Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 216 results Data clear search
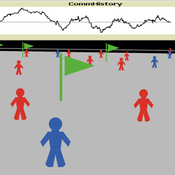
Model of communication between two groups of managers in the course of project implementation
Smarzhevskiy Ivan | Published Monday, December 07, 2020This is a simulation model of communication between two groups of managers in the course of project implementation. The “world” of the model is a space of interaction between project participants, each of which belongs either to a group of work performers or to a group of customers. Information about the progress of the project is publicly available and represents the deviation Earned value (EV) from the planned project value (cost baseline).
The key elements of the model are 1) persons belonging to a group of customers or performers, 2) agents that are communication acts. The life cycle of persons is equal to the time of the simulation experiment, the life cycle of the communication act is 3 periods of model time (for the convenience of visualizing behavior during the experiment). The communication act occurs at a specific point in the model space, the coordinates of which are realized as random variables. During the experiment, persons randomly move in the model space. The communication act involves persons belonging to a group of customers and a group of performers, remote from the place of the communication act at a distance not exceeding the value of the communication radius (MaxCommRadius), while at least one representative from each of the groups must participate in the communication act. If none are found, the communication act is not carried out. The number of potential communication acts per unit of model time is a parameter of the model (CommPerTick).
The managerial sense of the feedback is the stimulating effect of the positive value of the accumulated communication complexity (positive background of the project implementation) on the productivity of the performers. Provided there is favorable communication (“trust”, “mutual understanding”) between the customer and the contractor, it is more likely that project operations will be performed with less lag behind the plan or ahead of it.
The behavior of agents in the world of the model (change of coordinates, visualization of agents’ belonging to a specific communicative act at a given time, etc.) is not informative. Content data are obtained in the form of time series of accumulated communicative complexity, the deviation of the earned value from the planned value, average indicators characterizing communication - the total number of communicative acts and the average number of their participants, etc. These data are displayed on graphs during the simulation experiment.
The control elements of the model allow seven independent values to be varied, which, even with a minimum number of varied values (three: minimum, maximum, optimum), gives 3^7 = 2187 different variants of initial conditions. In this case, the statistical processing of the results requires repeated calculation of the model indicators for each grid node. Thus, the set of varied parameters and the range of their variation is determined by the logic of a particular study and represents a significant narrowing of the full set of initial conditions for which the model allows simulation experiments.
…
Virus Spread on Broad-degree-distribution Network.
Gianluca Manzo | Published Friday, July 24, 2020The model simulates the spread of a virus through a synthetic network with a degree distribution calibrated on close-range contact data. The model is used to study the macroscopic consequences of cross-individual variability in close-range contact frequencies and to assess whether this variability can be exploited for effective intervention targeting high-contact nodes.
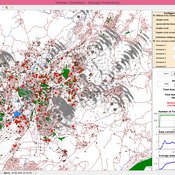
Hybrid individual- and particle-based simulation model and data on air pollutants and vertical greenery systems in the city of Yerevan, Armenia
Andranik Akopov | Published Friday, June 19, 2020Urban greenery such as vertical greenery systems (VGS) can effectively absorb air pollutants emitted by different agents, such as vehicles and manufacturing enterprises. The main challenge is how to protect socially important objects, such as kindergartens, from the influence if air pollution with the minimum of expenditure. There is proposed the hybrid individual- and particle-based model of interactions between vertical greenery systems and air pollutants to identify optimal locations of tree clusters and high-rise buildings where horizontal greenery systems and VGS should be implemented, respectively. The model is implemented in the AnyLogic simulation tool.
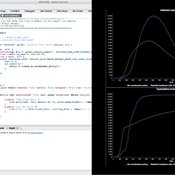
Peer reviewed COMOKIT
Patrick Taillandier Alexis Drogoul Benoit Gaudou Kevin Chapuis Nghi Huyng Quang Doanh Nguyen Ngoc Arthur Brugière Pierre Larmande Marc Choisy Damien Philippon | Published Tuesday, May 26, 2020 | Last modified Wednesday, July 01, 2020In the face of the COVID-19 pandemic, public health authorities around the world have experimented, in a short period of time, with various combinations of interventions at different scales. However, as the pandemic continues to progress, there is a growing need for tools and methodologies to quickly analyze the impact of these interventions and answer concrete questions regarding their effectiveness, range and temporality.
