Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 230 results for "Martin Dribe" clear search
Musical Chairs
Andreas Angourakis | Published Wednesday, February 03, 2016 | Last modified Friday, March 11, 2016This Agent-Based model intends to explore the conditions for the emergence and change of land use patterns in Central Asian oases and similar contexts.
SBH trust model
Di Wang | Published Tuesday, December 14, 2010 | Last modified Saturday, April 27, 2013This is a computational model to articulate the theory and test some assumption and axioms for the trust model and its relationship to SBH.
Heterogeneity of preferences and the dynamics of voluntary contributions to public goods
Engi Amin Amal Soliman Mohamed Abouelela | Published Thursday, August 18, 2016 | Last modified Thursday, January 25, 2018This model simulates the heterogeneity of preferences in a PG game and how the interaction between them affects the dynamics of voluntary contributions. Model is based on the results of a human-based experiment.
OMOLAND-CA: An Agent-Based Modeling of Rural Households’ Adaptation to Climate Change
Atesmachew Hailegiorgis Andrew Crooks Claudio Cioffi-Revilla | Published Tuesday, July 25, 2017 | Last modified Tuesday, July 10, 2018The purpose of the OMOLAND-CA is to investigate the adaptive capacity of rural households in the South Omo zone of Ethiopia with respect to variation in climate, socioeconomic factors, and land-use at the local level.
Peer reviewed AgModel
Isaac Ullah | Published Friday, December 06, 2024AgModel is an agent-based model of the forager-farmer transition. The model consists of a single software agent that, conceptually, can be thought of as a single hunter-gather community (i.e., a co-residential group that shares in subsistence activities and decision making). The agent has several characteristics, including a population of human foragers, intrinsic birth and death rates, an annual total energy need, and an available amount of foraging labor. The model assumes a central-place foraging strategy in a fixed territory for a two-resource economy: cereal grains and prey animals. The territory has a fixed number of patches, and a starting number of prey. While the model is not spatially explicit, it does assume some spatiality of resources by including search times.
Demographic and environmental components of the simulation occur and are updated at an annual temporal resolution, but foraging decisions are “event” based so that many such decisions will be made in each year. Thus, each new year, the foraging agent must undertake a series of optimal foraging decisions based on its current knowledge of the availability of cereals and prey animals. Other resources are not accounted for in the model directly, but can be assumed for by adjusting the total number of required annual energy intake that the foraging agent uses to calculate its cereal and prey animal foraging decisions. The agent proceeds to balance the net benefits of the chance of finding, processing, and consuming a prey animal, versus that of finding a cereal patch, and processing and consuming that cereal. These decisions continue until the annual kcal target is reached (balanced on the current human population). If the agent consumes all available resources in a given year, it may “starve”. Starvation will affect birth and death rates, as will foraging success, and so the population will increase or decrease according to a probabilistic function (perturbed by some stochasticity) and the agent’s foraging success or failure. The agent is also constrained by labor caps, set by the modeler at model initialization. If the agent expends its yearly budget of person-hours for hunting or foraging, then the agent can no longer do those activities that year, and it may starve.
Foragers choose to either expend their annual labor budget either hunting prey animals or harvesting cereal patches. If the agent chooses to harvest prey animals, they will expend energy searching for and processing prey animals. prey animals search times are density dependent, and the number of prey animals per encounter and handling times can be altered in the model parameterization (e.g. to increase the payoff per encounter). Prey animal populations are also subject to intrinsic birth and death rates with the addition of additional deaths caused by human predation. A small amount of prey animals may “migrate” into the territory each year. This prevents prey animals populations from complete decimation, but also may be used to model increased distances of logistic mobility (or, perhaps, even residential mobility within a larger territory).
…
Peer reviewed Small-Trade Model
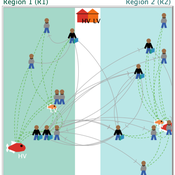
Emilie Lindkvist Maja Schlüter Blanca Gonzalez-Mon Örjan Bodin | Published Wednesday, July 28, 2021The purpose of this model is to understand the role of trade networks and their interaction with different fish resources, for fish provision. The model is developed based on a multi-methods approach, combining agent-based modeling, network analysis and qualitative data based on a small-scale fisheries study case. The model can be used to investigate both how trade network structures are embedded in a social-ecological context and the trade processes that occur within them, to analyze how they lead to emergent outcomes related to the resilience of fish provision. The model processes are informed by qualitative data analysis, and the social network analysis of an empirical fish trade network. The network analysis can be used to investigate diverse network structures to perform model experiments, and their influence on model outcomes.
