About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 5 of 5 results machine learning clear search
Multi-agent modeling and analysis of the knowledge learning of a human-machine hybrid intelligent organization with human-machine trust
Haoxiang Zhang | Published Monday, April 24, 2023Machine learning technologies have changed the paradigm of knowledge discovery in organizations and transformed traditional organizational learning to human-machine hybrid intelligent organizational learning. However, it remains unclear how human-machine trust, which is an important factor that influences human-machine knowledge exchange, affects the effectiveness of human-machine hybrid intelligent organizational learning. To explore this issue, we used multi-agent simulation to construct a knowledge learning model of a human-machine hybrid intelligent organization with human-machine trust.
FlipFlop1-ProMEERB: A coupled social-ecological model with a promotional mechanism for emergence of environmentally responsible behavior
Liliana Perez Saeed Harati Roberto Molowny-Horas | Published Friday, December 17, 2021At the heart of a study of Social-Ecological Systems, this model is built by coupling together two independently developed models of social and ecological phenomena. The social component of the model is an abstract model of interactions of a governing agent and several user agents, where the governing agent aims to promote a particular behavior among the user agents. The ecological model is a spatial model of spread of the Mountain Pine Beetle in the forests of British Columbia, Canada. The coupled model allowed us to simulate various hypothetical management scenarios in a context of forest insect infestations. The social and ecological components of this model are developed in two different environments. In order to establish the connection between those components, this model is equipped with a ‘FlipFlop’ - a structure of storage directories and communication protocols which allows each of the models to process its inputs, send an output message to the other, and/or wait for an input message from the other, when necessary. To see the publications associated with the social and ecological components of this coupled model please see the References section.

Pedestrian Scramble
Sho Takami Rami Lake Dara Vancea | Published Tuesday, November 30, 2021 | Last modified Tuesday, June 10, 2025This is a model intended to demonstrate the function of scramble crossings and a more efficient flow of pedestrian traffic with the presence of diagonal crosswalks.
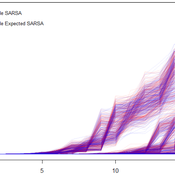
This model was developed to test the usability of evolutionary computing and reinforcement learning by extending a well known agent-based model. Sugarscape (Epstein & Axtell, 1996) has been used to demonstrate migration, trade, wealth inequality, disease processes, sex, culture, and conflict. It is on conflict that this model is focused to demonstrate how machine learning methodologies could be applied.
The code is based on the Sugarscape 2 Constant Growback model, availble in the NetLogo models library. New code was added into the existing model while removing code that was not needed and modifying existing code to support the changes. Support for the original movement rule was retained while evolutionary computing, Q-Learning, and SARSA Learning were added.
Machine Learning simulates Agent-based Model
Bernardo Furtado | Published Wednesday, March 07, 2018This is an initial exploratory exercise done for the class @ http://thiagomarzagao.com/teaching/ipea/ Text available here: https://arxiv.org/abs/1712.04429v1
The program:
Reads output from an ABM model and its parameters’ configuration
Creates a socioeconomic optimal output based on two ABM results of the modelers choice
Organizes the data as X and Y matrices
Trains some Machine Learning algorithms
…