About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 24 results for "Àlex Pardo Fernandez" clear search
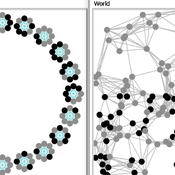
Two agent-based models of cooperation in dynamic groups and fixed social networks
Carlos A. de Matos Fernandes | Published Thursday, January 20, 2022Both models simulate n-person prisoner dilemma in groups (left figure) where agents decide to C/D – using a stochastic threshold algorithm with reinforcement learning components. We model fixed (single group ABM) and dynamic groups (bad-barrels ABM). The purpose of the bad-barrels model is to assess the impact of information during meritocratic matching. In the bad-barrels model, we incorporated a multidimensional structure in which agents are also embedded in a social network (2-person PD). We modeled a random and homophilous network via a random spatial graph algorithm (right figure).
A simple emulation-based computational model
Carlos M Fernández-Márquez Francisco J Vázquez | Published Tuesday, May 21, 2013 | Last modified Tuesday, February 05, 2019Emulation is one of the simplest and most common mechanisms of social interaction. In this paper we introduce a descriptive computational model that attempts to capture the underlying dynamics of social processes led by emulation.
Hybrid agent-based methodology for testing response protocols
Fernando Sancho Caparrini | Published Wednesday, February 03, 2021In recent years we have seen multiple incidents with a large number of people injured and killed by one or more armed attackers. Since this type of violence is difficult to predict, detecting threats as early as possible allows to generate early warnings and reduce response time. In this context, any tool to check and compare different action protocols can be a further step in the direction of saving lives. Our proposal combines features from continuous and discrete models to obtain the best of both worlds in order to simulate large and crowded spaces where complex behavior individuals interact. With this proposal we aim to provide a tool for testing different security protocols under several emergency scenarios, where spaces, hazards, and population can be customized. Finally, we use a proof of concept implementation of this model to test specific security protocols under emergency situations for real spaces. Specifically, we test how providing some users of a university college with an app that informs about the type and characteristics of the ongoing hazard, affects in the safety performance.
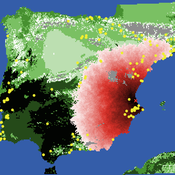
Neolithic Spread Model Version 1.0
Sean Bergin Salvador Pardo Gordo Joan Bernabeu Auban Michael Barton | Published Thursday, December 11, 2014 | Last modified Monday, December 31, 2018This model simulates different spread hypotheses proposed for the introduction of agriculture on the Iberian peninsula. We include three dispersal types: neighborhood, leapfrog, and ideal despotic distribution (IDD).
Peninsula_Iberica 1.0
Carolina Cucart-Mora Sergi Lozano Javier Fernández-López De Pablo | Published Friday, November 04, 2016 | Last modified Monday, November 27, 2017This model was build to explore the bio-cultural interaction between AMH and Neanderthals during the Middle to Upper Paleolithic Transition in the Iberian Peninsula

Maze with Q-Learning NetLogo extension
Kevin Kons Fernando Santos | Published Tuesday, December 10, 2019This is a re-implementation of a the NetLogo model Maze (ROOP, 2006).
This re-implementation makes use of the Q-Learning NetLogo Extension to implement the Q-Learning, which is done only with NetLogo native code in the original implementation.
Cliff Walking with Q-Learning NetLogo Extension
Kevin Kons Fernando Santos | Published Tuesday, December 10, 2019This model implements a classic scenario used in Reinforcement Learning problem, the “Cliff Walking Problem”. Consider the gridworld shown below (SUTTON; BARTO, 2018). This is a standard undiscounted, episodic task, with start and goal states, and the usual actions causing movement up, down, right, and left. Reward is -1 on all transitions except those into the region marked “The Cliff.” Stepping into this region incurs a reward of -100 and sends the agent instantly back to the start (SUTTON; BARTO, 2018).
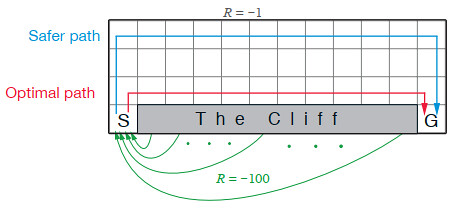
The problem is solved in this model using the Q-Learning algorithm. The algorithm is implemented with the support of the NetLogo Q-Learning Extension
Imperfect knowledge and stable governance in democracies
Carlos M Fernández-Márquez Francisco Jose Vazquez Luis Fernando Medina | Published Tuesday, February 05, 2019In this paper we introduce an agent-based model of elections and government formation where voters do not have perfect knowledge about the parties’ ideological position. Although voters are boundedly rational, they are forward-looking in that they try to assess the likely impact of the different parties over the resulting government. Thus, their decision rules combine sincere and strategic voting: they form preferences about the different parties but deem some of them as inadmissible and try to block them from office. We find that the most stable and durable coalition governments emerge at intermediate levels of informational ambiguity. When voters have very poor information about the parties, their votes are scattered too widely, preventing the emergence of robust majorities. But also, voters with highly precise perceptions about the parties will cluster around tiny electoral niches with a similar aggregate effect.
Gunpowder battle tactics
Xavier Rubio-Campillo Jose María Cela Francesc Xavier Hernàndez | Published Wednesday, November 20, 2013 | Last modified Tuesday, November 26, 2013This model simulates the dynamics of eighteenth-century infantry battle tactics. The goal is to explore the effect of different tactics and individual traits in the dynamics of the combat.
Peer reviewed BAM: The Bottom-up Adaptive Macroeconomics Model
Alejandro Platas López Alejandro Guerra-Hernández | Published Tuesday, January 14, 2020 | Last modified Sunday, July 26, 2020Overview
Purpose
Modeling an economy with stable macro signals, that works as a benchmark for studying the effects of the agent activities, e.g. extortion, at the service of the elaboration of public policies..
…
Displaying 10 of 24 results for "Àlex Pardo Fernandez" clear search