Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 49 results trade clear search
Peer reviewed A dynamic identity model for misinformation in social networks
emdhar | Published Friday, February 27, 2026A dynamic identity model for misinformation in social networks, an agent-based model of social identity and misinformation dynamics.
I developed this model as a part of my master’s thesis, “Does social identity drive belief and persistence in online misinformation? An agent-based modelling approach” at University College Dublin, Ireland (2024-2025).
The purpose of this model is to further understand the dynamics of misinformation sharing as an expression of social identity. I introduce a framework to understand the influence of self-categorisation on misinformation persistence in social network. It integrates a social learning model with the Dynamic Identity Model for Agents (DIMA) using simple logic to simulate the social trade-offs driving misinformation and observe the effects on misinformation spread.
Bargaining with misvaluation
Marcin Czupryna | Published Wednesday, January 14, 2026Subjective biases and errors systematically affect market equilibria, whether at the population level or in bilateral trading. Here, we consider the possibility that an agent engaged in bilateral trading is mistaken about her own valuation of the good she expects to trade, that has not been explicitly incorporated into the existing bilateral trade literature. Although it may sound paradoxical that a subjective private valuation is something an agent can be mistaken about, as it is up to her to fix it, we consider the case in which that agent, seller or buyer, consciously or not, given the structure of a market, a type of good, and a temporary lack of information, may arrive at an erroneous valuation. The typical context through which this possibility may arise is in relation with so-called experience goods, which are sold while all their intrinsic qualities are still unknown (such as untasted bottled fine wines). We model this “private misvaluation” phenomenon in our study. The agents may also be mistaken about how their exchange counterparties are themselves mistaken. Formally, they attribute a certain margin of error to the other agent, which can differ from the actual way that another agent misvalues the good under consideration. This can constitute the source of a second-order misvaluation. We model different attitudes and situations in which agents face unexpected signals from their counterparties and the manner and extent to which they revise their initial beliefs. We analyse and simulate numerically the consequences of first-order and second-order misvaluation on market equilibria.
FRAMe (Flood Resilience Agent-Based Model)
Wenhan Feng | Published Wednesday, October 22, 2025The FRAMe (Flood Resilience Agent-Based Model) serves as a framework designed to simulate flood resilience dynamics at the community level, focusing on a rural settlement in the Mekong River Basin. Integrating empirical data from extensive surveys, Bayesian networks, and hydrological simulations, the framework quantifies resilience as a trade-off between robustness (resistance to damage) and adaptability (capacity for dynamic response). Agents include households, governments, and other actors, linked by social and governance networks that facilitate knowledge transfer, resource distribution, and risk communication. FRAMe incorporates mechanisms for flood forecasting, policy interventions (education, aid, insurance), and individual and collective decision-making, grounded in Protection Motivation Theory and MoHuB frameworks. The framework’s spatially explicit design leverages GIS data, which supports scenario testing of governance structures and stakeholder interactions. By examining policy scenarios and agent behavior, FRAMe aims to inform adaptive flood management strategies and enhance community resilience.
Peer reviewed The effect of homophily on co-offending outcomes
Ruslan Klymentiev Christophe Vandeviver Luis E. C. Rocha | Published Friday, September 26, 2025This Agent-Based Model is designed to simulate how similarity-based partner selection (homophily) shapes the formation of co-offending networks and the diffusion of skills within those networks. Its purpose is to isolate and test the effects of offenders’ preference for similar partners on network structure and information flow, under controlled conditions.
In the model, offenders are represented as agents with an individual attribute and a set of skills. At each time step, agents attempt to select partners based on similarity preference. When two agents mutually select each other, they commit a co-offense, forming a tie and exchanging a skill. The model tracks the evolution of network properties (e.g., density, clustering, and tie strength) as well as the spread of skills over time.
This simple and theoretical model does not aim to produce precise empirical predictions but rather to generate insights and test hypotheses about the trade-off between partnership stability and information diffusion. It provides a flexible framework for exploring how changes in partner selection preferences may lead to differences in criminal network dynamics. Although the model was developed to simulate offenders’ interactions, in principle, it could be applied to other social processes involving social learning and skills exchange.
…
Peer reviewed Casting: A Bio-Inspired Method for Restructuring Machine Learning Ensembles
Colin Lynch Bryan Daniels | Published Thursday, September 18, 2025The wisdom of the crowd refers to the phenomenon in which a group of individuals, each making independent decisions, can collectively arrive at highly accurate solutions—often more accurate than any individual within the group. This principle relies heavily on independence: if individual opinions are unbiased and uncorrelated, their errors tend to cancel out when averaged, reducing overall bias. However, in real-world social networks, individuals are often influenced by their neighbors, introducing correlations between decisions. Such social influence can amplify biases, disrupting the benefits of independent voting. This trade-off between independence and interdependence has striking parallels to ensemble learning methods in machine learning. Bagging (bootstrap aggregating) improves classification performance by combining independently trained weak learners, reducing bias. Boosting, on the other hand, explicitly introduces sequential dependence among learners, where each learner focuses on correcting the errors of its predecessors. This process can reinforce biases present in the data even if it reduces variance. Here, we introduce a new meta-algorithm, casting, which captures this biological and computational trade-off. Casting forms partially connected groups (“castes”) of weak learners that are internally linked through boosting, while the castes themselves remain independent and are aggregated using bagging. This creates a continuum between full independence (i.e., bagging) and full dependence (i.e., boosting). This method allows for the testing of model capabilities across values of the hyperparameter which controls connectedness. We specifically investigate classification tasks, but the method can be used for regression tasks as well. Ultimately, casting can provide insights for how real systems contend with classification problems.