COMOKIT, the COVID-19 modeling kit, is such a tool. It is a computer model that allows intervention strategies to be explored in silico before their possible implementation phase. It can take into account important dimensions of policy actions, such as the heterogeneity of individual responses or the spatial aspect of containment strategies.
In COMOKIT, built using the agent-based modeling and simulation platform GAMA, the profiles, activities and interactions of people, person-to-person and environmental transmissions, individual clinical statuses, public health policies and interventions are explicitly represented and they all serve as a basis for describing the dynamics of the epidemic in a detailed and realistic representation of space.
…

Simulating Sustainability of Collective Awareness Platform for Sustainability and Social Innovation (CAPS)
Peter Gerbrands | Published Friday, May 08, 2020In an associated paper which focuses on analyzing the structure of several egocentric networks of collective awareness platforms for sustainable innovation (CAPS), this model is developed. It answers the question whether the network structure is determinative for the sustainability of the created awareness. Based on a thorough literature review a model is developed to explain and operationalize the concept of sustainability of a social network in terms of importance, effectiveness and robustness. By developing this agent-based model, the expected outcomes after the dissolution of the CAPS are predicted and compared with the results of a network with the same participants but with different ties. Twitter data from different CAPS is collected and used to feed the simulation. The results show that the structure of the network is of key importance for its sustainability. With this knowledge and the ability to simulate the results after network changes have taken place, CAPS can assess the sustainability of their legacy and actively steer towards a longer lasting potential for social innovation. The retrieved knowledge urges organizations like the European Commission to adopt a more blended approach focusing not only on solving societal issues but on building a community to sustain the initiated development.
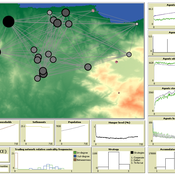
AncientS-ABM: Agent-Based Modeling of Past Societies Social Organization
Angelos Chliaoutakis | Published Thursday, April 09, 2020AncientS-ABM is an agent-based model for simulating and evaluating the potential social organization of an artificial past society, configured by available archaeological data. Unlike most existing agent-based models used in archaeology, our ABM framework includes completely autonomous, utility-based agents. It also incorporates different social organization paradigms, different decision-making processes, and also different cultivation technologies used in ancient societies. Equipped with such paradigms, the model allows us to explore the transition from a simple to a more complex society by focusing on the historical social dynamics; and to assess the influence of social organization on agents’ population growth, agent community numbers, sizes and distribution.
AncientS-ABM also blends ideas from evolutionary game theory with multi-agent systems’ self-organization. We model the evolution of social behaviours in a population of strategically interacting agents in repeated games where they exchange resources (utility) with others. The results of the games contribute to both the continuous re-organization of the social structure, and the progressive adoption of the most successful agent strategies. Agent population is not fixed, but fluctuates over time, while agents in stage games also receive non-static payoffs, in contrast to most games studied in the literature. To tackle this, we defined a novel formulation of the evolutionary dynamics via assessing agents’ rather than strategies’ fitness.
As a case study, we employ AncientS-ABM to evaluate the impact of the implemented social organization paradigms on an artificial Bronze Age “Minoan” society, located at different geographical parts of the island of Crete, Greece. Model parameter choices are based on archaeological evidence and studies, but are not biased towards any specific assumption. Results over a number of different simulation scenarios demonstrate better sustainability for settlements consisting of and adopting a socio-economic organization model based on self-organization, where a “heterarchical” social structure emerges. Results also demonstrate that successful agent societies adopt an evolutionary approach where cooperation is an emergent strategic behaviour. In simulation scenarios where the natural disaster module was enabled, we observe noticeable changes in the settlements’ distribution, relating to significantly higher migration rates immediately after the modeled Theran eruption. In addition, the initially cooperative behaviour is transformed to a non-cooperative one, thus providing support for archaeological theories suggesting that the volcanic eruption led to a clear breakdown of the Minoan socio-economic system.
