Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 31 results Traits clear search

Simulating Climate Stress and Social Instability: An Agent-Based Model of Ecosystem Degradation and Violence in Coastal Communities
Jacopo A. Baggio hurtado-valdivieso | Published Sunday, April 12, 2026This model is an agent-based simulation designed to explore how climate-induced environmental degradation can contribute to the emergence of social violence in coastal communities that depend heavily on ecosystem services for their livelihoods. The model represents a coupled social–ecological system in which environmental shocks—such as sea level rise and marine ecosystem decline—affect local economic conditions, food security, and community stability.
Agents in the model represent individuals whose livelihoods depend on coastal ecosystems. Environmental degradation reduces ecosystem productivity and increases economic hardship, which can lead to the formation of grievances among agents. The model incorporates behavioral thresholds that determine how individuals respond to hardship and perceived injustice. Under certain conditions—particularly when institutional capacity and law enforcement effectiveness are limited—these grievances may escalate into violent behavior.
The simulation allows users to explore how different climate scenarios, levels of ecosystem degradation, livelihood dependence, and institutional responses influence the probability of social instability and violence. By modeling the interactions between environmental stress, socio-economic vulnerability, and governance capacity, the model provides a computational framework for examining potential pathways linking climate change and conflict in coastal social–ecological systems.
…
Peer reviewed MicroAnts 2.5
Diogo Alves | Published Thursday, October 16, 2025MicroAnts 2.5 is a general-purpose agent-based model designed as a flexible workhorse for simulating ecological and evolutionary dynamics in artificial populations, as well as, potentially, the emergence of political institutions and economic regimes. It builds on and extends Stephen Wright’s original MicroAnts 2.0 by introducing configurable predators, inequality tracking, and other options.
Ant agents are of two tyes/casts and controlled by 16-bit chromosomes encoding traits such as vision, movement, mating thresholds, sensing, and combat strength. Predators (anteaters) operate in static, random, or targeted predatory modes. Ants reproduce, mutate, cooperate, fight, and die based on their traits and interactions. Environmental pressures (poison and predators) and social dynamics (sharing, mating, combat) drive emergent behavior across red and black ant populations.
The model supports insertion of custom agents at runtime, configurable mutation/inversion rates, and exports detailed statistics, including inequality metrics (e.g., Gini coefficients), trait frequencies, predator kills, and lineage data. Intended for rapid testing and educational experimentation, MicroAnts 2.5 serves as a modular base for more complex ecological and social simulations.
Peer reviewed AgModel
Isaac Ullah | Published Friday, December 06, 2024AgModel is an agent-based model of the forager-farmer transition. The model consists of a single software agent that, conceptually, can be thought of as a single hunter-gather community (i.e., a co-residential group that shares in subsistence activities and decision making). The agent has several characteristics, including a population of human foragers, intrinsic birth and death rates, an annual total energy need, and an available amount of foraging labor. The model assumes a central-place foraging strategy in a fixed territory for a two-resource economy: cereal grains and prey animals. The territory has a fixed number of patches, and a starting number of prey. While the model is not spatially explicit, it does assume some spatiality of resources by including search times.
Demographic and environmental components of the simulation occur and are updated at an annual temporal resolution, but foraging decisions are “event” based so that many such decisions will be made in each year. Thus, each new year, the foraging agent must undertake a series of optimal foraging decisions based on its current knowledge of the availability of cereals and prey animals. Other resources are not accounted for in the model directly, but can be assumed for by adjusting the total number of required annual energy intake that the foraging agent uses to calculate its cereal and prey animal foraging decisions. The agent proceeds to balance the net benefits of the chance of finding, processing, and consuming a prey animal, versus that of finding a cereal patch, and processing and consuming that cereal. These decisions continue until the annual kcal target is reached (balanced on the current human population). If the agent consumes all available resources in a given year, it may “starve”. Starvation will affect birth and death rates, as will foraging success, and so the population will increase or decrease according to a probabilistic function (perturbed by some stochasticity) and the agent’s foraging success or failure. The agent is also constrained by labor caps, set by the modeler at model initialization. If the agent expends its yearly budget of person-hours for hunting or foraging, then the agent can no longer do those activities that year, and it may starve.
