Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 25 results Python clear search
An Agent-Based Model of Saving under Quasi-Hyperbolic Discounting on a Social Network.
Jose Alejandro Velazquez Monzon | Published Wednesday, June 24, 2026An agent-based model of saving and dissaving behaviour under quasi-hyperbolic (β–δ) discounting. Building on the individual decision problem of Cao and Werning (2018), the model embeds present-biased agents in a Watts–Strogatz small-world network and adds three configurable mechanisms of social influence — information diffusion, peer comparison, and social-norm conformity — across five heterogeneous behavioural profiles (Planners, Moderates, Procrastinators, Inverse Procrastinators, and Impulsive agents).
Each profile’s saving policy is approximated by value-function iteration over a discretised wealth grid; the solved policies are cached and applied as agents interact over their network neighbourhoods. The model tests whether each social mechanism can alter the saving and wealth trajectories that present-biased agents would otherwise follow in isolation, and characterises the direction and size of each effect on median wealth, wealth inequality (Gini), and the incidence of severely depleted agents.
The deposit includes the core model (Model.py), an analysis and visualisation pipeline (analyze_results.py), a standalone ODD description (ODD.md), and pinned dependencies.
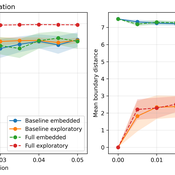
From Boundary Crossings to Global Connectivity: A Minimal Mechanism in Structured Agent-Based Landscapes
Fabio Nelli | Published Sunday, May 17, 2026This repository contains the Python implementation of an agent-based model investigating how localized boundary-crossing dynamics generate large-scale connectivity in structured multi-attractor landscapes.
Agents evolve in a continuous two-dimensional environment composed of attractor basins. A fraction of agents exhibits exploratory higher-mobility dynamics, while the remaining agents remain locally constrained. The model analyzes how localized configurational transitions accumulate into transition networks that progressively integrate the explored state space.
The repository includes:
…
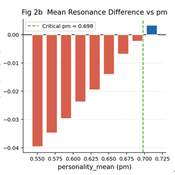
Zensei Wago: A Wealth-Integrated Social Capital Model
hiiki | Published Friday, May 15, 2026Interest-based compound economies generate monotonically increasing wealth inequality through multiplicative accumulation dynamics, yet the conditions under which gift-based reciprocal exchange outperforms such systems in collective well-being remain unquantified. We present Zensei Wago (全生和合), a seven-layer agent-based model comparing a Gift Resource Circulation (GRC) economy with a Compound Interest Circulation (CIC) economy under identical initial conditions. Across N = 5000 Monte Carlo replications (T = 700 ticks, N = 100 agents), GRC produced significantly higher collective resonance than CIC (p < 0.001, Cohen’s d = +0.171), above a critical prosocial threshold pm ≈ 0.698. Cohen’s d grows monotonically with duration — d = +1.943 at T = 1500 and d = +4.126 at T = 3000 — driven primarily by structural collapse of CIC resonance as inequality exceeds a critical Gini threshold (G > 0.333), while GRC resonance remains stable. The gift mechanism further decouples collective well-being from distributional outcomes, generating resonance through relational quality rather than material redistribution. Network topology analysis across seven configurations — combining a Watts-Strogatz rewiring sweep and a T = 1500 longitudinal replication — reveals that ring topology maximises GRC advantage (d = +1.17), that most topology-dependent reversals are transient (sparse and small-world both transition to significantly positive by T = 1500), and that a critical rewiring threshold of p ≈ 0.10–0.20 separates GRC-advantaged from GRC-disadvantaged network configurations. Scale-free networks remain persistently adverse (d = -7.24*), requiring structural redesign for gift-economy viability.
Structural Violence and Neurobiological Adaptation: Modeling the Trajectory of Youth Outside of Care
masterpiece33330-prog | Published Thursday, November 27, 2025This study presents a System Dynamics (SD) model that explores the “trajectories of homelessness” among youth outside of the formal care system. Unlike traditional approaches that view runaway behavior as a discrete choice, this model reinterprets it as a neurobiological adaptation to chronic resource deprivation and systemic neglect.
The model incorporates key mechanisms such as ‘Allostatic Load’ accumulation, ‘PFC-Amygdala Switching’, and the ‘Iatrogenic Effects’ of shelter policies. It utilizes Monte Carlo simulations to demonstrate how structural factors create a “probabilistic vulnerability,” trapping youth in cycles of survival crime and isolation regardless of individual resilience.
The uploaded code includes a Python implementation of the model to ensure reproducibility of the stochastic analysis presented in the paper.
Peer reviewed AgModel
Isaac Ullah | Published Friday, December 06, 2024AgModel is an agent-based model of the forager-farmer transition. The model consists of a single software agent that, conceptually, can be thought of as a single hunter-gather community (i.e., a co-residential group that shares in subsistence activities and decision making). The agent has several characteristics, including a population of human foragers, intrinsic birth and death rates, an annual total energy need, and an available amount of foraging labor. The model assumes a central-place foraging strategy in a fixed territory for a two-resource economy: cereal grains and prey animals. The territory has a fixed number of patches, and a starting number of prey. While the model is not spatially explicit, it does assume some spatiality of resources by including search times.
