About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 208 results for "Andreas Flache" clear search
Extended Flache and Mas (2008)
Hadi Aliahmadi | Published Wednesday, August 16, 2017 | Last modified Monday, February 26, 2018We extend the Flache-Mäs model to incorporate the location and dyadic communication regime of the agents in the opinion formation process. We make spatially proximate agents more likely to interact with each other in a pairwise communication regime.
Peer reviewed Modelling the Social Complexity of Reputation and Status Dynamics
André Grow Andreas Flache | Published Wednesday, February 01, 2017 | Last modified Wednesday, January 23, 2019The purpose of this model is to illustrate the use of agent-based computational modelling in the study of the emergence of reputation and status beliefs in a population.
Peer reviewed A Model of Global Diversity and Local Consensus in Status Beliefs
André Grow Andreas Flache Rafael Wittek | Published Wednesday, March 01, 2017 | Last modified Wednesday, October 25, 2017This model makes it possible to explore how network clustering and resistance to changing existing status beliefs might affect the spontaneous emergence and diffusion of such beliefs as described by status construction theory.
Can ethnic tolerance curb self-reinforcing school segregation? A theoretical Agent Based Model
Lucas Sage Andreas Flache | Published Monday, August 10, 2020Schelling and Sakoda prominently proposed computational models suggesting that strong ethnic residential segregation can be the unintended outcome of a self-reinforcing dynamic driven by choices of individuals with rather tolerant ethnic preferences. There are only few attempts to apply this view to school choice, another important arena in which ethnic segregation occurs. In the current paper, we explore with an agent-based theoretical model similar to those proposed for residential segregation, how ethnic tolerance among parents can affect the level of school segregation. More specifically, we ask whether and under which conditions school segregation could be reduced if more parents hold tolerant ethnic preferences. We move beyond earlier models of school segregation in three ways. First, we model individual school choices using a random utility discrete choice approach. Second, we vary the pattern of ethnic segregation in the residential context of school choices systematically, comparing residential maps in which segregation is unrelated to parents’ level of tolerance to residential maps reflecting their ethnic preferences. Third, we introduce heterogeneity in tolerance levels among parents belonging to the same group. Our simulation experiments suggest that ethnic school segregation can be a very robust phenomenon, occurring even when about half of the population prefers mixed to segregated schools. However, we also identify a “sweet spot” in the parameter space in which a larger proportion of tolerant parents makes the biggest difference. This is the case when parents have moderate preferences for nearby schools and there is only little residential segregation. Further experiments are presented that unravel the underlying mechanisms.
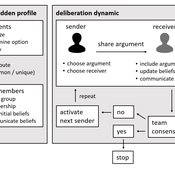
Agent-based model of team decision-making in hidden profile situations
Andreas Flache Jonas Stein Vincenz Frey | Published Thursday, April 20, 2023 | Last modified Friday, November 17, 2023The model presented here is extensively described in the paper ‘Talk less to strangers: How homophily can improve collective decision-making in diverse teams’ (forthcoming at JASSS). A full replication package reproducing all results presented in the paper is accessible at https://osf.io/76hfm/.
Narrative documentation includes a detailed description of the model, including a schematic figure and an extensive representation of the model in pseudocode.
The model develops a formal representation of a diverse work team facing a decision problem as implemented in the experimental setup of the hidden-profile paradigm. We implement a setup where a group seeks to identify the best out of a set of possible decision options. Individuals are equipped with different pieces of information that need to be combined to identify the best option. To this end, we assume a team of N agents. Each agent belongs to one of M groups where each group consists of agents who share a common identity.
The virtual teams in our model face a decision problem, in that the best option out of a set of J discrete options needs to be identified. Every team member forms her own belief about which decision option is best but is open to influence by other team members. Influence is implemented as a sequence of communication events. Agents choose an interaction partner according to homophily h and take turns in sharing an argument with an interaction partner. Every time an argument is emitted, the recipient updates her beliefs and tells her team what option she currently believes to be best. This influence process continues until all agents prefer the same option. This option is the team’s decision.

Peer reviewed Ache hunting
Kim Hill Marco Janssen | Published Tuesday, August 13, 2013 | Last modified Friday, December 21, 2018Agent-based model of hunting behavior of Ache hunter-gatherers from Paraguay. We evaluate the effect of group size and cooperative hunting
The tragedy of the park: an agent-based model on endogenous and exogenous institutions for the management of a forest.
Elena Vallino | Published Wednesday, March 27, 2013 | Last modified Thursday, April 26, 2018I model a forest and a community of loggers. Agents follow different kinds of rules in order to log. I compare the impact of endogenous and of exogenous institutions on the state of the forest and on the profit of the users, representing different scenarios of participatory conservation projects.

Peer reviewed An Agent-Based Model of Status Construction in Task Focused Groups
Andreas Flache Rafael Wittek André Grow | Published Sunday, May 18, 2014 | Last modified Tuesday, June 16, 2015The model simulates interactions in small, task focused groups that might lead to the emergence of status beliefs among group members.

Segregation and Opinion Polarization
Thomas Feliciani Andreas Flache Jochem Tolsma | Published Wednesday, April 13, 2016This is a tool to explore the effects of groups´ spatial segregation on the emergence of opinion polarization. It embeds two opinion formation models: a model of negative (and positive) social influence and a model of persuasive argument exchange.
Central-place forager mobility and cultural diversity
Luke Premo | Published Wednesday, May 18, 2016This spatially explicit agent-based model addresses how effective foraging radius (r_e) affects the effective size–and thus the equilibrium cultural diversity–of a structured population composed of central-place foraging groups.
Displaying 10 of 208 results for "Andreas Flache" clear search