Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 532 results for "Jingjing Cai" clear search
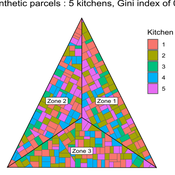
MeReDiem : Fallow Land Simulations to examine the conditions of sustainable village livelihood
Etienne DELAY Paul Chapron Mathieu | Published Monday, January 20, 2025 | Last modified Tuesday, January 21, 2025The MeReDiem model aims to simulate the effect of socio-agricultural practices of farmers and pastors on the food sustainability and soil fertility of a serrer village, in Senegal. The model is a central part of a companion modeling and exploration approach, described in a paper, currently under review)
The village population is composed of families (kitchens). Kitchens cultivate their land parcels to feed their members, aiming for food security at the family level. On a global level , the village tries to preserve the community fallow land as long as possible.
Kitchens sizes vary depending on the kitchens food production, births and migration when food is insufficient.
…
Peer reviewed The effect of homophily on co-offending outcomes
Ruslan Klymentiev Christophe Vandeviver Luis E. C. Rocha | Published Friday, September 26, 2025This Agent-Based Model is designed to simulate how similarity-based partner selection (homophily) shapes the formation of co-offending networks and the diffusion of skills within those networks. Its purpose is to isolate and test the effects of offenders’ preference for similar partners on network structure and information flow, under controlled conditions.
In the model, offenders are represented as agents with an individual attribute and a set of skills. At each time step, agents attempt to select partners based on similarity preference. When two agents mutually select each other, they commit a co-offense, forming a tie and exchanging a skill. The model tracks the evolution of network properties (e.g., density, clustering, and tie strength) as well as the spread of skills over time.
This simple and theoretical model does not aim to produce precise empirical predictions but rather to generate insights and test hypotheses about the trade-off between partnership stability and information diffusion. It provides a flexible framework for exploring how changes in partner selection preferences may lead to differences in criminal network dynamics. Although the model was developed to simulate offenders’ interactions, in principle, it could be applied to other social processes involving social learning and skills exchange.
…

MASTOC-LLM (Multi-Agent System Tragedy of the Commons - Large Language Models)
Thomas Tuoti | Published Monday, May 18, 2026 | Last modified Tuesday, May 19, 2026MASTOC-LLM extends the classic Multi-Agent System Tragedy of the Commons (MASTOC) model by replacing hard-coded behavioral rules with autonomous decision-making powered by large language models (LLMs). Three heterogeneous agents manage herds of cows on a shared grassland commons. Each tick, an agent receives a structured prompt describing current resource levels, its own herd size, peer behavior, and — optionally — a rolling memory of recent rounds and messages from neighboring agents. The LLM returns a stocking decision (add, remove, or hold cows) together with a natural-language rationale and, when communication is enabled, a short message to broadcast to peers.
The model is designed to test whether LLM agents spontaneously develop Ostrom-style common-pool resource governance (mutual monitoring, graduated sanctions, graduated rule revision) or instead fall into identifiable failure modes. Preliminary experiments with Claude Haiku 4.5, GPT-5.4-mini, and DeepSeek R1:32b have revealed four recurring collapse patterns — Cooperative Paralysis, Defection Cascade, Overshoot-Panic, and Hybrid Architecture Failure — whose onset timing is sensitive to memory length, inter-agent communication, and the post-training alignment approach of the underlying model.
MASTOC-LLM is intended as a laboratory for generative agent-based modelling (GABM) methodology: it provides a clean, well-understood commons baseline against which LLM behavioral hypotheses can be systematically tested and compared across models, parameter sweeps, and alignment regimes.
Peer reviewed Hohokam Trade Networks Model
Joshua Watts | Published Sunday, October 26, 2014The Hohokam Trade Networks Model focuses on key features of the Hohokam economy to explore how differences in trade network topologies may show up in the archaeological record. The model is set in the Phoenix Basin of central Arizona, AD 200-1450.
A Multi-level Multi-model of Collective Motion
Benjamin Camus Christine Bourjot Vincent Chevrier | Published Wednesday, March 25, 2015This multi-model (i.e. a model composed of interacting submodels) is a multi-level representation of a collective motion phenomenon. It was designed to study the impact of the mutual influences between individuals and groups in collective motion.
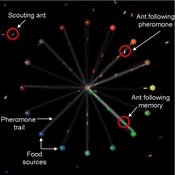
Composite Collective Decision Making - ant colony foraging model
Tomer Czaczkes Benjamin I Czaczkes | Published Thursday, December 17, 2015The model explores how two types of information - social (in the form of pheromone trails) and private (in the form of route memories) affect ant colony level foraging in a variable enviroment.
