Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 26 results culture clear search
FilterBubbles_in_Carley1991
Benoît Desmarchelier | Published Wednesday, May 21, 2025The model is an extension of: Carley K. (1991) “A theory of group stability”, American Sociological Review, vol. 56, pp. 331-354.
The original model from Carley (1991) works as follows:
- Agents know or ignore a series of knowledge facts;
- At each time step, each agent i choose a partner j to interact with at random, with a probability of choice proportional to the degree of knowledge facts they have in common.
- Agents interact synchronously. As such, interaction happens only if the partnert j is not already busy interacting with someone else.
…
Hyperconnectivity, and Fact-Checking- Modeling Witnessing as a Traditional Coast Salish Mechanism
Adam Rorabaugh | Published Thursday, May 01, 2025An unintended consequence of low cost maritime travel may be hyperconnectedness, creating social situations where information can be readily passed before it is verified- an issue not limited to modern digitally connected societies. In traditional Coast Salish societies, the peoples of what is now Western Washington and Southwestern British Columbia, oral traditions were vertified through a process called witnessing. Witnesses would be trained to recount and verify oral history and traditional teachings at high fidelity. Here, a simple model based on dual inheritance approaches to genes and culture, is used to compare this specific form of verifying socially important information compared to modern mass communication. The model suggests that witnessing is a high fidelity form of transmitting knowledge with a low error rate, more in line with modern apprenticeships than mass communication. Social mechanisms such as witnessing provide solutions to issues faced in contemporary discourse where the validity of information and even fact checking mechanisms may be biased or counterfactual. This effort also demonstrates the utillity of using modeling approaches to highlight how specific, historically contingent institutions such as witnesses can be drawn upon to model potential solutions to contemporary issues solved in the past in traditional Coast Salish practice.
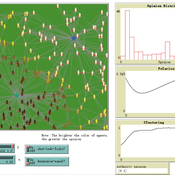
How Does Culture Affect Vaccination Opinion Polarisation?
Teng Li | Published Monday, March 10, 2025This model is to explore how individuals’ cultural backgrounds may play a role in their Covid vaccination decision-making. Two cultural dimensions of collectivism/individualism and power distance are considered. Through the experimental scenarios, we find that Covid-vaccination opinions in collectivist societies can also be considerably polarised, if the power distance is less and authorities less centralised. This result complements the popular idea that cultural collectivism is usually associated with a high degree of social consensus. Hopefully, this study will help explain countries’ difference in the response of Covid vaccination programs.
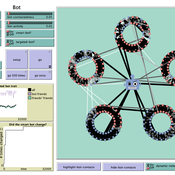
How do bots influence beliefs on social media? Why do beliefs propagated by social bots spread far and wide, yet does their direct influence appear to be limited?
This model extends Axelrod’s model for the dissemination of culture (1997), with a social bot agent–an agent who only sends information and cannot be influenced themselves. The basic network is a ring network with N agents connected to k nearest neighbors. The agents have a cultural profile with F features and Q traits per feature. When two agents interact, the sending agent sends the trait of a randomly chosen feature to the receiving agent, who adopts this trait with a probability equal to their similarity. To this network, we add a bot agents who is given a unique trait on the first feature and is connected to a proportion of the agents in the model equal to ‘bot-connectedness’. At each timestep, the bot is chosen to spread one of its traits to its neighbors with a probility equal to ‘bot-activity’.
The main finding in this model is that, generally, bot activity and bot connectedness are both negatively related to the success of the bot in spreading its unique message, in equilibrium. The mechanism is that very active and well connected bots quickly influence their direct contacts, who then grow too dissimilar from the bot’s indirect contacts to quickly, preventing indirect influence. A less active and less connected bot leaves more space for indirect influence to occur, and is therefore more successful in the long run.
ABM Simulation of Transition from Late Longshan Cultures to Early Erlitou Culture
Carmen Iasiello | Published Sunday, November 26, 2023Within the archeological record for Bronze Age Chinese culture, there continues to be a gap in our understanding of the sudden rise of the Erlitou State from the previous late Longshan chiefdoms. In order to examine this period, I developed and used an agent-based model (ABM) to explore possible socio-politically relevant hypotheses for the gap between the demise of the late Longshan cultures and rise of the first state level society in East Asia. I tested land use strategy making and collective action in response to drought and flooding scenarios, the two plausible environmental hazards at that time. The model results show cases of emergent behavior where an increase in social complexity could have been experienced if a catastrophic event occurred while the population was sufficiently prepared for a different catastrophe, suggesting a plausible lead for future research into determining the life of the time period.
The ABM published here was originally developed in 2016 and its results published in the Proceedings of the 2017 Winter Simulation Conference.

