Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 35 results empirical data clear search
FRAMe (Flood Resilience Agent-Based Model)
Wenhan Feng | Published Wednesday, October 22, 2025The FRAMe (Flood Resilience Agent-Based Model) serves as a framework designed to simulate flood resilience dynamics at the community level, focusing on a rural settlement in the Mekong River Basin. Integrating empirical data from extensive surveys, Bayesian networks, and hydrological simulations, the framework quantifies resilience as a trade-off between robustness (resistance to damage) and adaptability (capacity for dynamic response). Agents include households, governments, and other actors, linked by social and governance networks that facilitate knowledge transfer, resource distribution, and risk communication. FRAMe incorporates mechanisms for flood forecasting, policy interventions (education, aid, insurance), and individual and collective decision-making, grounded in Protection Motivation Theory and MoHuB frameworks. The framework’s spatially explicit design leverages GIS data, which supports scenario testing of governance structures and stakeholder interactions. By examining policy scenarios and agent behavior, FRAMe aims to inform adaptive flood management strategies and enhance community resilience.
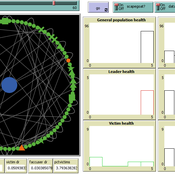
An agent-based model of scapegoating
Carlos Paes | Published Thursday, August 28, 2025 | Last modified Thursday, August 28, 2025This agent-based model investigates scapegoating as a social mechanism of crisis management. Inspired by René Girard’s mimetic theory, it simulates how individual tension accumulates and spreads across a small-world network. When tension exceeds certain thresholds, leaders emerge and accuse marginalized agents, who may attempt to transfer blame to substitutes. If scapegoating occurs, collective tension decreases, but victims become isolated while leaders consolidate temporary authority. This simulation provides a conceptual and methodological framework for exploring how collective blame, crisis contagion, and leadership paradoxes emerge in complex networks. It can also be extended with empirical data, such as social media dynamics of online harassment and virtual lynching, offering potential applications for both theoretical research and practical crisis monitoring.
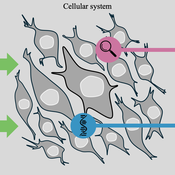
GenoScope
Kristin Crouse | Published Wednesday, May 29, 2024 | Last modified Wednesday, April 09, 2025GenoScope is a modular agent-based model designed to simulate how cells respond to environmental stressors or other treatment conditions across species. Genes, treatment conditions, and cell physiology outcomes are represented as interacting agents that influence each other’s behavior over time. Rather than imposing fixed interaction rules, GenoScope initializes with randomized regulatory logic and calibrates rule sets based on empirical data. Calibration is grounded in a common-garden experiment involving 16 mammalian species—including humans, dolphins, bats, and camels—exposed to varying levels of temperature, glucose, and oxygen. This comparative approach enables the identification of mechanisms by which animal cells achieve robustness under extreme environmental conditions.

Peer reviewed The Viability of the Social-Ecological Agroecosystem (ViSA) Spatial Agent-based Model
Mostafa Shaaban | Published Monday, March 25, 2024ViSA 2.0.0 is an updated version of ViSA 1.0.0 aiming at integrating empirical data of a new use case that is much smaller than in the first version to include field scale analysis. Further, the code of the model is simplified to make the model easier and faster. Some features from the previous version have been removed.
It simulates decision behaviors of different stakeholders showing demands for ecosystem services (ESS) in agricultural landscape. It investigates conditions and scenarios that can increase the supply of ecosystem services while keeping the viability of the social system by suggesting different mixes of initial unit utilities and decision rules.
Vaccine adoption with outgroup aversion using Cleveland area data
bruce1809 | Published Monday, July 31, 2023 | Last modified Sunday, August 06, 2023This model takes concepts from a JASSS paper this is accepted for the October, 2023 edition and applies the concepts to empirical data from counties surrounding and including Cleveland Ohio. The agent-based model has a proportional number of agents in each of the counties to represent the correct proportions of adults in these counties. The adoption decision probability uses the equations from Bass (1969) as adapted by Rand & Rust (2011). It also includes the Outgroup aversion factor from Smaldino, who initially had used a different imitation model on line grid. This model uses preferential attachment network as a metaphor for social networks influencing adoption. The preferential network can be adjusted in the model to be created based on both nodes preferred due to higher rank as well as a mild preference for nodes of a like group.
