Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 117 results market clear search
Exploring the aftermath of transition failures: An agent-based model
Gangmin Park Junmin Lee Jisoo Lee Keungoui Kim | Published Friday, March 06, 2026This computational model is an agent-based model (ABM) developed to investigate how repeated failures of emerging niches accumulate and influence the trajectory of socio-technical transitions. Built in AnyLogic 8.7.11, the model simulates the dynamic interactions between a dominant regime and sequential niche entrants within a two-dimensional practice space. It models alignment, movement, and competition based on technological maturity and market penetration. The model utilizes a reinforcing feedback structure linking consumer support, output, resource accumulation, and capacity development (Physical and Institutional Capacity). A complete model specification following the ODD+D (Overview, Design concepts, Details, and Decision) protocol is included in the documentation.
Peer reviewed Green Consumption Tipping Point
Mario | Published Thursday, February 26, 2026This model is a minimal agent-based model (ABM) of green consumption and market tipping dynamics in a stylised two-firm economy. It is designed as an existence proof to illustrate how weak individual preferences, when combined with habit formation, social influence, and firm price adaptation, can generate non-linear transitions (tipping points) in market outcomes.
The economy consists of:
1) Two firms, each supplying a differentiated consumption bundle that differs in its fixed green share (one relatively greener, one less green).
2) Many households, each consuming a unit mass per period and allocating consumption between the two firms.
…
Bargaining with misvaluation
Marcin Czupryna | Published Wednesday, January 14, 2026Subjective biases and errors systematically affect market equilibria, whether at the population level or in bilateral trading. Here, we consider the possibility that an agent engaged in bilateral trading is mistaken about her own valuation of the good she expects to trade, that has not been explicitly incorporated into the existing bilateral trade literature. Although it may sound paradoxical that a subjective private valuation is something an agent can be mistaken about, as it is up to her to fix it, we consider the case in which that agent, seller or buyer, consciously or not, given the structure of a market, a type of good, and a temporary lack of information, may arrive at an erroneous valuation. The typical context through which this possibility may arise is in relation with so-called experience goods, which are sold while all their intrinsic qualities are still unknown (such as untasted bottled fine wines). We model this “private misvaluation” phenomenon in our study. The agents may also be mistaken about how their exchange counterparties are themselves mistaken. Formally, they attribute a certain margin of error to the other agent, which can differ from the actual way that another agent misvalues the good under consideration. This can constitute the source of a second-order misvaluation. We model different attitudes and situations in which agents face unexpected signals from their counterparties and the manner and extent to which they revise their initial beliefs. We analyse and simulate numerically the consequences of first-order and second-order misvaluation on market equilibria.
Peer reviewed E³-MAN. An Institutionally-guided multi-agent. Model for fair and efficient negotiation.
José luis bustelo | Published Monday, September 01, 2025Negotiation plays a fundamental role in shaping human societies, underpinning conflict resolution, institutional design, and economic coordination. This article introduces E³-MAN, a novel multi-agent model for negotiation that integrates individual utility maximization with fairness and institutional legitimacy. Unlike classical approaches grounded solely in game theory, our model incorporates Bayesian opponent modeling, transfer learning from past negotiation domains, and fallback institutional rules to resolve deadlocks. Agents interact in dynamic environments characterized by strategic heterogeneity and asymmetric information, negotiating over multidimensional issues under time constraints. Through extensive simulation experiments, we compare E³-MAN against the Nash bargaining solution and equal-split baselines using key performance metrics: utilitarian efficiency, Nash social welfare, Jain fairness index, Gini coefficient, and institutional compliance. Results show that E³-MAN achieves near-optimal efficiency while significantly improving distributive equity and agreement stability. A legal application simulating multilateral labor arbitration demonstrates that institutional default rules foster more balanced outcomes and increase negotiation success rates from 58% to 98%. By combining computational intelligence with normative constraints, this work contributes to the growing field of socially aware autonomous agents. It offers a virtual laboratory for exploring how simple institutional interventions can enhance justice, cooperation, and robustness in complex socio-legal systems.
