Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 188 results for "Nuno Pinto" clear search
ABMIND: An Empirically Informed Agent-Based Model of Psychological Distance and Environmental Protection Behavior
Wenhan Feng | Published Saturday, June 13, 2026ABMIND, the Agent-Based Model of Individual Psychological Distance, is a modeling framework developed to examine how psychological distance influences environmental protection behavior in coastal farming communities in southern China. Using household survey data and empirically estimated behavioral pathways, the model represents how uncertainty shapes four dimensions of psychological distance, namely temporal, spatial, social and hypothetical distance, and how these dimensions guide protection and degradation decisions. Agents include households, government actors and mangrove ecosystem patches, connected through social networks and ecological feedbacks that affect learning, expectations and perceived benefits. Policy interventions such as rewards, penalties and publicity guidance efforts work by modifying uncertainty and psychological distance rather than directly controlling behavior. ABMIND is implemented as a spatially explicit model following the ODD protocol, and a concise user guide is provided. In developing ABMIND we introduce a structured validation workflow that links statistical mediation analysis with simulation-based diagnostics, allowing empirical cognitive mechanisms to be systematically embedded and tested within the ABM. This integrated approach strengthens the credibility of psychological-mechanism models and supports their use in policy evaluation. The framework offers a methodological platform for integrating cognitive mechanisms into agent-based environmental behavior modeling and for evaluating policy strategies that support ecosystem protection.
Model paper:
ABMIND: An empirically informed agent-based model of psychological distance and environmental protection behaviour
Ecological Modelling
https://doi.org/10.1016/j.ecolmodel.2026.111700

Simulating Climate Stress and Social Instability: An Agent-Based Model of Ecosystem Degradation and Violence in Coastal Communities
Jacopo A. Baggio hurtado-valdivieso | Published Sunday, April 12, 2026This model is an agent-based simulation designed to explore how climate-induced environmental degradation can contribute to the emergence of social violence in coastal communities that depend heavily on ecosystem services for their livelihoods. The model represents a coupled social–ecological system in which environmental shocks—such as sea level rise and marine ecosystem decline—affect local economic conditions, food security, and community stability.
Agents in the model represent individuals whose livelihoods depend on coastal ecosystems. Environmental degradation reduces ecosystem productivity and increases economic hardship, which can lead to the formation of grievances among agents. The model incorporates behavioral thresholds that determine how individuals respond to hardship and perceived injustice. Under certain conditions—particularly when institutional capacity and law enforcement effectiveness are limited—these grievances may escalate into violent behavior.
The simulation allows users to explore how different climate scenarios, levels of ecosystem degradation, livelihood dependence, and institutional responses influence the probability of social instability and violence. By modeling the interactions between environmental stress, socio-economic vulnerability, and governance capacity, the model provides a computational framework for examining potential pathways linking climate change and conflict in coastal social–ecological systems.
…

MASTOC-LLM (Multi-Agent System Tragedy of the Commons - Large Language Models)
Thomas Tuoti | Published Monday, May 18, 2026 | Last modified Tuesday, May 19, 2026MASTOC-LLM extends the classic Multi-Agent System Tragedy of the Commons (MASTOC) model by replacing hard-coded behavioral rules with autonomous decision-making powered by large language models (LLMs). Three heterogeneous agents manage herds of cows on a shared grassland commons. Each tick, an agent receives a structured prompt describing current resource levels, its own herd size, peer behavior, and — optionally — a rolling memory of recent rounds and messages from neighboring agents. The LLM returns a stocking decision (add, remove, or hold cows) together with a natural-language rationale and, when communication is enabled, a short message to broadcast to peers.
The model is designed to test whether LLM agents spontaneously develop Ostrom-style common-pool resource governance (mutual monitoring, graduated sanctions, graduated rule revision) or instead fall into identifiable failure modes. Preliminary experiments with Claude Haiku 4.5, GPT-5.4-mini, and DeepSeek R1:32b have revealed four recurring collapse patterns — Cooperative Paralysis, Defection Cascade, Overshoot-Panic, and Hybrid Architecture Failure — whose onset timing is sensitive to memory length, inter-agent communication, and the post-training alignment approach of the underlying model.
MASTOC-LLM is intended as a laboratory for generative agent-based modelling (GABM) methodology: it provides a clean, well-understood commons baseline against which LLM behavioral hypotheses can be systematically tested and compared across models, parameter sweeps, and alignment regimes.
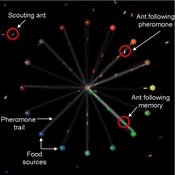
Composite Collective Decision Making - ant colony foraging model
Tomer Czaczkes Benjamin I Czaczkes | Published Thursday, December 17, 2015The model explores how two types of information - social (in the form of pheromone trails) and private (in the form of route memories) affect ant colony level foraging in a variable enviroment.

