Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 39 results diversity clear search
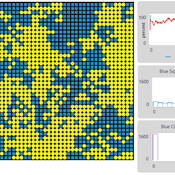
The current model is designed to examine whether—and under what conditions—minority influence can generate social change. Specifically, the model assesses whether empirically validated psychological mechanisms of indirect minority influence, operating in combination, can produce system-level social change, defined as the initial minority opinion becoming the majority position. Notably, this model formalizes Moscovici’s (1976) genetic model of social influence using agent-based modeling.
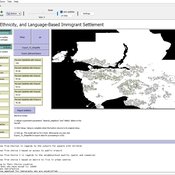
Geospatial Agent-Based Model of Immigrant Settlement Dynamics in Metro Vancouver
Liliana Perez Navid Mahdizadeh Gharakhanlou Maryam Yousefi | Published Wednesday, December 03, 2025This agent-based model simulates how new immigrant households choose where to live in Metro Vancouver under the origins diversity scenario. The model begins with 16,000 household agents, reflecting an expected annual population increase of about 42,500 people based on an average household size of 2.56. Each agent is assigned four characteristics: one of ten origin categories, income level (adjusted using NOC data and recent immigrant earnings), likelihood of having children, and preferred mode of commuting. The ten origin groups are drawn from Census patterns, including six subgroups within the broader Asian category (China, India, the Philippines, Iran, South Korea, and Other Asian countries) and two categories for immigrants from the Americas. This refined classification better captures the diversity of newcomers arriving in the region.
An agent-based model exploring the biodiversity-agriculture-nutrition dynamics in Eastern Madagascar resulting from alternative land uses
Romain Clercq-Roques Jessica Williams Katja Perez Guzman Marta Kozicka Kristine Belesova Zaid Chalabi | Published Wednesday, July 23, 2025This agent-based model simulates the interactions between smallholder farming households, land-use dynamics, and ecosystem services in a rural landscape of Eastern Madagascar. It explores how alternative agricultural practices —shifting agriculture, rice cultivation, and agroforestry—combined with varying levels of forest protection, influence food production, food security, dietary diversity, and forest biodiversity over time. The landscape is represented as a grid of spatially explicit patches characterized by land use, ecological attributes, and regeneration dynamics. Agents make yearly decisions on land management based on demographic pressures, agricultural returns, and institutional constraints. Crop yields are affected by stochastic biotic and abiotic disruptions, modulated by local ecosystem regulation functions. The model additionally represents foraging as a secondary food source and pressure on biodiversity. The model supports the analysis of long-term trade-offs between agricultural productivity, human nutrition, and conservation under different policy and land-use scenarios.
An Agent-Based Model of Indirect Minority Influence on Social Change
Jiin Jung | Published Wednesday, February 05, 2025This model demonstrates how different psychological mechanisms and network structures generate various patterns of cultural dynamics including cultural diversity, polarization, and majority dominance, as explored by Jung, Bramson, Crano, Page, and Miller (2021). It focuses particularly on the psychological mechanisms of indirect minority influence, a concept introduced by Serge Moscovici (1976, 1980)’s genetic model of social influence, and validates how such influence can lead to social change.
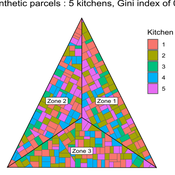
MeReDiem : Fallow Land Simulations to examine the conditions of sustainable village livelihood
Etienne DELAY Paul Chapron Mathieu | Published Monday, January 20, 2025 | Last modified Tuesday, January 21, 2025The MeReDiem model aims to simulate the effect of socio-agricultural practices of farmers and pastors on the food sustainability and soil fertility of a serrer village, in Senegal. The model is a central part of a companion modeling and exploration approach, described in a paper, currently under review)
The village population is composed of families (kitchens). Kitchens cultivate their land parcels to feed their members, aiming for food security at the family level. On a global level , the village tries to preserve the community fallow land as long as possible.
Kitchens sizes vary depending on the kitchens food production, births and migration when food is insufficient.
…
Cultural transmission in structured populations
Luke Premo | Published Wednesday, November 13, 2024This structured population model is built to address how migration (or intergroup cultural transmission), copying error, and time-averaging affect regional variation in a single selectively neutral discrete cultural trait under different mechanisms of cultural transmission. The model allows one to quantify cultural differentiation between groups within a structured population (at equilibrium) as well as between regional assemblages of time-averaged archaeological material at two different temporal scales (1,000 and 10,000 ticks). The archaeological assemblages begin to accumulate only after a “burn-in” period of 10,000 ticks. The model includes two different representations of copying error: the infinite variants model of copying error and the finite model of copying error. The model also allows the user to set the variant ceiling value for the trait in the case of the finite model of copying error.
