Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 352 results for "Tim Dorscheidt" clear search
Negotiation Lab 1.0
Julián Arévalo | Published Friday, March 20, 2026Negotiation Lab 1.0 is an agent-based model of peace negotiations that explores how the parties’ readiness — their motivation and optimism to engage in talks — evolves dynamically throughout the negotiation process. The model reconceptualizes readiness as an adaptive state variable that is continuously updated through feedback from negotiation outcomes, rather than a static precondition assessed at the onset of talks.
The model simulates two parties negotiating a multi-issue agenda. In each round, parties allocate effort to the current sub-issue; outcomes depend on their joint effort and a stochastic component representing external factors. Results feed back into each party’s readiness, shaping subsequent engagement. The negotiation ends either when all agenda items are resolved (agreement) or when a party’s readiness falls below a critical threshold (breakdown).
Key parameters include the initial readiness of each party, agenda structure (balanced, hard, easy, red, or random), type of negotiation (from highly cooperative to highly competitive), and each party’s effort strategy (always high, always low, random, or pseudo tit-for-tat). The model shows that while initial readiness is associated with negotiation outcomes, it is neither necessary nor sufficient to determine them: process variables — the type of interaction, agenda design, and adaptive effort strategies — exert comparatively larger effects on outcomes. Identical initial conditions can produce widely divergent trajectories, illustrating path dependence and sensitivity to feedback dynamics.
The model is implemented in NetLogo 7.0 and is documented using the ODD+D protocol. It is associated with the paper “Beyond Initial Conditions: How Adaptive Readiness Shapes Peace Negotiation Outcomes” (Arévalo, under review).
Peer reviewed Swidden Farming Version 2.0
C Michael Barton | Published Wednesday, June 12, 2013 | Last modified Wednesday, September 03, 2014Model of shifting cultivation. All parameters can be controlled by the user or the model can be run in adaptive mode, in which agents innovate and select parameters.
Informal Information Transmission Networks among Medieval Genoese Investors
Christopher Frantz | Published Wednesday, October 09, 2013 | Last modified Thursday, October 24, 2013This model represents informal information transmission networks among medieval Genoese investors used to inform each other about cheating merchants they employed as part of long-distance trade operations.
SimDrink: An agent-based NetLogo model of young, heavy drinkers for conducting alcohol policy experiments
Nick Scott James Wilson Michael Livingston Aaron Hart David Moore Paul Dietze | Published Friday, September 25, 2015 | Last modified Thursday, October 15, 2015A proof-of-concept agent-based model ‘SimDrink’, which simulates a population of 18-25 year old heavy alcohol drinkers on a night out in Melbourne to provide a means for conducting policy experiments to inform policy decisions.
ForagerNet3_Demography_V3
Andrew White | Published Tuesday, November 29, 2016The ForagerNet3_Demography model is a non-spatial ABM designed to serve as a platform for exploring several aspects of hunter-gatherer demography.
How does knowledge infrastructure mobilization influence the safe operating space of regulated exploited ecosystems?
Jean-Denis Mathias | Published Tuesday, July 17, 2018Decision-makers often have to act before critical times to avoid the collapse of ecosystems using knowledge \textcolor{red}{that can be incomplete or biased}. Adaptive management may help managers tackle such issues. However, because the knowledge infrastructure required for adaptive management may be mobilized in several ways, we study the quality and the quantity of knowledge provided by this knowledge infrastructure. In order to analyze the influence of mobilized knowledge, we study how the following typology of knowledge and its use may impact the safe operating space of exploited ecosystems: 1) knowledge of the past based on a time series distorted by measurement errors; 2) knowledge of the current systems’ dynamics based on the representativeness of the decision-makers’ mental models of the exploited ecosystem; 3) knowledge of future events based on decision-makers’ likelihood estimates of extreme events based on modeling infrastructure (models and experts to interpret them) they have at their disposal. We consider different adaptive management strategies of a general regulated exploited ecosystem model and we characterize the robustness of these strategies to biased knowledge. Our results show that even with significant mobilized knowledge and optimal strategies, imperfect knowledge may still shrink the safe operating space of the system leading to the collapse of the system. However, and perhaps more interestingly, we also show that in some cases imperfect knowledge may unexpectedly increase the safe operating space by suggesting cautious strategies.
The code enables to calculate the safe operating spaces of different managers in the case of biased and unbiased knowledge.
Peer reviewed Collectivities
Nigel Gilbert | Published Tuesday, April 09, 2019 | Last modified Thursday, August 22, 2019The model that simulates the dynamic creation and maintenance of knowledge-based formations such as communities of scientists, fashion movements, and subcultures. The model’s environment is a spatial one, representing not geographical space, but a “knowledge space” in which each point is a different collection of knowledge elements. Agents moving through this space represent people’s differing and changing knowledge and beliefs. The agents have only very simple behaviors: If they are “lonely,” that is, far from a local concentration of agents, they move toward the crowd; if they are crowded, they move away.
Running the model shows that the initial uniform random distribution of agents separates into “clumps,” in which some agents are central and others are distributed around them. The central agents are crowded, and so move. In doing so, they shift the centroid of the clump slightly and may make other agents either crowded or lonely, and they too will move. Thus, the clump of agents, although remaining together for long durations (as measured in time steps), drifts across the view. Lonely agents move toward the clump, sometimes joining it and sometimes continuing to trail behind it. The clumps never merge.