The main outcomes we study are 1) the overexploitation of fish resources and 2) the availability and variability of fish provision to satisfy different market demands, and 3) individual traders’ fish supply at the micro-level. The model has two types of trader agents, seller and dealer. The model reveals that the characteristics of the trade networks, linked to different trader types (that have different roles in those networks), can affect the resilience of fish provision.

Peer reviewed Share: bottom-up disaster information management
Vittorio Nespeca Tina Comes Frances Brazier | Published Monday, December 05, 2022This model is intended to study the way information is collectively managed (i.e. shared, collected, processed, and stored) in a system and how it performs during a crisis or disaster. Performance is assessed in terms of the system’s ability to provide the information needed to the actors who need it when they need it. There are two main types of actors in the simulation, namely communities and professional responders. Their ability to exchange information is crucial to improve the system’s performance as each of them has direct access to only part of the information they need.
In a nutshell, the following occurs during a simulation. Due to a disaster, a series of randomly occurring disruptive events takes place. The actors in the simulation need to keep track of such events. Specifically, each event generates information needs for the different actors, which increases the information gaps (i.e. the “piles” of unaddressed information needs). In order to reduce the information gaps, the actors need to “discover” the pieces of information they need. The desired behavior or performance of the system is to keep the information gaps as low as possible, which is to address as many information needs as possible as they occur.
An Agent-Based Model for Skilled Workers Migration
Hassan Bashiri | Published Thursday, September 21, 2023This documentation provides an overview and explanation of the NetLogo simulation code for modeling skilled workers’ migration in Iran. The simulation aims to explore the dynamics of skilled workers’ migration and their transition through various states, including training, employment, and immigration.
The flow of elite and talent migration, or “brain drain,” is a complex issue with far-reaching implications for developing countries. The decision to migrate is made due to various factors including economic opportunities, political stability, social factors and personal circumstances.
Measuring individual interests in the field of immigration is a complex task that requires careful consideration of various factors. The agent-based model is a useful tool for understanding the complex factors that are involved in talent migration. By considering the various social, economic, and personal factors that influence migration decisions, policymakers can provide more effective strategies to retain skilled and talented labor and promote sustainable growth in developing countries. One of the main challenges in studying the flow of elite migration is the complexity of the decision-making process and a set of factors that lead to migration decisions. Agent-based modeling is a useful tool for understanding how individual decisions can lead to large-scale migration patterns.
Critical Sustainability Transitions: Relaunching local agriculture after decline (Model code and description)
Pedro Lopez-Merino | Published Tuesday, April 30, 2024This model simulates the dynamics of agricultural land use change, specifically the transition between agricultural and non-agricultural land use in a spatial context. It explores the influence of various factors such as agricultural profitability, path dependency, and neighborhood effects on land use decisions.
The model operates on a grid of patches representing land parcels. Each patch can be in one of two states: exploited (green, representing agricultural land) or unexploited (brown, representing non-agricultural land). Agents (patches) transition between these states based on probabilistic rules. The main factors affecting these transitions are agricultural profitability, path dependency, and neighborhood effects.
-Agricultural Profitability: This factor is determined by the prob-agri function, which calculates the probability of a non-agricultural patch converting to agricultural based on income differences between agriculture and other sectors. -Path Dependency: Represented by the path-dependency parameter, it influences the likelihood of patches changing their state based on their current state. It’s a measure of inertia or resistance to change. -Neighborhood Effects: The neighborhood function calculates the number of exploited (agricultural) neighbors of a patch. This influences the decision of a patch to convert to agricultural land, representing the influence of surrounding land use on the decision-making process.
A simulation model for Dublin city
umesh7lowe | Published Friday, April 10, 2026An agent-based model of urban travel behaviour in Dublin, Ireland, built in NetLogo and empirically grounded in 2016 travel survey data. Each agent represents a Dublin resident initialised with real socio-demographic attributes — including age, gender, household size and car ownership, income, driving licence status, and access to local amenities — alongside observed trip characteristics such as distance, travel time, and trip type (work, shopping, leisure).
At each time step, agents choose between four transport modes (car, public transport, cycling, and walking) across short, medium, and long trips. Mode choice is governed by a preference vector that weighs personal need satisfaction against social influence from neighbouring agents reflecting consumat framework. Satisfaction evolves dynamically based on cost (incorporating Irish motor tax bands and per-km operating rates), travel time, and trip-type suitability, with an uncertainty parameter capturing variability in perceived utility over time.
The model tracks aggregate modal shares and total CO2 emission at each tick, enabling exploration of how policy interventions — such as fuel taxation, public transport pricing, or active travel incentives — might shift the city’s travel demand profile over 100 simulated days.
Displaying 10 of 230 results for "Martin Dribe" clear search