Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1284 results Sort by: Recently modified clear search
Agent modeling (ABM) as a tool to improve the mobility of “avoidant” birds in an ecological corridor in the localities of Chapinero, Teusaquillo, Barrios Unidos and Engativá of Bogotá city [Scenario 2]
Paula Alejandra Meza | Published Thursday, June 25, 2026Considering that two of the three avoider species could not reach the target area in the inittial scenario, five alternative corridor scenarios were created. In all cases, we generated a greater amount of cover area under ‘Urban forest’, including elements such as scattered trees, woody plants, wooded areas, and rows of trees. This covered type was selected since all three species use it as a regular habitat. That is the second sceneario where those ecological parks and other areas inside the capital city were boostered into “urban forest patches” or buffer points, with the idea of improving the survive of the three bird species and their movement. However one of the most restrictive specie was still having movement and survival issues.
Sugarscape with spice
Marco Janssen | Published Tuesday, January 14, 2020 | Last modified Wednesday, June 24, 2026This is a variation of the Sugarspace model of Axtell and Epstein (1996) with spice and trade of sugar and spice. The model is not an exact replication since we have a somewhat simpler landscape of sugar and spice resources included, as well as a simple reproduction rule where agents with a certain accumulated wealth derive an offspring (if a nearby empty patch is available).
The model is discussed in Introduction to Agent-Based Modeling by Marco Janssen. For more information see https://intro2abm.com/
Agent modeling (ABM) as a tool to improve the mobility of “avoidant” birds in an ecological corridor in the localities of Chapinero, Teusaquillo, Barrios Unidos and Engativá of Bogotá city
Paula Alejandra Meza Maria Angela Echeverry-Galvis Mauricio González Méndez | Published Wednesday, June 24, 2026The purpose of this model is to analyze different configurations and scenarios of ecological corridors to simulate the movement of three avoider bird species at a local scale: Chondrohierax uncinatus (Accipitridae), a large carnivorous bird; Ampelion rubrocristatus (Cotingidae), a species that seeks areas with substantial land cover for refuge and rest; and Coeligena bonapartei (Trochilidae), a large hummingbird that prefers areas with a rich and diverse food supply. The model focusses on juvenile bird individuals seeking refuge and food, taking into account the mobility parameters of each species and the existing land cover types within the study area.
Specifically, the model aims to:
• Simulate the movement of 45 avoiders birds which are considered umbrella species sensitive to urban changes (which were chosen based on their specific biological and ecological requirements and parameters relevant to urban conservation efforts), 15 avoiders birds per specie to cross a two-dimensional world predominant urban.
• To be able to select which corridor scenario would be the most beneficial, in order to help the mobility of other species affected by urban fragmentation.
• Contribute to urban ecology research and support decision-making processes by relevant stakeholders.
An Agent-Based Model of Saving under Quasi-Hyperbolic Discounting on a Social Network.
Jose Alejandro Velazquez Monzon | Published Wednesday, June 24, 2026An agent-based model of saving and dissaving behaviour under quasi-hyperbolic (β–δ) discounting. Building on the individual decision problem of Cao and Werning (2018), the model embeds present-biased agents in a Watts–Strogatz small-world network and adds three configurable mechanisms of social influence — information diffusion, peer comparison, and social-norm conformity — across five heterogeneous behavioural profiles (Planners, Moderates, Procrastinators, Inverse Procrastinators, and Impulsive agents).
Each profile’s saving policy is approximated by value-function iteration over a discretised wealth grid; the solved policies are cached and applied as agents interact over their network neighbourhoods. The model tests whether each social mechanism can alter the saving and wealth trajectories that present-biased agents would otherwise follow in isolation, and characterises the direction and size of each effect on median wealth, wealth inequality (Gini), and the incidence of severely depleted agents.
The deposit includes the core model (Model.py), an analysis and visualisation pipeline (analyze_results.py), a standalone ODD description (ODD.md), and pinned dependencies.
Peer reviewed The Indus Village's Weather model: procedural generation of daily weather
Andreas Angourakis | Published Tuesday, May 13, 2025Overview
The Weather model is a procedural generation model designed to create realistic daily weather data for socioecological simulations. It generates synthetic weather time series for solar radiation, temperature, and precipitation using algorithms based on sinusoidal and double logistic functions. The model incorporates stochastic variation to mimic unpredictable weather patterns and aims to provide realistic yet flexible weather inputs for exploring diverse climate scenarios.
The Weather model can be used independently or integrated into larger models, providing realistic weather patterns without extensive coding or data collection. It can be customized to meet specific requirements, enabling users to gain a better understanding of the underlying mechanisms and have greater confidence in their applications.
