About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 475 results for "Tim M Daw" clear search
The Friendship Field
Eva Timmer Chrisja van de Kieft | Published Thursday, May 26, 2022 | Last modified Tuesday, August 30, 2022The Friendship Field model aims at modelling friendship formation based on three factors: Extraversion, Resemblance and Status, where social interaction is motivated by the Social Battery. Social Battery is one’s energy and motivation to engage in social contact. Since social contact is crucial for friendship formation, the model included Social Battery to affect social interactions. To our best knowledge, Social Battery is a yet unintroduced concept in research while it is a dynamic factor influencing the social interaction besides one’s characteristics. Extraverts’ Social Batteries charge while interacting and exhaust while being alone. Introverts’ Social Batteries charge while being alone and exhaust while interacting. The aim of the model is to illustrate the concept of Social Battery. Moreover, the Friendship Field shows patterns regarding Extraversion, Resemblance and Status including the mere-exposure effect and friendship by similarity. For the implementation of Status, Kemper’s status-power theory is used. The concept of Social Battery is also linked to Kemper’s theory on the organism as reference group. By running the model for a year (3 interactions moments per day), the friendship dynamics over time can be studied.
We presented the model at the Social Simulation Conference 2022.
The various technologies used inside a Dutch greenhouse interact in combination with an external climate, resulting in an emergent internal climate, which contributes to the final productivity of the greenhouse. This model examines how differing technology development styles affects the overall ability of a community of growers to approach the theoretical maximum yield.
STECCAR: a simulation of the diffusion of electric cars
A Kangur Lc Verbrugge W Jager M Bockarjova | Published Sunday, November 29, 2015In this Repast model the ‘Consumat’ cognitive framework is applied to an ABM of the Dutch car market. Different policy scenarios can be selected or created to examine their effect on the diffusion of EVs.

Model of Rental Evictions in Phoenix During the Covid-19 Pandemic
Sean Bergin J M Applegate | Published Saturday, July 31, 2021 | Last modified Friday, October 15, 2021The purpose of this model is to explore the dynamics of residency and eviction for households renting in the greater Phoenix (Arizona) metropolitan area. The model uses a representative population of renters modified from American Community Survey (ACS) data that includes demographic, housing and economic information. Each month, households pay their subsistence, rental and utility bills. If a household is unable to pay their monthly rent or utility bill they apply for financial assistance. This model provides a platform to understand the impact of various economic shock upon households. Also, the model includes conditions that occurred as a result of the Covid-19 pandemic which allows for the study of eviction mitigation strategies that were employed, such as the eviction moratorium and stimulus payments. The model allows us to make preliminary predictions concerning the number of households that may be evicted once the moratorium on evictions ends and the long-term effects on the number of evicted households in the greater Phoenix area going forward.
Formation of Lithic Assemblages v. 1
C Michael Barton Julien Riel-Salvatore | Published Thursday, September 04, 2014This model represents technological and ecological behaviors of mobile hunter-gatherers, in a variable environment, as they produce, use, and discard chipped stone artifacts. The results can be analyzed and compared with archaeological sites.
Peer reviewed A Neutral Model of Stone Raw Material Procurement
Marco Janssen Simen Oestmo | Published Tuesday, October 01, 2013A simple model of random encounters of materials that produces distributions as found in the archaeological record.
Youth and their Artificial Social Environmental Risk and Promotive Scores (Ya-TASERPS)
JoAnn Lee | Published Wednesday, July 07, 2021 | Last modified Friday, February 24, 2023Risk assessments are designed to measure cumulative risk and promotive factors for delinquency and recidivism, and are used by criminal and juvenile justice systems to inform sanctions and interventions. Yet, these risk assessments tend to focus on individual risk and often fail to capture each individual’s environmental risk. This agent-based model (ABM) explores the interaction of individual and environmental risk on the youth. The ABM is based on an interactional theory of delinquency and moves beyond more traditional statistical approaches used to study delinquency that tend to rely on point-in-time measures, and to focus on exploring the dynamics and processes that evolve from interactions between agents (i.e., youths) and their environments. Our ABM simulates a youth’s day, where they spend time in schools, their neighborhoods, and families. The youth has proclivities for engaging in prosocial or antisocial behaviors, and their environments have likelihoods of presenting prosocial or antisocial opportunities.
Peer reviewed Applying Brantingham’s Neutral Model of Stone Raw Material Procurement to the Pinnacle Point Middle Stone Age Record, Western Cape, South Africa
Marco Janssen Simen Oestmo Haley Cawthra | Published Sunday, March 10, 2019This model is an application of Brantingham’s neutral model to a real landscape with real locations of potential sources. The sources are represented as their sizes during current conditions, and from marine geophysics surveys, and the agent starts at a random location in Mossel Bay Region (MBR) surrounding the Archaeological Pinnacle Point (PP) locality, Western Cape, South Africa. The agent moves at random on the landscape, picks up and discards raw materials based only upon space in toolkit and probability of discard. If the agent happens to encounter the PP locality while moving at random the agent may discard raw materials at it based on the discard probability.
Interplay of actors about the construction of a dam
Christophe Sibertin-Blanc | Published Monday, December 05, 2016 | Last modified Wednesday, May 09, 2018Model of a very serious conflict about the relevance of a dam to impede its construction, between the client, the prime contractor, State, legalist opponents and activist opponents.
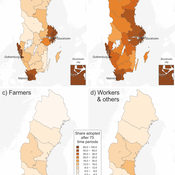
Communication and social change in space and time
Sebastian Kluesener Francesco Scalone Martin Dribe | Published Tuesday, May 17, 2016 | Last modified Friday, October 13, 2017This agent-based model simulates the diffusion of a social change process stratified by social class in space and time which is solely driven social and spatial variation in communication links.
Displaying 10 of 475 results for "Tim M Daw" clear search