EU language skills
Marco Civico | Published Sunday, July 07, 2024The objective of this agent-based model is to test different language education orientations and their consequences for the EU population in terms of linguistic disenfranchisement, that is, the inability of citizens to understand EU documents and parliamentary discussions should their native language(s) no longer be official. I will focus on the impact of linguistic distance and language learning. Ideally, this model would be a tool to help EU policy makers make informed decisions about language practices and education policies, taking into account their consequences in terms of diversity and linguistic disenfranchisement. The model can be used to force agents to make certain choices in terms of language skills acquisition. The user can then go on to compare different scenarios in which language skills are acquired according to different rationales. The idea is that, by forcing agents to adopt certain language learning strategies, the model user can simulate policies promoting the acquisition of language skills and get an idea of their impact. In this way the model allows not only to sketch various scenarios of the evolution of language skills among EU citizens, but also to estimate the level of disenfranchisement in each of these scenarios.
The influence of cognitive diversity on networked search and coordination
César García-Díaz | Published Wednesday, April 03, 2024Agent-based models of organizational search have long investigated how exploitative and exploratory behaviors shape and affect performance on complex landscapes. To explore this further, we build a series of models where agents have different levels of expertise and cognitive capabilities, so they must rely on each other’s knowledge to navigate the landscape. Model A investigates performance results for efficient and inefficient networks. Building on Model B, it adds individual-level cognitive diversity and interaction based on knowledge similarity. Model C then explores the performance implications of coordination spaces. Results show that totally connected networks outperform both hierarchical and clustered network structures when there are clear signals to detect neighbor performance. However, this pattern is reversed when agents must rely on experiential search and follow a path-dependent exploration pattern.
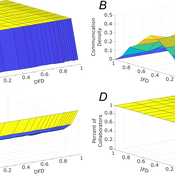
Role of Diversity in Team Performance: the Case of Missing Expertise, an Agent Based Simulations
Tamás Kiss | Published Friday, December 29, 2023This ABM simulates problem solving agents as they work on a set of tasks. Each agent has a trait vector describing their skills. Two agents might form a collaboration if their traits are similar enough. Tasks are defined by a component vector. Agents work on tasks by decreasing tasks’ component vectors towards zero.
The simulation generates agents with given intrapersonal functional diversity (IFD), and dominant function diversity (DFD), and a set of random tasks and evaluates how agents’ traits influence their level of communication and the performance of a team of agents.
Modeling results highlight the importance of the distributions of agents’ properties forming a team, and suggests that for a thorough description of management teams, not only diversity measures based on individual agents, but an aggregate measure is also required.
…
Peer reviewed Yards
srailsback Emily Minor Soraida Garcia Philip Johnson | Published Thursday, November 02, 2023This is a model of plant communities in urban and suburban residential neighborhoods. These plant communities are of interest because they provide many benefits to human residents and also provide habitat for wildlife such as birds and pollinators. The model was designed to explore the social factors that create spatial patterns in biodiversity in yards and gardens. In particular, the model was originally developed to determine whether mimicry behaviors–-or neighbors copying each other’s yard design–-could produce observed spatial patterns in vegetation. Plant nurseries and socio-economic constraints were also added to the model as other potential sources of spatial patterns in plant communities.
The idea for the model was inspired by empirical patterns of spatial autocorrelation that have been observed in yard vegetation in Chicago, Illinois (USA), and other cities, where yards that are closer together are more similar than yards that are farther apart. The idea is further supported by literature that shows that people want their yards to fit into their neighborhood. Currently, the yard attribute of interest is the number of plant species, or species richness. Residents compare the richness of their yards to the richness of their neighbors’ yards. If a resident’s yard is too different from their neighbors, the resident will be unhappy and change their yard to make it more similar.
The model outputs information about the diversity and identity of plant species in each yard. This can be analyzed to look for spatial autocorrelation patterns in yard diversity and to explore relationships between mimicry behaviors, yard diversity, and larger scale diversity.
Displaying 10 of 39 results diversity clear search