An Agent-Based Model of Farmland Trading Partners Selection
Hang Xiong Chen Yuxin Xinfan Wang | Published Tuesday, August 19, 2025This base model uses an agent-based approach to represent heterogeneous farmers’ trading partners selection among multiple recipients (other farmers, village collectives, and firms). Each period, a potential transfer-out farmer decides whether to transfer based on a net-return versus transaction-cost trade-off; if transferring, the farmer selects the counterparty with the highest expected profit. Meanwhile, social learning—operationalized as logistic accumulation of neighborhood experience—continuously updates uncertainty, which in turn shapes transaction costs and subsequent decisions.
An agent-based model exploring the biodiversity-agriculture-nutrition dynamics in Eastern Madagascar resulting from alternative land uses
Romain Clercq-Roques Jessica Williams Katja Perez Guzman Marta Kozicka Kristine Belesova Zaid Chalabi | Published Wednesday, July 23, 2025This agent-based model simulates the interactions between smallholder farming households, land-use dynamics, and ecosystem services in a rural landscape of Eastern Madagascar. It explores how alternative agricultural practices —shifting agriculture, rice cultivation, and agroforestry—combined with varying levels of forest protection, influence food production, food security, dietary diversity, and forest biodiversity over time. The landscape is represented as a grid of spatially explicit patches characterized by land use, ecological attributes, and regeneration dynamics. Agents make yearly decisions on land management based on demographic pressures, agricultural returns, and institutional constraints. Crop yields are affected by stochastic biotic and abiotic disruptions, modulated by local ecosystem regulation functions. The model additionally represents foraging as a secondary food source and pressure on biodiversity. The model supports the analysis of long-term trade-offs between agricultural productivity, human nutrition, and conservation under different policy and land-use scenarios.
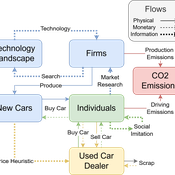
Driving in the wrong direction? A co-evolutionary model of electric vehicle adoption and innovation
Daniel Torren-Peraire | Published Friday, July 11, 2025Car-centric societies face substantial challenges in moving towards sustainable
mobility systems, with internal combustion engine vehicles remaining a major
source of emissions. Electric vehicles play a critical role in addressing this challenge, yet their diffusion depends on the interaction of consumer behaviour, firm
innovation, and policy incentives. This paper develops an agent-based model to
examine these dynamics, calibrated on the data for the state of California over
2001-2023. In the model, heterogeneous car users influenced by their social peers
…
An agent-based model to simulate field-specific nitrogen fertilizer applications in grasslands
Maria Haensel Thomas Schmitt Andrea Kaim Sylvia Helena Annuth Thomas Koellner | Published Sunday, February 09, 2025Grasslands have a large share of the world’s land cover and their sustainable management is important for the protection and provisioning of grassland ecosystem services. The question of how to manage grassland sustainably is becoming increasingly important, especially in view of climate change, which on the one hand extends the vegetation period (and thus potentially allows use intensification) and on the other hand causes yield losses due to droughts. Fertilization plays an important role in grassland management and decisions are usually made at farm level. Data on fertilizer application rates are crucial for an accurate assessment of the effects of grassland management on ecosystem services. However, these are generally not available on farm/field scale. To close this gap, we present an agent-based model for Fertilization In Grasslands (FertIG). Based on animal, land-use, and cutting data, the model estimates grassland yields and calculates field-specific amounts of applied organic and mineral nitrogen on grassland (and partly cropland). Furthermore, the model considers different legal requirements (including fertilization ordinances) and nutrient trade among farms. FertIG was applied to a grassland-dominated region in Bavaria, Germany comparing the effects of changes in the fertilization ordinance as well as nutrient trade. The results show that the consideration of nutrient trade improves organic fertilizer distribution and leads to slightly lower Nmin applications. On a regional scale, recent legal changes (fertilization ordinance) had limited impacts. Limiting the maximum applicable amount of Norg to 170 kg N/ha fertilized area instead of farm area as of 2020 hardly changed fertilizer application rates. No longer considering application losses in the calculation of fertilizer requirements had the strongest effects, leading to lower supplementary Nmin applications. The model can be applied to other regions in Germany and, with respective adjustments, in Europe. Generally, it allows comparing the effects of policy changes on fertilization management at regional, farm and field scale.
On the liquidity of the illiquid (hard-to-trade) assets
Marcin Czupryna | Published Monday, January 13, 2025This paper investigates the impact of agents' trading decisions on market liquidity and transactional efficiency in markets for illiquid (hard-to-trade) assets. Drawing on a unique order book dataset from the fine wine exchange Liv-ex, we offer novel insights into liquidity dynamics in illiquid markets. Using an agent-based framework, we assess the adequacy of conventional liquidity measures in capturing market liquidity and transactional efficiency. Our main findings reveal that conventional liquidity measures, such as the number of bids, asks, new bids and new asks, may not accurately represent overall transactional efficiency. Instead, volume (measured by the number of trades) and relative spread measures may be more appropriate indicators of liquidity within the context of illiquid markets. Furthermore, our simulations demonstrate that a greater number of traders participating in the market correlates with an increased efficiency in trade execution, while wider trader-set margins may decrease the transactional efficiency. Interestingly, the trading period of the agents appears to have a significant impact on trade execution. This suggests that granting market participants additional time for trading (for example, through the support of automated trading systems) can enhance transactional efficiency within illiquid markets. These insights offer practical implications for market participants and policymakers aiming to optimise market functioning and liquidity.
Displaying 10 of 49 results trade clear search