Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 110 results for "N%20W%C3%A4ckerlin" clear search

Simulating Climate Stress and Social Instability: An Agent-Based Model of Ecosystem Degradation and Violence in Coastal Communities
Jacopo A. Baggio hurtado-valdivieso | Published Sunday, April 12, 2026This model is an agent-based simulation designed to explore how climate-induced environmental degradation can contribute to the emergence of social violence in coastal communities that depend heavily on ecosystem services for their livelihoods. The model represents a coupled social–ecological system in which environmental shocks—such as sea level rise and marine ecosystem decline—affect local economic conditions, food security, and community stability.
Agents in the model represent individuals whose livelihoods depend on coastal ecosystems. Environmental degradation reduces ecosystem productivity and increases economic hardship, which can lead to the formation of grievances among agents. The model incorporates behavioral thresholds that determine how individuals respond to hardship and perceived injustice. Under certain conditions—particularly when institutional capacity and law enforcement effectiveness are limited—these grievances may escalate into violent behavior.
The simulation allows users to explore how different climate scenarios, levels of ecosystem degradation, livelihood dependence, and institutional responses influence the probability of social instability and violence. By modeling the interactions between environmental stress, socio-economic vulnerability, and governance capacity, the model provides a computational framework for examining potential pathways linking climate change and conflict in coastal social–ecological systems.
…
Urban Teacher Lifecycle and Mobility
Yevgeny Patarakin | Published Wednesday, July 23, 2025This agent-based model simulates the lifecycle, movement, and satisfaction of teachers within an urban educational system composed of multiple universities and schools. Each teacher agent transitions through several possible roles: newcomer, university student, unemployed graduate, and employed teacher. Teachers’ pathways are shaped by spatial configuration, institutional capacities, individual characteristics, and dynamic interactions with schools and universities. Universities are assigned spatial locations with a controllable level of centralization and are characterized by academic ratings, capacity, and alumni records. Schools are distributed throughout the city, each with a limited number of vacancies, hiring requirements, and offered salaries. Teachers apply to universities based on the alignment of their personal academic profiles with institutional ratings, pursue studies, and upon graduation become candidates for employment at schools.
The employment process is driven by a decentralized matching of teacher expectations and school offers, taking into account factors such as salary, proximity, and peer similarity. Teachers’ satisfaction evolves over time, reflecting both institutional characteristics and the composition of their colleagues; low satisfaction may prompt teachers to transfer between schools within their mobility radius. Mortality and teacher attrition further shape workforce dynamics, leading to continuous recruitment of newcomers to maintain a stable population. The model tracks university reputation through the academic performance and number of alumni, and visualizes key metrics including teacher status distribution, school staffing, university alumni counts, and overall satisfaction. This structure enables the exploration of policy interventions, hiring and training strategies, and the impact of spatial and institutional design on the allocation, retention, and happiness of urban educational staff.
A simplified Arthur & Polak logic circuit model of combinatory technology build-out via incremental development. Only some inventions trigger radical effects, suggesting they depend on whole interdependent systems rather than specific innovations.
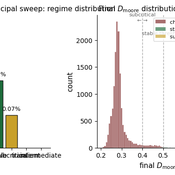
The Informational Assumptions of Schelling Segregation: An Agent-Based Decomposition of Cue Inference, Cultural Schemas, and Residential Sorting
Eric Gladstone | Published Wednesday, May 13, 2026This computational model accompanies the article “The Informational Assumptions of Schelling Segregation: An Agent-Based Decomposition of Cue Inference, Cultural Schemas, and Residential Sorting.” It implements an agent-based model in which agents infer latent neighborhood-type classes from noisy non-demographic cues through schema-specific diagnostic mappings, update beliefs, and relocate when satisfaction on a preferred latent class falls below a threshold.
The model serves as a mechanism-isolation device for studying the informational architecture underlying Schelling-style residential sorting. It includes the principal sweep configuration (14,400 runs across a seven-parameter grid), a disagreement-metric sub-sweep with permutation-minimized Jensen-Shannon divergence recorded natively, controls (positive, negative, and frozen-belief), a paired-seed cue-channel perturbation experiment, and selected-cell sensitivity sweeps for cue persistence and home-biased mobility.
The full ODD protocol, parameter manifests, deterministic seed schedules, processed outputs, regenerable figure scripts, the verification test suite, and the satisfaction-mapping audit document are included. Every reported run is deterministic given a (config, seed) pair, and an included audit script verifies bit-for-bit replay on sampled runs.
Exploring the aftermath of transition failures: An agent-based model
Gangmin Park Junmin Lee Jisoo Lee Keungoui Kim | Published Friday, March 06, 2026This computational model is an agent-based model (ABM) developed to investigate how repeated failures of emerging niches accumulate and influence the trajectory of socio-technical transitions. Built in AnyLogic 8.7.11, the model simulates the dynamic interactions between a dominant regime and sequential niche entrants within a two-dimensional practice space. It models alignment, movement, and competition based on technological maturity and market penetration. The model utilizes a reinforcing feedback structure linking consumer support, output, resource accumulation, and capacity development (Physical and Institutional Capacity). A complete model specification following the ODD+D (Overview, Design concepts, Details, and Decision) protocol is included in the documentation.
