Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 19 results calibration clear search
Peer reviewed Kenya ITN Agent-Based Microsimulation (2003–2024)
Wooyoung Kim Hosang Shin | Published Saturday, April 18, 2026 | Last modified Tuesday, June 16, 2026An agent-based microsimulation of insecticide-treated net (ITN) distribution and adoption in Kenya (2003–2024), integrating the Theory of Planned Behaviour, Rogers diffusion, Weibull net decay, and a GPS-based two-layer social network. 8,561 household agents calibrated via Approximate Bayesian Computation to six DHS/MIS survey waves, achieving 2.42 pp mean absolute error on Kenya-level ownership. The analysis chain supports mechanism counterfactuals and policy experiments on equity outcomes of ITN distribution strategies.
GenoScope
Kristin Crouse | Published Wednesday, May 29, 2024 | Last modified Wednesday, April 09, 2025GenoScope is a modular agent-based model designed to simulate how cells respond to environmental stressors or other treatment conditions across species. Genes, treatment conditions, and cell physiology outcomes are represented as interacting agents that influence each other’s behavior over time. Rather than imposing fixed interaction rules, GenoScope initializes with randomized regulatory logic and calibrates rule sets based on empirical data. Calibration is grounded in a common-garden experiment involving 16 mammalian species—including humans, dolphins, bats, and camels—exposed to varying levels of temperature, glucose, and oxygen. This comparative approach enables the identification of mechanisms by which animal cells achieve robustness under extreme environmental conditions.
User Guide and Templates for RAT-RS (a reporting standard for improving the documentation of data use in agent-based modelling)
Melania Borit Edmund Chattoe-Brown Peer-Olaf Siebers Sebastian Achter | Published Saturday, March 12, 2022The Rigor and Transparency Reporting Standard (RAT-RS) is a tool to improve the documentation of data use in Agent-Based Modelling. Following the development of reporting standards for models themselves, attention to empirical models has now reached a stage where these standards need to take equally effective account of data use (which until now has tended to be an afterthought to model description). It is particularly important that a standard should allow the reporting of the different uses to which data may be put (specification, calibration and validation), but also that it should be compatible with the integration of different kinds of data (for example statistical, qualitative, ethnographic and experimental) sometimes known as mixed methods research.
For the full details on the RAT-RS, please refer to the related publication “RAT-RS: A Reporting Standard for Improving the Documentation of Data Use in Agent-Based Modelling” (http://dx.doi.org/10.1080/13645579.2022.2049511).
Here we provide supplementary material for this article, consisting of a RAT-RS user guide and RAT-RS templates.

Peer reviewed Agent-based model to simulate equilibria and regime shifts emerged in lake ecosystems
no contributors listed | Published Tuesday, January 25, 2022(An empty output folder named “NETLOGOexperiment” in the same location with the LAKEOBS_MIX.nlogo file is required before the model can be run properly)
The model is motivated by regime shifts (i.e. abrupt and persistent transition) revealed in the previous paleoecological study of Taibai Lake. The aim of this model is to improve a general understanding of the mechanism of emergent nonlinear shifts in complex systems. Prelimnary calibration and validation is done against survey data in MLYB lakes. Dynamic population changes of function groups can be simulated and observed on the Netlogo interface.
Main functional groups in lake ecosystems were modelled as super-individuals in a space where they interact with each other. They are phytoplankton, zooplankton, submerged macrophyte, planktivorous fish, herbivorous fish and piscivorous fish. The relationships between these functional groups include predation (e.g. zooplankton-phytoplankton), competition (phytoplankton-macrophyte) and protection (macrophyte-zooplankton). Each individual has properties in size, mass, energy, and age as physiological variables and reproduce or die according to predefined criteria. A system dynamic model was integrated to simulate external drivers.
Set biological and environmental parameters using the green sliders first. If the data of simulation are to be logged, set “Logdata” as true and input the name of the file you want the spreadsheet(.csv) to be called. You will need create an empty folder called “NETLOGOexperiment” in the same level and location with the LAKEOBS_MIX.nlogo file. Press “setup” to initialise the system and “go” to start life cycles.