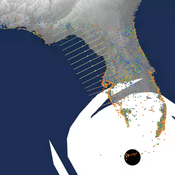
Peer reviewed CHIME ABM of Hurricane Evacuation
C Michael Barton Sean Bergin Joshua Watts Joshua Alland Rebecca Morss | Published Monday, October 18, 2021 | Last modified Tuesday, January 04, 2022The Communicating Hazard Information in the Modern Environment (CHIME) agent-based model (ABM) is a Netlogo program that facilitates the analysis of information flow and protective decisions across space and time during hazardous weather events. CHIME ABM provides a platform for testing hypotheses about collective human responses to weather forecasts and information flow, using empirical data from historical hurricanes. The model uses real world geographical and hurricane data to set the boundaries of the simulation, and it uses historical hurricane forecast information from the National Hurricane Center to initiate forecast information flow to citizen agents in the model.
Agent-Based Model of Social Care with Kinship Networks
Umberto Gostoli Eric Silverman | Published Thursday, October 14, 2021The purpose of this model is the simulation of social care provision in the UK, in which individual agents can decide to provide informal care, or pay for private care, for their loved ones. Agents base these decisions on factors including their own health, employment status, financial resources, relationship to the individual in need and geographical location. The model simulates care provision as a negotiation process conducted between agents across their kinship networks, with agents with stronger familial relationships to the recipient being more likely to attempt to allocate time to care provision. The model also simulates demographic change, the impact of socioeconomic status, and allows agents to relocate and change jobs or reduce working hours in order to provide care.
Despite the relative lack of empirical data in this model, the model is able to reproduce plausible patterns of social care provision. The inclusion of detailed economic and behavioural mechanisms allows this model to serve as a useful policy development tool; complex behavioural interventions can be implemented in simulation and tested on a virtual population before applying them in real-world contexts.
ACTING (Affect Control Theory based simulation of Interaction in Networked Groups)
nikozoe | Published Thursday, August 19, 2021This agent-based simulation model for group interaction is rooted in social psychological theory. The
model integrates affect control theory with networked interaction structures and sequential behavior protocols as they are often encountered in task groups. By expressing status hierarchy through network structure we build a bridge between expectation states theory and affect control theory, and are able to reproduce central results from the expectation states research program in sociological social psychology. Furthermore, we demonstrate how the model can be applied to analyze specialized task groups or sub-cultural domains by combining it with empirical data sources. As an example, we simulate groups of open-source software developers and analyze how cultural expectations influence the occupancy of high status positions in these groups.
A data-informed bounded-confidence opinion dynamics model
Bruce Edmonds | Published Wednesday, March 10, 2021The simulation is a variant of the “ToRealSim OD variants - base v2.7” base model, which is based on the standard DW opinion dynamics model (but with the differences that rather than one agent per tick randomly influencing another, all agents randomly influence one other per tick - this seems to make no difference to the outcomes other than to scale simulation time). Influence can be made one-way by turning off the two-way? switch
Various additional variations and sources of noise are possible to test robustness of outcomes to these (compared to DW model).
In this version agent opinions change following the empirical data collected in some experiments (Takács et al 2016).
Such an algorithm leaves no role for the uncertainties in other OD models. [Indeed the data from (Takács et al 2016) indicates that there can be influence even when opinion differences are large - which violates a core assumption of these]. However to allow better comparison with other such models there is a with-un? switch which allows uncertainties to come into play. If this is on, then influence (according to above algorithm) is only calculated if the opinion difference is less than the uncertainty. If an agent is influenced uncertainties are modified in the same way as standard DW models.
Peer reviewed An extended replication of Abelson's and Bernstein's community referendum simulation
Klaus G. Troitzsch | Published Friday, October 25, 2019 | Last modified Friday, August 25, 2023This is an extended replication of Abelson’s and Bernstein’s early computer simulation model of community referendum controversies which was originally published in 1963 and often cited, but seldom analysed in detail. This replication is in NetLogo 6.3.0, accompanied with an ODD+D protocol and class and sequence diagrams.
This replication replaces the original scales for attitude position and interest in the referendum issue which were distributed between 0 and 1 with values that are initialised according to a normal distribution with mean 0 and variance 1 to make simulation results easier compatible with scales derived from empirical data collected in surveys such as the European Value Study which often are derived via factor analysis or principal component analysis from the answers to sets of questions.
Another difference is that this model is not only run for Abelson’s and Bernstein’s ten week referendum campaign but for an arbitrary time in order that one can find out whether the distributions of attitude position and interest in the (still one-dimensional) issue stabilise in the long run.
Displaying 10 of 35 results empirical data clear search