About the CoMSES Model Library more info
Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 136 results for "Javier Fern%C3%A1ndez-L%C3%B3pez De Pablo" clear search
Peer reviewed TRANSOPE: a multi-agent model to simulate outsourcing networks in road freight transport.
Aitor Salas-Peña Blanca Rosa Cases Gutiérrez | Published Friday, October 21, 2022A road freight transport (RFT) operation involves the participation of several types of companies in its execution. The TRANSOPE model simulates the subcontracting process between 3 types of companies: Freight Forwarders (FF), Transport Companies (TC) and self-employed carriers (CA). These companies (agents) form transport outsourcing chains (TOCs) by making decisions based on supplier selection criteria and transaction acceptance criteria. Through their participation in TOCs, companies are able to learn and exchange information, so that knowledge becomes another important factor in new collaborations. The model can replicate multiple subcontracting situations at a local and regional geographic level.
The succession of n operations over d days provides two types of results: 1) Social Complex Networks, and 2) Spatial knowledge accumulation environments. The combination of these results is used to identify the emergence of new logistics clusters. The types of actors involved as well as the variables and parameters used have their justification in a survey of transport experts and in the existing literature on the subject.
As a result of a preferential selection process, the distribution of activity among agents shows to be highly uneven. The cumulative network resulting from the self-organisation of the system suggests a structure similar to scale-free networks (Albert & Barabási, 2001). In this sense, new agents join the network according to the needs of the market. Similarly, the network of preferential relationships persists over time. Here, knowledge transfer plays a key role in the assignment of central connector roles, whose participation in the outsourcing network is even more decisive in situations of scarcity of transport contracts.
Peer reviewed AgModel
Isaac Ullah | Published Friday, December 06, 2024AgModel is an agent-based model of the forager-farmer transition. The model consists of a single software agent that, conceptually, can be thought of as a single hunter-gather community (i.e., a co-residential group that shares in subsistence activities and decision making). The agent has several characteristics, including a population of human foragers, intrinsic birth and death rates, an annual total energy need, and an available amount of foraging labor. The model assumes a central-place foraging strategy in a fixed territory for a two-resource economy: cereal grains and prey animals. The territory has a fixed number of patches, and a starting number of prey. While the model is not spatially explicit, it does assume some spatiality of resources by including search times.
Demographic and environmental components of the simulation occur and are updated at an annual temporal resolution, but foraging decisions are “event” based so that many such decisions will be made in each year. Thus, each new year, the foraging agent must undertake a series of optimal foraging decisions based on its current knowledge of the availability of cereals and prey animals. Other resources are not accounted for in the model directly, but can be assumed for by adjusting the total number of required annual energy intake that the foraging agent uses to calculate its cereal and prey animal foraging decisions. The agent proceeds to balance the net benefits of the chance of finding, processing, and consuming a prey animal, versus that of finding a cereal patch, and processing and consuming that cereal. These decisions continue until the annual kcal target is reached (balanced on the current human population). If the agent consumes all available resources in a given year, it may “starve”. Starvation will affect birth and death rates, as will foraging success, and so the population will increase or decrease according to a probabilistic function (perturbed by some stochasticity) and the agent’s foraging success or failure. The agent is also constrained by labor caps, set by the modeler at model initialization. If the agent expends its yearly budget of person-hours for hunting or foraging, then the agent can no longer do those activities that year, and it may starve.
Foragers choose to either expend their annual labor budget either hunting prey animals or harvesting cereal patches. If the agent chooses to harvest prey animals, they will expend energy searching for and processing prey animals. prey animals search times are density dependent, and the number of prey animals per encounter and handling times can be altered in the model parameterization (e.g. to increase the payoff per encounter). Prey animal populations are also subject to intrinsic birth and death rates with the addition of additional deaths caused by human predation. A small amount of prey animals may “migrate” into the territory each year. This prevents prey animals populations from complete decimation, but also may be used to model increased distances of logistic mobility (or, perhaps, even residential mobility within a larger territory).
…
The emergence of tag-mediated altruism in structured societies
Shade Shutters David Hales | Published Tuesday, January 20, 2015 | Last modified Thursday, March 02, 2023This abstract model explores the emergence of altruistic behavior in networked societies. The model allows users to experiment with a number of population-level parameters to better understand what conditions contribute to the emergence of altruism.

Peer reviewed Descriptive Norm and Fraud Dynamics
Alexandra Eckert Matthias Meyer Christian Stindt | Published Tuesday, January 07, 2025 | Last modified Tuesday, March 24, 2026The “Descriptive Norm and Fraud Dynamics” model demonstrates how fraudulent behavior can either proliferate or be contained within non-hierarchical organizations, such as peer networks, through social influence taking the form of a descriptive norm. This model expands on the fraud triangle theory, which posits that an individual must concurrently possess a financial motive, perceive an opportunity, and hold a pro-fraud attitude to engage in fraudulent activities (red agent). In the absence of any of these elements, the individual will act honestly (green agent).
The model explores variations in a descriptive norm mechanism, ranging from local distorted knowledge to global perfect knowledge. In the case of local distorted knowledge, agents primarily rely on information from their first-degree colleagues. This knowledge is often distorted because agents are slow to update their empirical expectations, which are only partially revised after one-to-one interactions. On the other end of the spectrum, local perfect knowledge is achieved by incorporating a secondary source of information into the agents’ decision-making process. Here, accurate information provided by an observer is used to update empirical expectations.