This agent-based model (ABM), developed in NetLogo and available on the COMSES repository, simulates a stylized, competitive electricity market to explore the effects of carbon pricing policies under conditions of technological innovation. Unlike traditional models that treat innovation as exogenous, this ABM incorporates endogenous innovation dynamics, allowing clean technology costs to evolve based on cumulative deployment (Wright’s Law) or time (Moore’s Law). Electricity generation companies act as agents, making investment decisions across coal, gas, wind, and solar PV technologies based on expected returns and market conditions. The model evaluates three policy scenarios—No Policy, Emissions Trading System (ETS), and Carbon Tax—within a merit-order market framework. It is partially empirically grounded, using real-world data for technology costs and emissions caps. By capturing emergent system behavior, this model offers a flexible and transparent tool for analyzing the transition to low-carbon electricity systems.
FilterBubbles_in_Carley1991
Benoît Desmarchelier | Published Wednesday, May 21, 2025The model is an extension of: Carley K. (1991) “A theory of group stability”, American Sociological Review, vol. 56, pp. 331-354.
The original model from Carley (1991) works as follows:
- Agents know or ignore a series of knowledge facts;
- At each time step, each agent i choose a partner j to interact with at random, with a probability of choice proportional to the degree of knowledge facts they have in common.
- Agents interact synchronously. As such, interaction happens only if the partnert j is not already busy interacting with someone else.
…
Transfer of Development Rights (TDR) Simulation for Compact Urban Growth in Dublin: An Agent-Based Model in NetLogo
ajithvyas | Published Wednesday, May 14, 2025This agent-based model simulates the implementation of a Transfer of Development Rights (TDR) mechanism in a stylized urban environment inspired by Dublin. It explores how developer agents interact with land parcels under spatial zoning, conservation protections, and incentive-based policy rules. The model captures emergent outcomes such as compact growth, green and heritage zone preservation, and public cost-efficiency. Built in NetLogo, the model enables experimentation with variable FSI bonuses, developer behavior, and spatial alignment of sending/receiving zones. It is intended as a policy sandbox to test market-aligned planning tools under behavioral and spatial uncertainty.
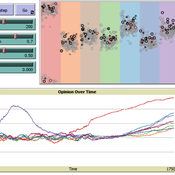
Social Innovation Model
Jiin Jung | Published Monday, April 28, 2025This research aims to uncover the micro-mechanisms that drive the macro-level relationship between cultural tolerance and innovation. We focus on the indirect influence of minorities—specifically, workers with diverse domain expertise—within collaboration networks. We propose that minority influence from individuals with different expertise can serve as a key driver of organizational innovation, particularly in dynamic market environments, and that cultural tolerance is critical for enabling such minority-induced innovation. Our model demonstrates that seemingly conflicting empirical patterns between cultural tightness/looseness and innovation can emerge from the same underlying micro-mechanisms, depending on parameter values. A systematic simulation experiment revealed an optimal cultural configuration: a medium level of tolerance (t = 0.6) combined with low consistency (κ = 0.05) produced the fastest adaptation to abrupt market changes. These findings provide evidence that indirect minority influence is a core micro-mechanism linking cultural tolerance to innovation.
Finance and Market Concentration Using Agent-Based Modeling: Evidence from South Korea
Yunkyeong Seo Zeynep Elif Altiner Sumin Lee Ilchul Moon Taesub Yun | Published Friday, March 28, 2025Amidst the global trend of increasing market concentration, this paper examines the role of finance
in shaping it. Using Agent-Based Modeling (ABM), we analyze the impact of financial policies on market concentration
and its closely related variables: economic growth and labor income share. We extend the Keynes
meets Schumpeter (K+S) model by incorporating two critical assumptions that influence market concentration.
Policy experiments are conducted with a model validated against historical trends in South Korea. For policy
variables, the Debt-to-Sales Ratio (DSR) limit and interest rate are used as levers to regulate the quantity and
…
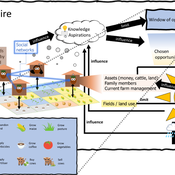
3spire: an agent-based model for exploring aspiration adaptation theory and its implications on smallholder farmers in Ethiopia
ateeuw Yue Dou Markus A Meyer Andrew Nelson | Published Sunday, February 16, 20253spire is an ABM where farming households make management decisions aimed at satisficing along the aspirational dimensions: food self-sufficiency, income, and leisure. Households decision outcomes depend on their social networks, knowledge, assets, household needs, past management, and climate/market trends
Displaying 10 of 117 results market clear search