An ABM of historic British milk consumption
Matthew Gibson | Published Monday, December 20, 2021Substitution of food products will be key to realising widespread adoption of sustainable diets. We present an agent-based model of decision-making and influences on food choice, and apply it to historically observed trends of British whole and skimmed (including semi) milk consumption from 1974 to 2005. We aim to give a plausible representation of milk choice substitution, and test different mechanisms of choice consideration. Agents are consumers that perceive information regarding the two milk choices, and hold values that inform their position on the health and environmental impact of those choices. Habit, social influence and post-decision evaluation are modelled. Representative survey data on human values and long-running public concerns empirically inform the model. An experiment was run to compare two model variants by how they perform in reproducing these trends. This was measured by recording mean weekly milk consumption per person. The variants differed in how agents became disposed to consider alternative milk choices. One followed a threshold approach, the other was probability based. All other model aspects remained unchanged. An optimisation exercise via an evolutionary algorithm was used to calibrate the model variants independently to observed data. Following calibration, uncertainty and global variance-based temporal sensitivity analysis were conducted. Both model variants were able to reproduce the general pattern of historical milk consumption, however, the probability-based approach gave a closer fit to the observed data, but over a wider range of uncertainty. This responds to, and further highlights, the need for research that looks at, and compares, different models of human decision-making in agent-based and simulation models. This study is the first to present an agent-based modelling of food choice substitution in the context of British milk consumption. It can serve as a valuable pre-curser to the modelling of dietary shift and sustainable product substitution to plant-based alternatives in Britain.
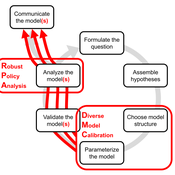
DMC-RPA: Diverse Model Calibration for Robust Policy Analysis (applied to an ABM of smallholder farmer resilience)
Tim Williams | Published Sunday, August 30, 2020This repository contains: (1) a model calibration procedure that identifies a set of diverse, plausible models; and (2) an ABM of smallholder agriculture, which is used as a case study application for the calibration method. By identifying a set of diverse models, the calibration method attends to the issue of “equifinality” prevalent in complex systems, which is a situation where multiple plausible process descriptions exist for a single outcome.

Peer reviewed Neighbor Influenced Energy Retrofit (NIER) agent-based model
Eric Boria | Published Friday, April 03, 2020The NIER model is intended to add qualitative variables of building owner types and peer group scales to existing energy efficiency retrofit adoption models. The model was developed through a combined methodology with qualitative research, which included interviews with key stakeholders in Cleveland, Ohio and Detroit and Grand Rapids, Michigan. The concepts that the NIER model adds to traditional economic feasibility studies of energy retrofit decision-making are differences in building owner types (reflecting strategies for managing buildings) and peer group scale (neighborhoods of various sizes and large-scale Districts). Insights from the NIER model include: large peer group comparisons can quickly raise the average energy efficiency values of Leader and Conformist building owner types, but leave Stigma-avoider owner types as unmotivated to retrofit; policy interventions such as upgrading buildings to energy-related codes at the point of sale can motivate retrofits among the lowest efficient buildings, which are predominantly represented by the Stigma-avoider type of owner; small neighborhood peer groups can successfully amplify normal retrofit incentives.
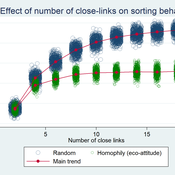
Waste separation in small-world networks
František Kalvas Michaela Kudrnáčová | Published Monday, September 30, 2019The model answers the question how homophily and number of close-links in small-world network influences behavior of consumats. The results show that the more close-links the more probable the consumat follows the major behavior, but homophilly blocks the major behavior and supports survival of the minor behavior.
Peer reviewed Gender desegregation in German high schools
Klaus G. Troitzsch | Published Tuesday, February 05, 2019 | Last modified Sunday, November 08, 2020The study goes back to a model created in the 1990s which successfully tried to replicate the changes of the percentages of female teachers among the teaching staff in high schools (“Gymnasien”) in the German federal state of Rheinland-Pfalz. The current version allows for additional validation and calibration of the model and is accompanied with the empirical data against which the model is tested and with an analysis program especially designed to perform the analyses in the most recent journal article.
Machine Learning simulates Agent-based Model
Bernardo Furtado | Published Wednesday, March 07, 2018This is an initial exploratory exercise done for the class @ http://thiagomarzagao.com/teaching/ipea/ Text available here: https://arxiv.org/abs/1712.04429v1
The program:
Reads output from an ABM model and its parameters’ configuration
Creates a socioeconomic optimal output based on two ABM results of the modelers choice
Organizes the data as X and Y matrices
Trains some Machine Learning algorithms
…
Displaying 10 of 19 results calibration clear search