The model shows that the same variation of the descriptive norm mechanism could lead to varying aggregate fraud levels across different fraud categories. Two empirically measured norm sensitivity distributions associated with different fraud categories can be selected into the model to see the different aggregate outcomes.
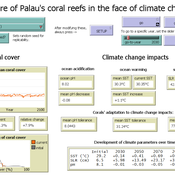
Development of coral reefs under climate change impacts and adaptation options
Nina Preußler | Published Friday, May 30, 2025This NetLogo model simulates how coral reefs around the islands of Palau would develop under different emission scenarios and with selected adaptation strategies. Reef health is indicated by coral cover (%) and is affected by four major climate change impacts: increasing sea surface temperature, sea level rise, ocean acidification, and more intense typhoons. The model differentiates between inner and outer reefs, with the former naturally adapted to warmer, more acidic waters. The simulation includes bleaching events and possible recovery. In addition, the user can choose between different coral transplantation strategies as well as regulate natural thermal adaptation rates.
LogoClim: WorldClim in NetLogo
Daniel Vartanian Leandro Garcia Aline Martins de Carvalho Aline | Published Thursday, July 03, 2025 | Last modified Tuesday, September 16, 2025LogoClim is a NetLogo model for simulating and visualizing global climate conditions. It allows researchers to integrate high-resolution climate data into agent-based models, supporting reproducible research in ecology, agriculture, environmental sciences, and other fields that rely on climate data.
The model utilizes raster data to represent climate variables such as temperature and precipitation over time. It incorporates historical data (1951-2024) and future climate projections (2021-2100) derived from global climate models under various Shared Socioeconomic Pathways (SSPs, O’Neill et al., 2017). All climate inputs come from WorldClim 2.1, a widely used source of high-resolution, interpolated climate datasets based on weather station observations worldwide (Fick & Hijmans, 2017).
LogoClim follows the FAIR Principles for Research Software (Barker et al., 2022) and is openly available on the CoMSES Network and GitHub. See the Logônia model for an example of its integration into a full NetLogo simulation.
Exploring the aftermath of transition failures: An agent-based model
Gangmin Park Junmin Lee Jisoo Lee Keungoui Kim | Published Friday, March 06, 2026This computational model is an agent-based model (ABM) developed to investigate how repeated failures of emerging niches accumulate and influence the trajectory of socio-technical transitions. Built in AnyLogic 8.7.11, the model simulates the dynamic interactions between a dominant regime and sequential niche entrants within a two-dimensional practice space. It models alignment, movement, and competition based on technological maturity and market penetration. The model utilizes a reinforcing feedback structure linking consumer support, output, resource accumulation, and capacity development (Physical and Institutional Capacity). A complete model specification following the ODD+D (Overview, Design concepts, Details, and Decision) protocol is included in the documentation.

3D Urban Traffic Simulator (ABM) in Unity
Daniel Birks Sedar Olmez Obi Thompson Sargoni Alison Heppenstall Annabel Whipp Ed Manley | Published Friday, January 22, 2021 | Last modified Monday, March 22, 2021The Urban Traffic Simulator is an agent-based model developed in the Unity platform. The model allows the user to simulate several autonomous vehicles (AVs) and tune granular parameters such as vehicle downforce, adherence to speed limits, top speed in mph and mass. The model allows researchers to tune these parameters, run the simulator for a given period and export data from the model for analysis (an example is provided in Jupyter Notebook).
The data the model is currently able to output are the following:
…
Peer reviewed Avian pest control: Yield outcome due to insectivorous birds, falconry, and integration of nest boxes.
David Jung | Published Monday, November 13, 2023 | Last modified Sunday, November 19, 2023The model aims to simulate predator-prey relationships in an agricultural setting. The focus lies on avian communities and their effect on different pest organisms (here: pest birds, rodents, and arthropod pests). Since most case studies focused on the impact on arthropod pests (AP) alone, this model attempts to include effects on yield outcome. By incorporating three treatments with different factor levels (insectivorous bird species, falconry, nest box density) an experimental setup is given that allows for further statistical analysis to identify an optimal combination of the treatments.
In light of a global decline of birds, insects, and many other groups of organisms, alternative practices of pest management are heavily needed to reduce the input of pesticides. Avian pest control therefore poses an opportunity to bridge the disconnect between humans and nature by realizing ecosystem services and emphasizing sustainable social ecological systems.
Kenya ITN Agent-Based Microsimulation (2003–2024)
Wooyoung Kim Hosang Shin | Published Saturday, April 18, 2026An agent-based microsimulation of insecticide-treated net (ITN) distribution and adoption in Kenya (2003–2024), integrating the Theory of Planned Behaviour, Rogers diffusion, Weibull net decay, and a GPS-based two-layer social network. 8,561 household agents calibrated via Approximate Bayesian Computation to six DHS/MIS survey waves, achieving 2.42 pp mean absolute error on Kenya-level ownership. The analysis chain supports mechanism counterfactuals and policy experiments on equity outcomes of ITN distribution strategies.
Displaying 10 of 136 results for "Javier Fern%C3%A1ndez-L%C3%B3pez De Pablo" clear search