Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 127 results for "Nathan Ryan" clear search
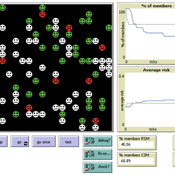
Risk-Sharing under Heterogeneity: NetLogo simulation
Eva Vriens | Published Monday, February 28, 2022Motivated by the emergence of new Peer-to-Peer insurance organizations that rethink how insurance is organized, we propose a theoretical model of decision-making in risk-sharing arrangements with risk heterogeneity and incomplete information about the risk distribution as core features. For these new, informal organisations, the available institutional solutions to heterogeneity (e.g., mandatory participation or price differentiation) are either impossible or undesirable. Hence, we need to understand the scope conditions under which individuals are motivated to participate in a bottom-up risk-sharing setting. The model puts forward participation as a utility maximizing alternative for agents with higher risk levels, who are more risk averse, are driven more by solidarity motives, and less susceptible to cost fluctuations. This basic micro-level model is used to simulate decision-making for agent populations in a dynamic, interdependent setting. Simulation results show that successful risk-sharing arrangements may work if participants are driven by motivations of solidarity or risk aversion, but this is less likely in populations more heterogeneous in risk, as the individual motivations can less often make up for the larger cost deficiencies. At the same time, more heterogeneous groups deal better with uncertainty and temporary cost fluctuations than more homogeneous populations do. In the latter, cascades following temporary peaks in support requests more often result in complete failure, while under full information about the risk distribution this would not have happened.
VIDA: A simulation model of domestic VIolence in times of social DistAncing
Bernardo Furtado | Published Monday, January 11, 2021Violence against women occurs predominantly in the family and domestic context. The COVID-19 pandemic led Brazil to recommend and, at times, impose social distancing, with the partial closure of economic activities, schools, and restrictions on events and public services. Preliminary evidence shows that intense co- existence increases domestic violence, while social distancing measures may have prevented access to public services and networks, information, and help. We propose an agent-based model (ABM), called VIDA, to illustrate and examine multi-causal factors that influence events that generate violence. A central part of the model is the multi-causal stress indicator, created as a probability trigger of domestic violence occurring within the family environment. Two experimental design tests were performed: (a) absence or presence of the deterrence system of domestic violence against women and measures to increase social distancing. VIDA presents comparative results for metropolitan regions and neighbourhoods considered in the experiments. Results suggest that social distancing measures, particularly those encouraging staying at home, may have increased domestic violence against women by about 10%. VIDA suggests further that more populated areas have comparatively fewer cases per hundred thousand women than less populous capitals or rural areas of urban concentrations. This paper contributes to the literature by formalising, to the best of our knowledge, the first model of domestic violence through agent-based modelling, using empirical detailed socioeconomic, demographic, educational, gender, and race data at the intraurban level (census sectors).
This model extends the original Artifical Anasazi (AA) model to include individual agents, who vary in age and sex, and are aggregated into households. This allows more realistic simulations of population dynamics within the Long House Valley of Arizona from AD 800 to 1350 than are possible in the original model. The parts of this model that are directly derived from the AA model are based on Janssen’s 1999 Netlogo implementation of the model; the code for all extensions and adaptations in the model described here (the Artificial Long House Valley (ALHV) model) have been written by the authors. The AA model included only ideal and homogeneous “individuals” who do not participate in the population processes (e.g., birth and death)–these processes were assumed to act on entire households only. The ALHV model incorporates actual individual agents and all demographic processes affect these individuals. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. Thus, the ALHV model is a combination of individual processes (birth and death) and household-level processes (e.g., finding suitable agriculture plots).
As is the case for the AA model, the ALHV model makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original model (from Janssen’s Netlogo implementation) to estimate annual maize productivity of various agricultural zones within the valley. These estimates are used to determine suitable locations for households and farms during each year of the simulation.
Peer reviewed SIM-VOLATILE: Adoption of emerging circular technologies in the waste-treatment sector
Siavash Farahbakhsh | Published Wednesday, December 14, 2022The SIM-VOLATILE model is a technology adoption model at the population level. The technology, in this model, is called Volatile Fatty Acid Platform (VFAP) and it is in the frame of the circular economy. The technology is considered an emerging technology and it is in the optimization phase. Through the adoption of VFAP, waste-treatment plants will be able to convert organic waste into high-end products rather than focusing on the production of biogas. Moreover, there are three adoption/investment scenarios as the technology enables the production of polyhydroxyalkanoates (PHA), single-cell oils (SCO), and polyunsaturated fatty acids (PUFA). However, due to differences in the processing related to the products, waste-treatment plants need to choose one adoption scenario.