Peer reviewed COMMONSIM: Simulating the utopia of COMMONISM
Lena Gerdes Manuel Scholz-Wäckerle Ernest Aigner Stefan Meretz Jens Schröter Hanno Pahl Annette Schlemm Simon Sutterlütti | Published Sunday, November 05, 2023This research article presents an agent-based simulation hereinafter called COMMONSIM. It builds on COMMONISM, i.e. a large-scale commons-based vision for a utopian society. In this society, production and distribution of means are not coordinated via markets, exchange, and money, or a central polity, but via bottom-up signalling and polycentric networks, i.e. ex-ante coordination via needs. Heterogeneous agents care for each other in life groups and produce in different groups care, environmental as well as intermediate and final means to satisfy sensual-vital needs. Productive needs decide on the magnitude of activity in groups for a common interest, e.g. the production of means in a multi-sectoral artificial economy. Agents share cultural traits identified by different behaviour: a propensity for egoism, leisure, environmentalism, and productivity. The narrative of this utopian society follows principles of critical psychology and sociology, complexity and evolution, the theory of commons, and critical political economy. The article presents the utopia and an agent-based study of it, with emphasis on culture-dependent allocation mechanisms and their social and economic implications for agents and groups.

Peer reviewed ArchMatNet: Archaeological Material Networks
Claudine Gravel-Miguel Robert Bischoff Cecilia Padilla-Iglesias | Published Monday, February 20, 2023The purpose of the model is to investigate how different factors affect the ability of researchers to reconstruct prehistoric social networks from artifact stylistic similarities, as well as the overall diversity of cultural traits observed in archaeological assemblages. Given that cultural transmission and evolution is affected by multiple interacting phenomena, our model allows to simultaneously explore six sets of factors that may condition how social networks relate to shared culture between individuals and groups:
- Factors relating to the structure of social groups
- Factors relating to the cultural traits in question
- Factors relating to individual learning strategies
- Factors relating to the environment
…
Evolutionary Model of Subculture Choice
Diogo Alves | Published Monday, December 19, 2022This is an original model of (sub)culture diffusion.
It features a set of agents (dubbed “partygoers”) organized initially in clusters, having properties such as age and a chromosome of opinions about 6 different topics. The partygoers interact with a set of cultures (also having a set of opinions subsuming those of its members), in the sense of refractory or unhappy members of each setting about to find a new culture and trading information encoded in the genetic string (originally encoded as -1, 0, and 1, resp. a negative, neutral, and positive opinion about each of the 6 traits/aspects, e.g. the use of recreational drugs). There are 5 subcultures that both influence (through the aforementioned genetic operations of mutation and recombination of chromosomes simulating exchange of opinions) and are influenced by its members (since a group is a weighted average of the opinions and actions of its constituents). The objective of this feedback loop is to investigate under which conditions certain subculture sizes emerge, but the model is open to many other kinds of explorations as well.
Agent-based simulation of discussion processes in risk workshops with quantitative skepticism
Matthias Meyer Clemens Harten Lucia Bellora-Bienengräber | Published Sunday, August 14, 2022The model measures drivers of effectiveness of risk assessments in risk workshops where a calculative culture of quantitative skepticism is present. We model the limits to information transfer, incomplete discussions, group characteristics, and interaction patterns and investigate their effect on risk assessment in risk workshops, in order to contrast results to a previous model focused on a calculative culture of quantitative enthusiasm.
The model simulates a discussion in the context of a risk workshop with 9 participants. The participants use constraint satisfaction networks to assess a given risk individually and as a group.

Peer reviewed Social Consequences of Past Compound Events - Laacher See Eruption
Kevin Su Brennen Bouwmeester | Published Monday, May 17, 2021Resilience of humans in the Upper Paleolithic could provide insights in how to defend against today’s environmental threats. Approximately 13,000 years ago, the Laacher See volcano located in present-day western Germany erupted cataclysmically. Archaeological evidence suggests that this is eruption – potentially against the background of a prolonged cold spell – led to considerable culture change, especially at some distance from the eruption (Riede, 2017). Spatially differentiated and ecologically mediated effects on contemporary social networks as well as social transmission effects mediated by demographic changes in the eruption’s wake have been proposed as factors that together may have led to, in particular, the loss of complex technologies such as the bow-and-arrow (Riede, 2014; Riede, 2009).
This model looks at the impact of the interaction between climate change trajectory and an extreme event, such as the Laacher See eruption, on the generational development of hunter-gatherer bands. Historic data is used to model the distribution and population dynamics of hunter-gatherer bands during these circumstances.
Displaying 10 of 26 results culture clear search