
Paul Smaldino
AffiliationsUniversity of California, Merced
Personal homepage ORCID more infoNo associated ORCID account.
GitHub more infoNo associated GitHub account.
No bio entered.
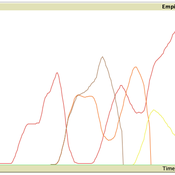
Replica of Turchin's (2003) Metaethnic Frontier model
Paul Smaldino | Published Sunday, February 15, 2026In his 2003 book, Historical Dynamics (ch. 4), Turchin describes and briefly analyzes a spatial ABM of his metaethnic frontier theory, which is essentially a formalization of a theory by Ibn Khaldun in the 14th century. In the model, polities compete with neighboring polities and can absorb them into an empire. Groups possess “asabiya”, a measure of social solidarity and a sense of shared purpose. Regions that share borders with other groups will have increased asabiya do to salient us vs. them competition. High asabiya enhances the ability to grow, work together, and hence wage war on neighboring groups and assimilate them into an empire. The larger the frontier, the higher the empire’s asabiya.
As an empire expands, (1) increased access to resources drives further growth; (2) internal conflict decreases asabiya among those who live far from the frontier; and (3) expanded size of the frontier decreases ability to wage war along all frontiers. When an empire’s asabiya decreases too much, it collapses. Another group with more compelling asabiya eventually helps establish a new empire.

Blending vs particulate inheritance - demo of Fisher (1930)
Paul Smaldino | Published Friday, September 13, 2024A simple model illustrating RA Fisher’s (1930) reconciliation of Darwinian selection with particulate genetic contributions.
The spread of scientific methods within and between communities
Paul Smaldino Cailin O'Connor | Published Monday, August 29, 2022We consider scientific communities where each scientist employs one of two characteristic methods: an “adequate” method (A) and a “superior” method (S). The quality of methodology is relevant to the epistemic products of these scientists, and generate credit for their users. Higher-credit methods tend to be imitated, allowing to explore whether communities will adopt one method or the other. We use the model to examine the effects of (1) bias for existing methods, (2) competence to assess relative value of competing methods, and (3) two forms of interdisciplinarity: (a) the tendency for members of a scientific community to receive meaningful credit assignment from those outside their community, and (b) the tendency to consider new methods used outside their community. The model can be used to show how interdisciplinarity can overcome the effects of bias and incompetence for the spread of superior methods.
Superiority Bias and Communication Noise in a Model of Collective Problem Solving
Paul Smaldino Amin Boroomand | Published Sunday, May 01, 2022This model aims to examine how different levels of communication noise and superiority bias affect team performance when solving problems collectively. We used a networked agent-based model of collective problem solving in which agents explore the NK landscape for a better solution and communicate with each other regarding their current solutions. We compared the team performance in solving problems collectively at different levels of self-superiority bias when facing simple and complex problems. Additionally, we addressed the effect of different levels of communication noise on the team’s outcome
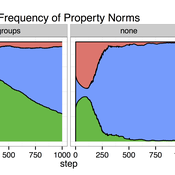
Cultural Group Selection of Sustainable Institutions
Timothy Waring Paul Smaldino Sandra H Goff | Published Wednesday, June 10, 2015 | Last modified Tuesday, August 04, 2015We develop a spatial, evolutionary model of the endogenous formation and dissolution of groups using a renewable common pool resource. We use this foundation to measure the evolutionary pressures at different organizational levels.
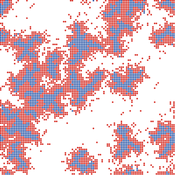
Increased costs of cooperation help cooperators in the long run
Paul Smaldino | Published Wednesday, March 01, 2017A spatial prisoner’s dilemma model with mobile agents, de-coupled birth-death events, and harsh environments.
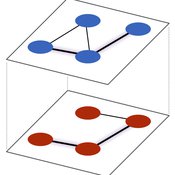
Network formation on a two-layer multiplex with shocks
Paul Smaldino | Published Monday, November 27, 2017A dynamic model of social network formation on single-layer and multiplex networks with structural incentives that vary over time.

Institutions and Cooperation in an Ecology of Games
Paul Smaldino | Published Wednesday, November 29, 2017Dynamic bipartite network model of agents and games in which agents can participate in multiple public goods games.
Simulating the evolution of the human family
Paul Smaldino | Published Wednesday, November 29, 2017The (cultural) evolution of cooperative breeding in harsh environments.
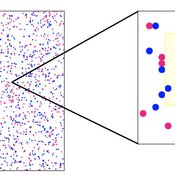
Human mate choice is a complex system
Paul Smaldino Jeffrey C Schank | Published Friday, February 08, 2013 | Last modified Saturday, April 27, 2013A general model of human mate choice in which agents are localized in space, interact with close neighbors, and tend to range either near or far. At the individual level, our model uses two oft-used but incompletely understood decision rules: one based on preferences for similar partners, the other for maximally attractive partners.
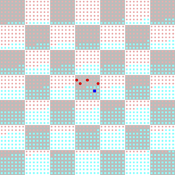
Adoption as a social marker
Paul Smaldino | Published Monday, October 17, 2016A model of innovation diffusion in a structured population with two groups who are averse to adopting a produce popular with the outgroup.
Under development.