…
Peer reviewed Kenya ITN Agent-Based Microsimulation (2003–2024)
Wooyoung Kim Hosang Shin | Published Saturday, April 18, 2026 | Last modified Tuesday, June 16, 2026An agent-based microsimulation of insecticide-treated net (ITN) distribution and adoption in Kenya (2003–2024), integrating the Theory of Planned Behaviour, Rogers diffusion, Weibull net decay, and a GPS-based two-layer social network. 8,561 household agents calibrated via Approximate Bayesian Computation to six DHS/MIS survey waves, achieving 2.42 pp mean absolute error on Kenya-level ownership. The analysis chain supports mechanism counterfactuals and policy experiments on equity outcomes of ITN distribution strategies.

Peer reviewed Flibs'NLogo - An elementary form of evolutionary cognition
Cosimo Leuci | Published Thursday, January 30, 2020 | Last modified Monday, June 15, 2026Flibs’NLogo is an agent-based simulation implemented in NetLogo that models the evolution of perfect predictors through a genetic algorithm. The agents, called flibs (finite living blobs), are finite‑state automata whose behaviour is encoded in circular chromosomes. They inhabit a “primordial computer soup” and are tasked with anticipating a user‑defined periodic binary sequence. Each generation consists of 100 evaluation cycles, during which a flib’s fitness is incremented each time its output correctly matches the next environmental signal.
Reproduction follows an elitist scheme: a donor (current fittest individual) replaces a randomly chosen recipient either by cloning (complete genome substitution) or by bacterial‑like conjugation (unidirectional horizontal transfer of a random chromosome segment). A stochastic mutagenesis operator introduces point mutations in genes, while the reproductive strategy gene can also switch under a mixed-reproduction regime. Population dynamics are monitored via genomic diversity indices (Shannon‑Wiener, Simpson), a phenotypic simpleness metric that distinguishes the low number of states actually used from the genomic potential.
The model serves as a digital evolutionary laboratory for exploring the interplay among bounded rationality, collective adaptation, and the emergence of anticipatory behaviour. By linking evolutionary computation with cognitive concepts, Flibs’NLogo investigates fundamental transitions from reactive to predictive systems and allows for testing whether populations evolve toward minimal necessary complexity or exhibit an intrinsic drift toward structural elaboration.
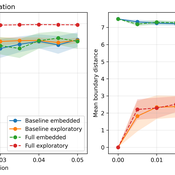
From Boundary Crossings to Global Connectivity: A Minimal Mechanism in Structured Agent-Based Landscapes
Fabio Nelli | Published Sunday, May 17, 2026This repository contains the Python implementation of an agent-based model investigating how localized boundary-crossing dynamics generate large-scale connectivity in structured multi-attractor landscapes.
Agents evolve in a continuous two-dimensional environment composed of attractor basins. A fraction of agents exhibits exploratory higher-mobility dynamics, while the remaining agents remain locally constrained. The model analyzes how localized configurational transitions accumulate into transition networks that progressively integrate the explored state space.
The repository includes:
…
ABMIND: An Empirically Informed Agent-Based Model of Psychological Distance and Environmental Protection Behavior
Wenhan Feng | Published Saturday, June 13, 2026ABMIND, the Agent-Based Model of Individual Psychological Distance, is a modeling framework developed to examine how psychological distance influences environmental protection behavior in coastal farming communities in southern China. Using household survey data and empirically estimated behavioral pathways, the model represents how uncertainty shapes four dimensions of psychological distance, namely temporal, spatial, social and hypothetical distance, and how these dimensions guide protection and degradation decisions. Agents include households, government actors and mangrove ecosystem patches, connected through social networks and ecological feedbacks that affect learning, expectations and perceived benefits. Policy interventions such as rewards, penalties and publicity guidance efforts work by modifying uncertainty and psychological distance rather than directly controlling behavior. ABMIND is implemented as a spatially explicit model following the ODD protocol, and a concise user guide is provided. In developing ABMIND we introduce a structured validation workflow that links statistical mediation analysis with simulation-based diagnostics, allowing empirical cognitive mechanisms to be systematically embedded and tested within the ABM. This integrated approach strengthens the credibility of psychological-mechanism models and supports their use in policy evaluation. The framework offers a methodological platform for integrating cognitive mechanisms into agent-based environmental behavior modeling and for evaluating policy strategies that support ecosystem protection.
Model paper:
ABMIND: An empirically informed agent-based model of psychological distance and environmental protection behaviour
Ecological Modelling
https://doi.org/10.1016/j.ecolmodel.2026.111700

Peer reviewed FishCensus
Miguel Pais | Published Tuesday, December 06, 2016 | Last modified Thursday, February 09, 2017The FishCensus model simulates underwater visual census methods, where a diver estimates the abundance of fish. A separate model is used to shape species behaviours and save them to a file that can be shared and used by the counting model.
Displaying 10 of 1284 results Sort by: Recently modified clear search