In this simulation, there are several parameters and variables. Agents are heterogeneous waste-treatment plants that face the problem of circular economy technology adoption. Since the technology is emerging, the adoption decision is associated with high risks. In this regard, first, agents evaluate the economic feasibility of the emerging technology for each product (investment scenarios). Second, they will check on the trend of adoption in their social environment (i.e. local pressure for each scenario). Third, they combine these two economic and social assessments with an environmental assessment which is their environmental decision-value (i.e. their status on green technology). This combination gives the agent an overall adaptability fitness value (detailed for each scenario). If this value is above a certain threshold, agents may decide to adopt the emerging technology, which is ultimately depending on their predominant adoption probabilities and market gaps.
Peer reviewed Yards
srailsback Emily Minor Soraida Garcia Philip Johnson | Published Thursday, November 02, 2023This is a model of plant communities in urban and suburban residential neighborhoods. These plant communities are of interest because they provide many benefits to human residents and also provide habitat for wildlife such as birds and pollinators. The model was designed to explore the social factors that create spatial patterns in biodiversity in yards and gardens. In particular, the model was originally developed to determine whether mimicry behaviors–-or neighbors copying each other’s yard design–-could produce observed spatial patterns in vegetation. Plant nurseries and socio-economic constraints were also added to the model as other potential sources of spatial patterns in plant communities.
The idea for the model was inspired by empirical patterns of spatial autocorrelation that have been observed in yard vegetation in Chicago, Illinois (USA), and other cities, where yards that are closer together are more similar than yards that are farther apart. The idea is further supported by literature that shows that people want their yards to fit into their neighborhood. Currently, the yard attribute of interest is the number of plant species, or species richness. Residents compare the richness of their yards to the richness of their neighbors’ yards. If a resident’s yard is too different from their neighbors, the resident will be unhappy and change their yard to make it more similar.
The model outputs information about the diversity and identity of plant species in each yard. This can be analyzed to look for spatial autocorrelation patterns in yard diversity and to explore relationships between mimicry behaviors, yard diversity, and larger scale diversity.
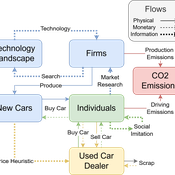
Driving in the wrong direction? A co-evolutionary model of electric vehicle adoption and innovation
Daniel Torren-Peraire | Published Friday, July 11, 2025Car-centric societies face substantial challenges in moving towards sustainable
mobility systems, with internal combustion engine vehicles remaining a major
source of emissions. Electric vehicles play a critical role in addressing this challenge, yet their diffusion depends on the interaction of consumer behaviour, firm
innovation, and policy incentives. This paper develops an agent-based model to
examine these dynamics, calibrated on the data for the state of California over
2001-2023. In the model, heterogeneous car users influenced by their social peers
…
Negotiation Lab 1.0
Julián Arévalo | Published Friday, March 20, 2026Negotiation Lab 1.0 is an agent-based model of peace negotiations that explores how the parties’ readiness — their motivation and optimism to engage in talks — evolves dynamically throughout the negotiation process. The model reconceptualizes readiness as an adaptive state variable that is continuously updated through feedback from negotiation outcomes, rather than a static precondition assessed at the onset of talks.
The model simulates two parties negotiating a multi-issue agenda. In each round, parties allocate effort to the current sub-issue; outcomes depend on their joint effort and a stochastic component representing external factors. Results feed back into each party’s readiness, shaping subsequent engagement. The negotiation ends either when all agenda items are resolved (agreement) or when a party’s readiness falls below a critical threshold (breakdown).
Key parameters include the initial readiness of each party, agenda structure (balanced, hard, easy, red, or random), type of negotiation (from highly cooperative to highly competitive), and each party’s effort strategy (always high, always low, random, or pseudo tit-for-tat). The model shows that while initial readiness is associated with negotiation outcomes, it is neither necessary nor sufficient to determine them: process variables — the type of interaction, agenda design, and adaptive effort strategies — exert comparatively larger effects on outcomes. Identical initial conditions can produce widely divergent trajectories, illustrating path dependence and sensitivity to feedback dynamics.
The model is implemented in NetLogo 7.0 and is documented using the ODD+D protocol. It is associated with the paper “Beyond Initial Conditions: How Adaptive Readiness Shapes Peace Negotiation Outcomes” (Arévalo, under review).
Thermostat II
María Pereda Jesús M Zamarreño | Published Thursday, June 12, 2014 | Last modified Monday, June 16, 2014A thermostat is a device that allows to have the temperature in a room near a desire value.
A Model of Iterated Ultimatum game
Andrea Scalco | Published Tuesday, February 24, 2015 | Last modified Monday, March 09, 2015The simulation generates two kinds of agents, whose proposals are generated accordingly to their selfish or selfless behaviour. Then, agents compete in order to increase their portfolio playing the ultimatum game with a random-stranger matching.

Segregation and Opinion Polarization
Thomas Feliciani Andreas Flache Jochem Tolsma | Published Wednesday, April 13, 2016This is a tool to explore the effects of groups´ spatial segregation on the emergence of opinion polarization. It embeds two opinion formation models: a model of negative (and positive) social influence and a model of persuasive argument exchange.
Displaying 10 of 127 results for "Nathan Ryan" clear search