About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 29 results for 'Michael Livingston'

Foragers to Farmers
Michael Storozum Elske van der Vaart Tim Dorscheidt Nicolas Gauthier | Published Monday, July 22, 2024This model is represents an effort to replicate one of the first attempts (van der Vaart 2006) to develop an agent based model of agricultural origins using principles and equations drawn from human behavioral ecology. We have taken one theory of habitat choice (Ideal Free Distribution) and applied it to human behavioral adaptations to differences in resource quality of different habitats.
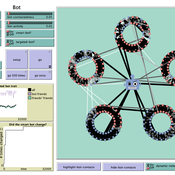
How do bots influence beliefs on social media? Why do beliefs propagated by social bots spread far and wide, yet does their direct influence appear to be limited?
This model extends Axelrod’s model for the dissemination of culture (1997), with a social bot agent–an agent who only sends information and cannot be influenced themselves. The basic network is a ring network with N agents connected to k nearest neighbors. The agents have a cultural profile with F features and Q traits per feature. When two agents interact, the sending agent sends the trait of a randomly chosen feature to the receiving agent, who adopts this trait with a probability equal to their similarity. To this network, we add a bot agents who is given a unique trait on the first feature and is connected to a proportion of the agents in the model equal to ‘bot-connectedness’. At each timestep, the bot is chosen to spread one of its traits to its neighbors with a probility equal to ‘bot-activity’.
The main finding in this model is that, generally, bot activity and bot connectedness are both negatively related to the success of the bot in spreading its unique message, in equilibrium. The mechanism is that very active and well connected bots quickly influence their direct contacts, who then grow too dissimilar from the bot’s indirect contacts to quickly, preventing indirect influence. A less active and less connected bot leaves more space for indirect influence to occur, and is therefore more successful in the long run.
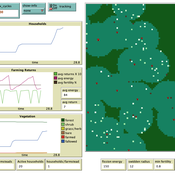
Swidden farming by individual households
C Michael Barton | Published Sunday, April 27, 2008 | Last modified Saturday, April 27, 2013Swidden Farming is designed to explore the dynamics of agricultural land management strategies.
Peer reviewed ABM to create populations with realistic Big Five Personality Trait Expressions
Michael Vogrin | Published Tuesday, May 30, 2023This model aims at creating agent populations that have “personalities”, as described by the Big Five Model of Personality. The expression of the Big Five in the agent population has the following properties, so that they resemble real life populations as closely as possible:
-The population mean of each trait is 0.5 on a scale from 0 to 1.
-The population-wide distribution of each trait approximates a normal distribution.
-The intercorrelations of the Big Five are close to those observed in the Literature.
The literature used to fit the model was a publication by Dimitri van der Linden, Jan te Nijenhuis, and Arnold B. Bakker:
…
Confirmation Bias improves Performance in a Signal Detection Task and evolves in an Evolutionary Algorithm
Michael Vogrin | Published Monday, May 08, 2023Confirmation Bias is usually seen as a flaw of the human mind. However, in some tasks, it may also increase performance. Here, agents are confronted with a number of binary Signals (A, or B). They have a base detection rate, e.g. 50%, and after they detected one signal, they get biased towards this type of signal. This means, that they observe that kind of signal a bit better, and the other signal a bit worse. This is moderated by a variable called “bias_effect”, e.g. 10%. So an agent who detects A first, gets biased towards A and then improves its chance to detect A-signals by 10%. Thus, this agent detects A-Signals with the probability of 50%+10% = 60% and detects B-Signals with the probability of 50%-10% = 40%.
Given such a framework, agents that have the ability to be biased have better results in most of the scenarios.
Scholars have written extensively about hierarchical international order, on the one hand, and war on the other, but surprisingly little work systematically explores the connection between the two. This disconnect is all the more striking given that empirical studies have found a strong relationship between the two. We provide a generative computational network model that explains hierarchy and war as two elements of a larger recursive process: The threat of war drives the formation of hierarchy, which in turn shapes states’ incentives for war. Grounded in canonical theories of hierarchy and war, the model explains an array of known regularities about hierarchical order and conflict. Surprisingly, we also find that many traditional results of the IR literature—including institutional persistence, balancing behavior, and systemic self-regulation—emerge from the interplay between hierarchy and war.
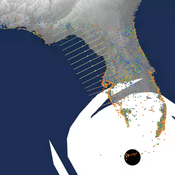
Peer reviewed CHIME ABM of Hurricane Evacuation
Sean Bergin C Michael Barton Joshua Watts Joshua Alland Rebecca Morss | Published Monday, October 18, 2021 | Last modified Tuesday, January 04, 2022The Communicating Hazard Information in the Modern Environment (CHIME) agent-based model (ABM) is a Netlogo program that facilitates the analysis of information flow and protective decisions across space and time during hazardous weather events. CHIME ABM provides a platform for testing hypotheses about collective human responses to weather forecasts and information flow, using empirical data from historical hurricanes. The model uses real world geographical and hurricane data to set the boundaries of the simulation, and it uses historical hurricane forecast information from the National Hurricane Center to initiate forecast information flow to citizen agents in the model.

Simulating Components of the Reinforcing Spirals Model and Spiral of Silence
František Kalvas Ashley Sanders-Jackson Michael D. Slater | Published Friday, November 05, 2021Communication processes occur in complex dynamic systems impacted by person attitudes and beliefs, environmental affordances, interpersonal interactions and other variables that all change over time. Many of the current approaches utilized by Communication researchers are unable to consider the full complexity of communication systems or the over time nature of our data. We apply agent-based modeling to the Reinforcing Spirals Model and the Spiral of Silence to better elucidate the complex and dynamic nature of this process. Our preliminary results illustrate how environmental affordances (i.e. social media), closeness of the system and probability of outspokenness may impact how attitudes change over time. Additional analyses are also proposed.
Sensitivity of the Deffuant model to measurement error
Dino Carpentras | Published Monday, June 07, 2021This code can be used to analyze the sensitivity of the Deffuant model to different measurement errors. Specifically to:
- Intrinsic stochastic error
- Binning of the measurement scale
- Random measurement noise
- Psychometric distortions
…
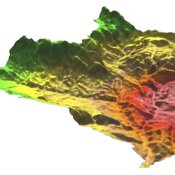
MedLanD Modeling Laboratory
C Michael Barton Isaac Ullah Gary Mayer Sean Bergin Hessam Sarjoughian Helena Mitasova | Published Friday, May 08, 2015 | Last modified Thursday, December 14, 2017The MML is a hybrid modeling environment that couples an agent-based model of small-holder agropastoral households and a cellular landscape evolution model that simulates changes in erosion/deposition, soils, and vegetation.
Displaying 10 of 29 results for 'Michael Livingston'