…

Peer reviewed Neighbor Influenced Energy Retrofit (NIER) agent-based model
Eric Boria | Published Friday, April 03, 2020The NIER model is intended to add qualitative variables of building owner types and peer group scales to existing energy efficiency retrofit adoption models. The model was developed through a combined methodology with qualitative research, which included interviews with key stakeholders in Cleveland, Ohio and Detroit and Grand Rapids, Michigan. The concepts that the NIER model adds to traditional economic feasibility studies of energy retrofit decision-making are differences in building owner types (reflecting strategies for managing buildings) and peer group scale (neighborhoods of various sizes and large-scale Districts). Insights from the NIER model include: large peer group comparisons can quickly raise the average energy efficiency values of Leader and Conformist building owner types, but leave Stigma-avoider owner types as unmotivated to retrofit; policy interventions such as upgrading buildings to energy-related codes at the point of sale can motivate retrofits among the lowest efficient buildings, which are predominantly represented by the Stigma-avoider type of owner; small neighborhood peer groups can successfully amplify normal retrofit incentives.
Peer reviewed BAMERS: Macroeconomic effect of extortion
Alejandro Platas López Alejandro Guerra-Hernández | Published Monday, March 23, 2020 | Last modified Sunday, July 26, 2020Inspired by the European project called GLODERS that thoroughly analyzed the dynamics of extortive systems, Bottom-up Adaptive Macroeconomics with Extortion (BAMERS) is a model to study the effect of extortion on macroeconomic aggregates through simulation. This methodology is adequate to cope with the scarce data associated to the hidden nature of extortion, which difficults analytical approaches. As a first approximation, a generic economy with healthy macroeconomics signals is modeled and validated, i.e., moderate inflation, as well as a reasonable unemployment rate are warranteed. Such economy is used to study the effect of extortion in such signals. It is worth mentioning that, as far as is known, there is no work that analyzes the effects of extortion on macroeconomic indicators from an agent-based perspective. Our results show that there is significant effects on some macroeconomics indicators, in particular, propensity to consume has a direct linear relationship with extortion, indicating that people become poorer, which impacts both the Gini Index and inflation. The GDP shows a marked contraction with the slightest presence of extortion in the economic system.
Exploring Urban Shrinkage
Andrew Crooks | Published Thursday, March 19, 2020While the world’s total urban population continues to grow, this growth is not equal. Some cities are declining, resulting in urban shrinkage which is now a global phenomenon. Many problems emerge due to urban shrinkage including population loss, economic depression, vacant properties and the contraction of housing markets. To explore this issue, this paper presents an agent-based model stylized on spatially explicit data of Detroit Tri-county area, an area witnessing urban shrinkage. Specifically, the model examines how micro-level housing trades impact urban shrinkage by capturing interactions between sellers and buyers within different sub-housing markets. The stylized model results highlight not only how we can simulate housing transactions but the aggregate market conditions relating to urban shrinkage (i.e., the contraction of housing markets). To this end, the paper demonstrates the potential of simulation to explore urban shrinkage and potentially offers a means to test polices to alleviate this issue.
Artificial Long House Valley-Black Mesa
Lisa Sattenspiel Amy Warren | Published Thursday, March 19, 2020This model is an extension of the Artificial Long House Valley (ALHV) model developed by the authors (Swedlund et al. 2016; Warren and Sattenspiel 2020). The ALHV model simulates the population dynamics of individuals within the Long House Valley of Arizona from AD 800 to 1350. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. The present version of the model incorporates features of the ALHV model including realistic age-specific fertility and mortality and, in addition, it adds the Black Mesa environment and population, as well as additional methods to allow migration between the two regions.
As is the case for previous versions of the ALHV model as well as the Artificial Anasazi (AA) model from which the ALHV model was derived (Axtell et al. 2002; Janssen 2009), this version makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original AA model to estimate annual maize productivity of various agricultural zones within the Long House Valley. A new environment and associated methods have been developed for Black Mesa. Productivity estimates from both regions are used to determine suitable locations for households and farms during each year of the simulation.
Displaying 10 of 216 results Data clear search