Demographic and environmental components of the simulation occur and are updated at an annual temporal resolution, but foraging decisions are “event” based so that many such decisions will be made in each year. Thus, each new year, the foraging agent must undertake a series of optimal foraging decisions based on its current knowledge of the availability of cereals and prey animals. Other resources are not accounted for in the model directly, but can be assumed for by adjusting the total number of required annual energy intake that the foraging agent uses to calculate its cereal and prey animal foraging decisions. The agent proceeds to balance the net benefits of the chance of finding, processing, and consuming a prey animal, versus that of finding a cereal patch, and processing and consuming that cereal. These decisions continue until the annual kcal target is reached (balanced on the current human population). If the agent consumes all available resources in a given year, it may “starve”. Starvation will affect birth and death rates, as will foraging success, and so the population will increase or decrease according to a probabilistic function (perturbed by some stochasticity) and the agent’s foraging success or failure. The agent is also constrained by labor caps, set by the modeler at model initialization. If the agent expends its yearly budget of person-hours for hunting or foraging, then the agent can no longer do those activities that year, and it may starve.
Foragers choose to either expend their annual labor budget either hunting prey animals or harvesting cereal patches. If the agent chooses to harvest prey animals, they will expend energy searching for and processing prey animals. prey animals search times are density dependent, and the number of prey animals per encounter and handling times can be altered in the model parameterization (e.g. to increase the payoff per encounter). Prey animal populations are also subject to intrinsic birth and death rates with the addition of additional deaths caused by human predation. A small amount of prey animals may “migrate” into the territory each year. This prevents prey animals populations from complete decimation, but also may be used to model increased distances of logistic mobility (or, perhaps, even residential mobility within a larger territory).
…
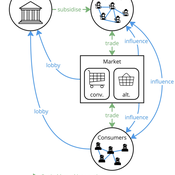
Agent-based model of power dynamics in agri-food systems
Tim Williams | Published Sunday, October 27, 2024 | Last modified Thursday, June 12, 2025This is a stylised agent-based model designed to explore the conditions that lead to lock-ins and transitions in agri-food systems.
The model represents interactions between four different types of agents: farmers, consumers, markets, and the state. Farmers and consumers are heterogeneous, and at each time step decide whether to trade with one of two market agents: the conventional or alternative. The state agent provides subsidies to the farmers at each time step.
The key emergent outcome is the fraction of trade in each time step that flows through the alternative market agent. This arises from the distributed decisions of farmer and consumer agents. A “sustainability transition” is defined as a shift in the dominant practices (and associated balance of power) towards the alternative paradigm.
…
Integrate land use policies into the agent-based model to simulate land use change
Jing Gao | Published Sunday, June 09, 2024This study employs a hierarchical cross-departmental ABM to explore the question: How and to what extent are the land use policies enforced when assessed against the real-world land use pattern? Specifically, two sub-questions are of interest: How can real-world policy interactions be abstracted into the behavior across hierarchical governmental departments in the model? How can the level of enforcement for each land use policy be quantified under these interactions? We build three hierarchical agents—the central level, the local level that incorporates three departments, and the village collective level—with simplified but plausible processes of land use change, with levels of enforcement of different land use policies as key parameters. We calibrate the model using a genetic algorithm to determine those parameters and answer our research question. We further applied the model to simulate potential land use changes and investigate the implications of different policy options. The results are expected to provide insights into the intricate relationships shaping land use processes, contributing to evidence-based decision-making in urban planning and sustainable land use management.
Peer reviewed Agent-Based Ramsey growth model with endogenous technical progress (ABRam-T)
Sarah Wolf Aida Sarai Figueroa Alvarez Malika Tokpanova | Published Wednesday, February 14, 2024 | Last modified Monday, February 19, 2024The Agent-Based Ramsey growth model is designed to analyze and test a decentralized economy composed of utility maximizing agents, with a particular focus on understanding the growth dynamics of the system. We consider farms that adopt different investment strategies based on the information available to them. The model is built upon the well-known Ramsey growth model, with the introduction of endogenous technical progress through mechanisms of learning by doing and knowledge spillovers.
Peer reviewed Dynamic Equilibria Prediction: Experience-Weighted Attraction (EWA), Python Implementation
Vinicius Ferraz | Published Friday, December 02, 2022This project is based on a Jupyter Notebook that describes the stepwise implementation of the EWA model in bi-matrix ( 2×2 ) strategic-form games for the simulation of economic learning processes. The output is a dataset with the simulated values of Attractions, Experience, selected strategies, and payoffs gained for the desired number of rounds and periods. The notebook also includes exploratory data analysis over the simulated output based on equilibrium, strategy frequencies, and payoffs.
Cellular automata model of social networks
Rubens de Almeida Zimbres | Published Tuesday, August 02, 2022This project was developed during the Santa Fe course Introduction to Agent-Based Modeling 2022. The origin is a Cellular Automata (CA) model to simulate human interactions that happen in the real world, from Rubens and Oliveira (2009). These authors used a market research with real people in two different times: one at time zero and the second at time zero plus 4 months (longitudinal market research). They developed an agent-based model whose initial condition was inherited from the results of the first market research response values and evolve it to simulate human interactions with Agent-Based Modeling that led to the values of the second market research, without explicitly imposing rules. Then, compared results of the model with the second market research. The model reached 73.80% accuracy.
In the same way, this project is an Exploratory ABM project that models individuals in a closed society whose behavior depends upon the result of interaction with two neighbors within a radius of interaction, one on the relative “right” and other one on the relative “left”. According to the states (colors) of neighbors, a given cellular automata rule is applied, according to the value set in Chooser. Five states were used here and are defined as levels of quality perception, where red (states 0 and 1) means unhappy, state 3 is neutral and green (states 3 and 4) means happy.
There is also a message passing algorithm in the social network, to analyze the flow and spread of information among nodes. Both the cellular automaton and the message passing algorithms were developed using the Python extension. The model also uses extensions csv and arduino.
Displaying 10 of 25 results Python clear search