The model is written in NetLogo (v6). It is used as a demonstration of agent-based modelling in Gilbert, N. (2008) Agent-Based Models (Quantitative Applications in the Social Sciences). Sage Publications, Inc. and described in detail in Gilbert, N. (2007) “A generic model of collectivities,” Cybernetics and Systems. European Meeting on Cybernetic Science and Systems Research, 38(7), pp. 695–706.
Peer reviewed AgModel
Isaac Ullah | Published Friday, December 06, 2024AgModel is an agent-based model of the forager-farmer transition. The model consists of a single software agent that, conceptually, can be thought of as a single hunter-gather community (i.e., a co-residential group that shares in subsistence activities and decision making). The agent has several characteristics, including a population of human foragers, intrinsic birth and death rates, an annual total energy need, and an available amount of foraging labor. The model assumes a central-place foraging strategy in a fixed territory for a two-resource economy: cereal grains and prey animals. The territory has a fixed number of patches, and a starting number of prey. While the model is not spatially explicit, it does assume some spatiality of resources by including search times.
Demographic and environmental components of the simulation occur and are updated at an annual temporal resolution, but foraging decisions are “event” based so that many such decisions will be made in each year. Thus, each new year, the foraging agent must undertake a series of optimal foraging decisions based on its current knowledge of the availability of cereals and prey animals. Other resources are not accounted for in the model directly, but can be assumed for by adjusting the total number of required annual energy intake that the foraging agent uses to calculate its cereal and prey animal foraging decisions. The agent proceeds to balance the net benefits of the chance of finding, processing, and consuming a prey animal, versus that of finding a cereal patch, and processing and consuming that cereal. These decisions continue until the annual kcal target is reached (balanced on the current human population). If the agent consumes all available resources in a given year, it may “starve”. Starvation will affect birth and death rates, as will foraging success, and so the population will increase or decrease according to a probabilistic function (perturbed by some stochasticity) and the agent’s foraging success or failure. The agent is also constrained by labor caps, set by the modeler at model initialization. If the agent expends its yearly budget of person-hours for hunting or foraging, then the agent can no longer do those activities that year, and it may starve.
Foragers choose to either expend their annual labor budget either hunting prey animals or harvesting cereal patches. If the agent chooses to harvest prey animals, they will expend energy searching for and processing prey animals. prey animals search times are density dependent, and the number of prey animals per encounter and handling times can be altered in the model parameterization (e.g. to increase the payoff per encounter). Prey animal populations are also subject to intrinsic birth and death rates with the addition of additional deaths caused by human predation. A small amount of prey animals may “migrate” into the territory each year. This prevents prey animals populations from complete decimation, but also may be used to model increased distances of logistic mobility (or, perhaps, even residential mobility within a larger territory).
…
DARTS: an agent-based model of the global food system for studying its resilience to shocks
Hubert Fonteijn | Published Wednesday, November 22, 2023DARTS simulates food systems in which agents produce, consume and trade food. Here, food is a summary item that roughly corresponds to commodity food types (e.g. rice). No other food types are taken into account. Each food system (World) consists of its own distribution of agents, regions and connections between agents. Agents differ in their ability to produce food, earn off-farm income and trade food. The agents aim to satisfy their food requirements (which are fixed and equal across agents) by either their own food production or by food purchases. Each simulation step represents one month, in which agents can produce (if they have productive capacity and it is a harvest month for their region), earn off-farm income, trade food (both buy and sell) and consume food. We evaluate the performance of the food system by averaging the agents’ food satisfaction, which is defined as the ratio of the food consumed by each agent at the end of each month divided by her food requirement. At each step, any of the abovementioned attributes related to the agents’ ability to satisfy their food requirement can (temporarily) be shocked. These shocks include reducing the amount of food they produce, removing their ability to trade locally or internationally and reducing their cash savings. Food satisfaction is quantified (both immediately after the shock and in the year following the shock) to evaluate food security of a particular food system, both at the level of agent types (e.g. the urban poor and the rural poor) and at the systems level. Thus, the effects of shocks on food security can be related to the food system’s structure.
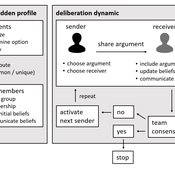
Agent-based model of team decision-making in hidden profile situations
Andreas Flache Jonas Stein Vincenz Frey | Published Thursday, April 20, 2023 | Last modified Friday, November 17, 2023The model presented here is extensively described in the paper ‘Talk less to strangers: How homophily can improve collective decision-making in diverse teams’ (forthcoming at JASSS). A full replication package reproducing all results presented in the paper is accessible at https://osf.io/76hfm/.
Narrative documentation includes a detailed description of the model, including a schematic figure and an extensive representation of the model in pseudocode.
The model develops a formal representation of a diverse work team facing a decision problem as implemented in the experimental setup of the hidden-profile paradigm. We implement a setup where a group seeks to identify the best out of a set of possible decision options. Individuals are equipped with different pieces of information that need to be combined to identify the best option. To this end, we assume a team of N agents. Each agent belongs to one of M groups where each group consists of agents who share a common identity.
The virtual teams in our model face a decision problem, in that the best option out of a set of J discrete options needs to be identified. Every team member forms her own belief about which decision option is best but is open to influence by other team members. Influence is implemented as a sequence of communication events. Agents choose an interaction partner according to homophily h and take turns in sharing an argument with an interaction partner. Every time an argument is emitted, the recipient updates her beliefs and tells her team what option she currently believes to be best. This influence process continues until all agents prefer the same option. This option is the team’s decision.
Displaying 10 of 352 results for "Tim Dorscheidt" clear search