRC-disadvantaged network configurations. Scale-free networks remain persistently adverse (d = -7.24*), requiring structural redesign for gift-economy viability.
VIBE (Visible and Interconnected Behavioral Expectations Model)
Wenhan Feng | Published Friday, March 20, 2026This model aims to study the dynamic propagation of individual behaviour within social networks, focusing on how normative expectations (NE) and experiential expectations (EE) jointly influence behavioural decisions. It also explores the long-term effects of different intervention scenarios (such as enhancing visibility, considering indirect social links, and education) on behavioural propagation patterns and the overall behaviour of the group.
The model was developed in NetLogo 6.4. It generates simulated groups based on large-scale survey data, utilizing NetLogo’s CSV, Table, and Matrix extensions. The model also employs the NW extension to enable network analysis functionality.
The model is designed for research “Shaping social norms to promote individual response behavior in public crises: An agent-based modeling approach” in Journal of Cleaner Production, Volume 554, 8 April 2026, 148014
https://doi.org/10.1016/j.jclepro.2026.148014
Peer reviewed Gradient Descent Simulation
Ilyes Azouani | Published Wednesday, March 18, 2026 | Last modified Monday, May 25, 2026This model visualizes gradient descent optimization - the fundamental algorithm used to train neural networks and other machine learning models. Agents represent different optimization algorithms searching for the minimum of a loss landscape (the “error surface” that ML models try to minimize during training).
The model demonstrates how different optimizer types (SGD, Momentum with different parameters) behave on various loss landscapes, from simple bowls to the notoriously difficult Rosenbrock “banana valley” function. This helps build intuition about why certain optimization algorithms work better than others for different problem geometries.
HOW IT WORKS
…
Peer reviewed A dynamic identity model for misinformation in social networks
emdhar | Published Friday, February 27, 2026A dynamic identity model for misinformation in social networks, an agent-based model of social identity and misinformation dynamics.
I developed this model as a part of my master’s thesis, “Does social identity drive belief and persistence in online misinformation? An agent-based modelling approach” at University College Dublin, Ireland (2024-2025).
The purpose of this model is to further understand the dynamics of misinformation sharing as an expression of social identity. I introduce a framework to understand the influence of self-categorisation on misinformation persistence in social network. It integrates a social learning model with the Dynamic Identity Model for Agents (DIMA) using simple logic to simulate the social trade-offs driving misinformation and observe the effects on misinformation spread.
FRAMe (Flood Resilience Agent-Based Model)
Wenhan Feng | Published Wednesday, October 22, 2025The FRAMe (Flood Resilience Agent-Based Model) serves as a framework designed to simulate flood resilience dynamics at the community level, focusing on a rural settlement in the Mekong River Basin. Integrating empirical data from extensive surveys, Bayesian networks, and hydrological simulations, the framework quantifies resilience as a trade-off between robustness (resistance to damage) and adaptability (capacity for dynamic response). Agents include households, governments, and other actors, linked by social and governance networks that facilitate knowledge transfer, resource distribution, and risk communication. FRAMe incorporates mechanisms for flood forecasting, policy interventions (education, aid, insurance), and individual and collective decision-making, grounded in Protection Motivation Theory and MoHuB frameworks. The framework’s spatially explicit design leverages GIS data, which supports scenario testing of governance structures and stakeholder interactions. By examining policy scenarios and agent behavior, FRAMe aims to inform adaptive flood management strategies and enhance community resilience.
Peer reviewed The effect of homophily on co-offending outcomes
Ruslan Klymentiev Christophe Vandeviver Luis E. C. Rocha | Published Friday, September 26, 2025This Agent-Based Model is designed to simulate how similarity-based partner selection (homophily) shapes the formation of co-offending networks and the diffusion of skills within those networks. Its purpose is to isolate and test the effects of offenders’ preference for similar partners on network structure and information flow, under controlled conditions.
In the model, offenders are represented as agents with an individual attribute and a set of skills. At each time step, agents attempt to select partners based on similarity preference. When two agents mutually select each other, they commit a co-offense, forming a tie and exchanging a skill. The model tracks the evolution of network properties (e.g., density, clustering, and tie strength) as well as the spread of skills over time.
This simple and theoretical model does not aim to produce precise empirical predictions but rather to generate insights and test hypotheses about the trade-off between partnership stability and information diffusion. It provides a flexible framework for exploring how changes in partner selection preferences may lead to differences in criminal network dynamics. Although the model was developed to simulate offenders’ interactions, in principle, it could be applied to other social processes involving social learning and skills exchange.
…
Peer reviewed Casting: A Bio-Inspired Method for Restructuring Machine Learning Ensembles
Colin Lynch Bryan Daniels | Published Thursday, September 18, 2025The wisdom of the crowd refers to the phenomenon in which a group of individuals, each making independent decisions, can collectively arrive at highly accurate solutions—often more accurate than any individual within the group. This principle relies heavily on independence: if individual opinions are unbiased and uncorrelated, their errors tend to cancel out when averaged, reducing overall bias. However, in real-world social networks, individuals are often influenced by their neighbors, introducing correlations between decisions. Such social influence can amplify biases, disrupting the benefits of independent voting. This trade-off between independence and interdependence has striking parallels to ensemble learning methods in machine learning. Bagging (bootstrap aggregating) improves classification performance by combining independently trained weak learners, reducing bias. Boosting, on the other hand, explicitly introduces sequential dependence among learners, where each learner focuses on correcting the errors of its predecessors. This process can reinforce biases present in the data even if it reduces variance. Here, we introduce a new meta-algorithm, casting, which captures this biological and computational trade-off. Casting forms partially connected groups (“castes”) of weak learners that are internally linked through boosting, while the castes themselves remain independent and are aggregated using bagging. This creates a continuum between full independence (i.e., bagging) and full dependence (i.e., boosting). This method allows for the testing of model capabilities across values of the hyperparameter which controls connectedness. We specifically investigate classification tasks, but the method can be used for regression tasks as well. Ultimately, casting can provide insights for how real systems contend with classification problems.
Netlogo model ` Effect of Network Homophily and Partisanship on Social Media to “Oil Spill” Polarizations’
takuya nagura | Published Saturday, September 13, 2025This model was utilized for the simulation in the paper titled Effect of Network Homophily and Partisanship on Social Media to “Oil Spill” Polarizations. It allows you to examine whether oil spill polarization occurs through people’s communication under various conditions.
・Choose the network construction conditions you’d like to examine from the “rewire-style” chooser box.
・Select the desired strength of partisanship from the “partisanlevel” chooser box. You can also set the strength manually in the code tab.
・You can set the number of dynamic topics using the “number-of-topics” slider.
・Use the “divers-of-opinion” slider to set the number of preference types for each dynamic topic.
…
Displaying 10 of 148 results networks clear search