Relative Agreement Model and Network Structure
Spiro Maroulis David Adelberg | Published Friday, January 29, 2016This adaptation of the Relative Agreement model of opinion dynamics (Deffuant et al. 2002) extends the Meadows and Cliff (2012) implementation of this model in a manner that explores the effect of the network structure among the agents.
Hybrid Climate Assessment Model (HCAM)
Peer-Olaf Siebers | Published Friday, February 15, 2019Our Hybrid Climate Assessment Model (HCAM) aims to simulate the behaviours of individuals under the influence of climate change and external policy makings. In our proposed solution we use System Dynamics (SD) modelling to represent the physical and economic environments. Agent-Based (AB) modelling is used to represent collections of individuals that can interact with other collections of individuals and the environment. In turn, individual agents are endowed with an internal SD model to track their psychological state used for decision making. In this paper we address the feasibility of such a scalable hybrid approach as a proof-of-concept. This novel approach allows us to reuse existing rigid, but well-established Integrated Assessment Models (IAMs), and adds more flexibility by replacing aggregate stocks with a community of vibrant interacting entities.
Our illustrative example takes the settings of the U.S., a country that contributes to the majority of the global carbon footprints and that is the largest economic power in the world. The model considers the carbon emission dynamics of individual states and its relevant economic impacts on the nation over time.
Please note that the focus of the model is on a methodological advance rather than on applying it for predictive purposes! More details about the HCAM are provided in the forthcoming JASSS paper “An Innovative Approach to Multi-Method Integrated Assessment Modelling of Global Climate Change”, which is available upon request from the authors (contact [email protected]).
A network agent-based model of ethnocentrism and intergroup cooperation
Ross Gore | Published Sunday, October 27, 2019We present a network agent-based model of ethnocentrism and intergroup cooperation in which agents from two groups (majority and minority) change their communality (feeling of group solidarity), cooperation strategy and social ties, depending on a barrier of “likeness” (affinity). Our purpose was to study the model’s capability for describing how the mechanisms of preexisting markers (or “tags”) that can work as cues for inducing in-group bias, imitation, and reaction to non-cooperating agents, lead to ethnocentrism or intergroup cooperation and influence the formation of the network of mixed ties between agents of different groups. We explored the model’s behavior via four experiments in which we studied the combined effects of “likeness,” relative size of the minority group, degree of connectivity of the social network, game difficulty (strength) and relative frequencies of strategy revision and structural adaptation. The parameters that have a stronger influence on the emerging dominant strategies and the formation of mixed ties in the social network are the group-tag barrier, the frequency with which agents react to adverse partners, and the game difficulty. The relative size of the minority group also plays a role in increasing the percentage of mixed ties in the social network. This is consistent with the intergroup ties being dependent on the “arena” of contact (with progressively stronger barriers from e.g. workmates to close relatives), and with measures that hinder intergroup contact also hindering mutual cooperation.
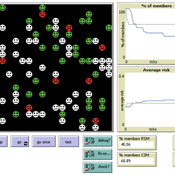
Risk-Sharing under Heterogeneity: NetLogo simulation
Eva Vriens | Published Monday, February 28, 2022Motivated by the emergence of new Peer-to-Peer insurance organizations that rethink how insurance is organized, we propose a theoretical model of decision-making in risk-sharing arrangements with risk heterogeneity and incomplete information about the risk distribution as core features. For these new, informal organisations, the available institutional solutions to heterogeneity (e.g., mandatory participation or price differentiation) are either impossible or undesirable. Hence, we need to understand the scope conditions under which individuals are motivated to participate in a bottom-up risk-sharing setting. The model puts forward participation as a utility maximizing alternative for agents with higher risk levels, who are more risk averse, are driven more by solidarity motives, and less susceptible to cost fluctuations. This basic micro-level model is used to simulate decision-making for agent populations in a dynamic, interdependent setting. Simulation results show that successful risk-sharing arrangements may work if participants are driven by motivations of solidarity or risk aversion, but this is less likely in populations more heterogeneous in risk, as the individual motivations can less often make up for the larger cost deficiencies. At the same time, more heterogeneous groups deal better with uncertainty and temporary cost fluctuations than more homogeneous populations do. In the latter, cascades following temporary peaks in support requests more often result in complete failure, while under full information about the risk distribution this would not have happened.
Displaying 10 of 532 results for "Jingjing Cai" clear search