Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 260 results for "Kim Hill" clear search
U-TRANS Modelling Urban Transition with Coupled Housing and Labour Markets
Bernardo Furtado Jiaqi Ge | Published Monday, July 31, 2023We develop an agent-based model (U-TRANS) to simulate the transition of an abstract city under an industrial revolution. By coupling the labour and housing markets, we propose a holistic framework that incorporates the key interacting factors and micro processes during the transition. Using U-TRANS, we look at five urban transition scenarios: collapse, weak recovery, transition, enhanced training and global recruit, and find the model is able to generate patterns observed in the real world. For example, We find that poor neighbourhoods benefit the most from growth in the new industry, whereas the rich neighbourhoods do better than the rest when the growth is slow or the situation deteriorates. We also find a (subtle) trade-off between growth and equality. The strategy to recruit a large number of skilled workers globally will lead to higher growth in GDP, population and human capital, but it will also entail higher inequality and market volatility, and potentially create a divide between the local and international workers. The holistic framework developed in this paper will help us better understand urban transition and detect early signals in the process. It can also be used as a test-bed for policy and growth strategies to help a city during a major economic and technological revolution.
A formalized implementation of Halstead and O’Shea’s Bad Year Economics. The agent population uses one of four resilience strategies in an attempt to cope with a dynamic environment of stresses and shocks.

Peer reviewed Umwelten Ants
Kit Martin | Published Thursday, January 15, 2015 | Last modified Thursday, August 27, 2015Simulates impacts of ants killing colony mates when in conflict with another nest. The murder rate is adjustable, and the environmental change is variable. The colonies employ social learning so knowledge diffusion proceeds if interactions occur.
A preliminary extension of the Hemelrijk 1996 model of reciprocal behavior to include feeding
Sean Barton | Published Monday, December 13, 2010 | Last modified Saturday, April 27, 2013A more complete description of the model can be found in Appendix I as an ODD protocol. This model is an expansion of the Hemelrijk (1996) that was expanded to include a simple food seeking behavior.
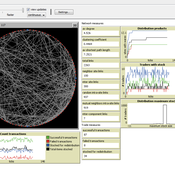
MERCURY: an ABM of tableware trade in the Roman East
Tom Brughmans Jeroen Poblome | Published Thursday, September 25, 2014 | Last modified Friday, May 01, 2015MERCURY aims to represent and explore two descriptive models of the functioning of the Roman trade system that aim to explain the observed strong differences in the wideness of distributions of Roman tableware.
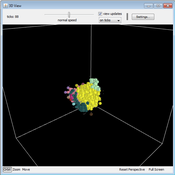
A Simulation of Entrepreneurial Spawning
Mark Bagley | Published Wednesday, June 08, 2016 | Last modified Friday, June 30, 2017Industrial clustering patterns are the result of an entrepreneurial process where spinoffs inherit the ideas and attributes of their parent firms. This computational model maps these patterns using abstract methodologies.
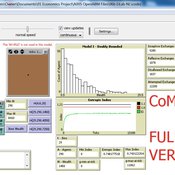
06b EiLab_Model_I_V5.00 NL
Garvin Boyle | Published Saturday, October 05, 2019EiLab - Model I - is a capital exchange model. That is a type of economic model used to study the dynamics of modern money which, strangely, is very similar to the dynamics of energetic systems. It is a variation on the BDY models first described in the paper by Dragulescu and Yakovenko, published in 2000, entitled “Statistical Mechanics of Money”. This model demonstrates the ability of capital exchange models to produce a distribution of wealth that does not have a preponderance of poor agents and a small number of exceedingly wealthy agents.
This is a re-implementation of a model first built in the C++ application called Entropic Index Laboratory, or EiLab. The first eight models in that application were labeled A through H, and are the BDY models. The BDY models all have a single constraint - a limit on how poor agents can be. That is to say that the wealth distribution is bounded on the left. This ninth model is a variation on the BDY models that has an added constraint that limits how wealthy an agent can be? It is bounded on both the left and right.
EiLab demonstrates the inevitable role of entropy in such capital exchange models, and can be used to examine the connections between changing entropy and changes in wealth distributions at a very minute level.
…
Behavioural model
Aulia Imania Sukma | Published Friday, November 07, 2025This repository serves as a design proof for agent-based modeling simulation in heat adaptation behavior. This model was developed as part of the UrbanAir project theme. This repository will be kept updated in the four-year timeline (2025 until 2029).
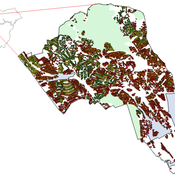
An Agent-Based Model of Flood Risk and Insurance
J Dubbelboer I Nikolic K Jenkins J Hall | Published Monday, July 27, 2015 | Last modified Monday, October 03, 2016A model to show the effects of flood risk on a housing market; the role of flood protection for risk reduction; the working of the existing public-private flood insurance partnership in the UK, and the proposed scheme ‘Flood Re’.
A model of the emergence of intersectional life course inequalities through transitions in the workplace. It explores LGBTQ citizens’ career outcomes and trajectories in relation to several mediating factors: (i) workplace discrimination; (ii) social capital; (iii) policy interventions (i.e., workplace equality, diversity, and inclusion policies); (iv) and LGBTQ employees’ behaviours in response to discrimination (i.e., moving workplaces and/or different strategies for managing the visibility of their identity).
Displaying 10 of 260 results for "Kim Hill" clear search