Peer reviewed FishCensus
Miguel Pais | Published Tuesday, December 06, 2016 | Last modified Thursday, February 09, 2017The FishCensus model simulates underwater visual census methods, where a diver estimates the abundance of fish. A separate model is used to shape species behaviours and save them to a file that can be shared and used by the counting model.
Informal risk-sharing cooperatives : ORP and Learning
Juliette Rouchier Victorien Barbet Renaud Bourlès | Published Monday, February 13, 2017 | Last modified Tuesday, May 16, 2023The model studies the dynamics of risk-sharing cooperatives among heterogeneous farmers. Based on their knowledge on their risk exposure and the performance of the cooperative farmers choose whether or not to remain in the risk-sharing agreement.

Agent-based model of WiFi tracking system in urban environment
Christopher Thron Khoi Tran | Published Friday, April 21, 2017This code simulates the WiFi user tracking system described in: Thron et al., “Design and Simulation of Sensor Networks for Tracking Wifi Users in Outdoor Urban Environments”. Testbenches used to create the figures in the paper are included.
Peer reviewed COMOKIT
Patrick Taillandier Alexis Drogoul Benoit Gaudou Kevin Chapuis Nghi Huyng Quang Doanh Nguyen Ngoc Arthur Brugière Pierre Larmande Marc Choisy Damien Philippon | Published Tuesday, May 26, 2020 | Last modified Wednesday, July 01, 2020In the face of the COVID-19 pandemic, public health authorities around the world have experimented, in a short period of time, with various combinations of interventions at different scales. However, as the pandemic continues to progress, there is a growing need for tools and methodologies to quickly analyze the impact of these interventions and answer concrete questions regarding their effectiveness, range and temporality.
COMOKIT, the COVID-19 modeling kit, is such a tool. It is a computer model that allows intervention strategies to be explored in silico before their possible implementation phase. It can take into account important dimensions of policy actions, such as the heterogeneity of individual responses or the spatial aspect of containment strategies.
In COMOKIT, built using the agent-based modeling and simulation platform GAMA, the profiles, activities and interactions of people, person-to-person and environmental transmissions, individual clinical statuses, public health policies and interventions are explicitly represented and they all serve as a basis for describing the dynamics of the epidemic in a detailed and realistic representation of space.
…
ABODE - Agent Based Model of Origin Destination Estimation
D Levinson | Published Monday, August 29, 2011 | Last modified Saturday, April 27, 2013The agent based model matches origins and destinations using employment search methods at the individual level.
Peer reviewed Collectivities
Nigel Gilbert | Published Tuesday, April 09, 2019 | Last modified Thursday, August 22, 2019The model that simulates the dynamic creation and maintenance of knowledge-based formations such as communities of scientists, fashion movements, and subcultures. The model’s environment is a spatial one, representing not geographical space, but a “knowledge space” in which each point is a different collection of knowledge elements. Agents moving through this space represent people’s differing and changing knowledge and beliefs. The agents have only very simple behaviors: If they are “lonely,” that is, far from a local concentration of agents, they move toward the crowd; if they are crowded, they move away.
Running the model shows that the initial uniform random distribution of agents separates into “clumps,” in which some agents are central and others are distributed around them. The central agents are crowded, and so move. In doing so, they shift the centroid of the clump slightly and may make other agents either crowded or lonely, and they too will move. Thus, the clump of agents, although remaining together for long durations (as measured in time steps), drifts across the view. Lonely agents move toward the clump, sometimes joining it and sometimes continuing to trail behind it. The clumps never merge.
The model is written in NetLogo (v6). It is used as a demonstration of agent-based modelling in Gilbert, N. (2008) Agent-Based Models (Quantitative Applications in the Social Sciences). Sage Publications, Inc. and described in detail in Gilbert, N. (2007) “A generic model of collectivities,” Cybernetics and Systems. European Meeting on Cybernetic Science and Systems Research, 38(7), pp. 695–706.
Displaying 10 of 188 results for "Nuno Pinto" clear search