Peer reviewed BAM: The Bottom-up Adaptive Macroeconomics Model
Alejandro Platas López Alejandro Guerra-Hernández | Published Tuesday, January 14, 2020 | Last modified Sunday, July 26, 2020Overview
Purpose
Modeling an economy with stable macro signals, that works as a benchmark for studying the effects of the agent activities, e.g. extortion, at the service of the elaboration of public policies..
…

Peer reviewed Neighbor Influenced Energy Retrofit (NIER) agent-based model
Eric Boria | Published Friday, April 03, 2020The NIER model is intended to add qualitative variables of building owner types and peer group scales to existing energy efficiency retrofit adoption models. The model was developed through a combined methodology with qualitative research, which included interviews with key stakeholders in Cleveland, Ohio and Detroit and Grand Rapids, Michigan. The concepts that the NIER model adds to traditional economic feasibility studies of energy retrofit decision-making are differences in building owner types (reflecting strategies for managing buildings) and peer group scale (neighborhoods of various sizes and large-scale Districts). Insights from the NIER model include: large peer group comparisons can quickly raise the average energy efficiency values of Leader and Conformist building owner types, but leave Stigma-avoider owner types as unmotivated to retrofit; policy interventions such as upgrading buildings to energy-related codes at the point of sale can motivate retrofits among the lowest efficient buildings, which are predominantly represented by the Stigma-avoider type of owner; small neighborhood peer groups can successfully amplify normal retrofit incentives.
This model extends the original Artifical Anasazi (AA) model to include individual agents, who vary in age and sex, and are aggregated into households. This allows more realistic simulations of population dynamics within the Long House Valley of Arizona from AD 800 to 1350 than are possible in the original model. The parts of this model that are directly derived from the AA model are based on Janssen’s 1999 Netlogo implementation of the model; the code for all extensions and adaptations in the model described here (the Artificial Long House Valley (ALHV) model) have been written by the authors. The AA model included only ideal and homogeneous “individuals” who do not participate in the population processes (e.g., birth and death)–these processes were assumed to act on entire households only. The ALHV model incorporates actual individual agents and all demographic processes affect these individuals. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. Thus, the ALHV model is a combination of individual processes (birth and death) and household-level processes (e.g., finding suitable agriculture plots).
As is the case for the AA model, the ALHV model makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original model (from Janssen’s Netlogo implementation) to estimate annual maize productivity of various agricultural zones within the valley. These estimates are used to determine suitable locations for households and farms during each year of the simulation.
Artificial Long House Valley-Black Mesa
Lisa Sattenspiel Amy Warren | Published Thursday, March 19, 2020This model is an extension of the Artificial Long House Valley (ALHV) model developed by the authors (Swedlund et al. 2016; Warren and Sattenspiel 2020). The ALHV model simulates the population dynamics of individuals within the Long House Valley of Arizona from AD 800 to 1350. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. The present version of the model incorporates features of the ALHV model including realistic age-specific fertility and mortality and, in addition, it adds the Black Mesa environment and population, as well as additional methods to allow migration between the two regions.
As is the case for previous versions of the ALHV model as well as the Artificial Anasazi (AA) model from which the ALHV model was derived (Axtell et al. 2002; Janssen 2009), this version makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original AA model to estimate annual maize productivity of various agricultural zones within the Long House Valley. A new environment and associated methods have been developed for Black Mesa. Productivity estimates from both regions are used to determine suitable locations for households and farms during each year of the simulation.
Cellular automata model of social networks
Rubens de Almeida Zimbres | Published Tuesday, August 02, 2022This project was developed during the Santa Fe course Introduction to Agent-Based Modeling 2022. The origin is a Cellular Automata (CA) model to simulate human interactions that happen in the real world, from Rubens and Oliveira (2009). These authors used a market research with real people in two different times: one at time zero and the second at time zero plus 4 months (longitudinal market research). They developed an agent-based model whose initial condition was inherited from the results of the first market research response values and evolve it to simulate human interactions with Agent-Based Modeling that led to the values of the second market research, without explicitly imposing rules. Then, compared results of the model with the second market research. The model reached 73.80% accuracy.
In the same way, this project is an Exploratory ABM project that models individuals in a closed society whose behavior depends upon the result of interaction with two neighbors within a radius of interaction, one on the relative “right” and other one on the relative “left”. According to the states (colors) of neighbors, a given cellular automata rule is applied, according to the value set in Chooser. Five states were used here and are defined as levels of quality perception, where red (states 0 and 1) means unhappy, state 3 is neutral and green (states 3 and 4) means happy.
There is also a message passing algorithm in the social network, to analyze the flow and spread of information among nodes. Both the cellular automaton and the message passing algorithms were developed using the Python extension. The model also uses extensions csv and arduino.
Displaying 10 of 110 results for "N%20W%C3%A4ckerlin" clear search