Foragers choose to either expend their annual labor budget either hunting prey animals or harvesting cereal patches. If the agent chooses to harvest prey animals, they will expend energy searching for and processing prey animals. prey animals search times are density dependent, and the number of prey animals per encounter and handling times can be altered in the model parameterization (e.g. to increase the payoff per encounter). Prey animal populations are also subject to intrinsic birth and death rates with the addition of additional deaths caused by human predation. A small amount of prey animals may “migrate” into the territory each year. This prevents prey animals populations from complete decimation, but also may be used to model increased distances of logistic mobility (or, perhaps, even residential mobility within a larger territory).
…
How do bots influence beliefs on social media? Why do beliefs propagated by social bots spread far and wide, yet does their direct influence appear to be limited?
This model extends Axelrod’s model for the dissemination of culture (1997), with a social bot agent–an agent who only sends information and cannot be influenced themselves. The basic network is a ring network with N agents connected to k nearest neighbors. The agents have a cultural profile with F features and Q traits per feature. When two agents interact, the sending agent sends the trait of a randomly chosen feature to the receiving agent, who adopts this trait with a probability equal to their similarity. To this network, we add a bot agents who is given a unique trait on the first feature and is connected to a proportion of the agents in the model equal to ‘bot-connectedness’. At each timestep, the bot is chosen to spread one of its traits to its neighbors with a probility equal to ‘bot-activity’.
The main finding in this model is that, generally, bot activity and bot connectedness are both negatively related to the success of the bot in spreading its unique message, in equilibrium. The mechanism is that very active and well connected bots quickly influence their direct contacts, who then grow too dissimilar from the bot’s indirect contacts to quickly, preventing indirect influence. A less active and less connected bot leaves more space for indirect influence to occur, and is therefore more successful in the long run.
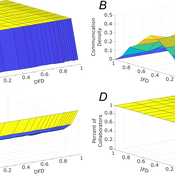
Role of Diversity in Team Performance: the Case of Missing Expertise, an Agent Based Simulations
Tamás Kiss | Published Friday, December 29, 2023This ABM simulates problem solving agents as they work on a set of tasks. Each agent has a trait vector describing their skills. Two agents might form a collaboration if their traits are similar enough. Tasks are defined by a component vector. Agents work on tasks by decreasing tasks’ component vectors towards zero.
The simulation generates agents with given intrapersonal functional diversity (IFD), and dominant function diversity (DFD), and a set of random tasks and evaluates how agents’ traits influence their level of communication and the performance of a team of agents.
Modeling results highlight the importance of the distributions of agents’ properties forming a team, and suggests that for a thorough description of management teams, not only diversity measures based on individual agents, but an aggregate measure is also required.
…
Peer reviewed Visibility of archaeological social networks
Claudine Gravel-Miguel | Published Sunday, November 26, 2023The purpose of this model is to explore the impact of combining archaeological palimpsests with different methods of cultural transmission on the visibility of prehistoric social networks. Up until recently, Paleolithic archaeologists have relied on stylistic similarities of artifacts to reconstruct social networks. However, this method - which is successfully applied to more recent ceramic assemblages - may not be applicable to Paleolithic assemblages, as several of those consist of palimpsests of occupations. Therefore, this model was created to study how palimpsests of occupation affect our social network reconstructions.
The model simplifies inter-groups interactions between populations who share cultural traits as they produce artifacts. It creates a proxy archaeological record of artifacts with stylistic traits that can then be used to reconstruct interactions. One can thus use this model to compare the networks reconstructed through stylistic similarities with direct contact.
An agent-based model of cultural change for a low-carbon transition
Daniel Torren-Peraire | Published Friday, November 10, 2023An ABM of changes in individuals’ lifestyles which considers their
evolving behavioural choices. Individuals have a set of environmental behavioural traits that spread through a fixed Watts–Strogatz graph via social interactions with their neighbours. These exchanges are mediated by transmission biases informing from whom an individual learns and
how much attention is paid. The influence of individuals on each other is a function of their similarity in environmental identity, where we represent environmental identity computationally by aggregating past agent attitudes towards multiple environmentally related behaviours. To perform a behaviour, agents must both have
a sufficiently positive attitude toward a behaviour and overcome a corresponding threshold. This threshold
structure, where the desire to perform a behaviour does not equal its enactment, allows for a lack of coherence
between attitudes and actual emissions. This leads to a disconnect between what people believe and what
…

Peer reviewed COMMONSIM: Simulating the utopia of COMMONISM
Lena Gerdes Manuel Scholz-Wäckerle Ernest Aigner Stefan Meretz Jens Schröter Hanno Pahl Annette Schlemm Simon Sutterlütti | Published Sunday, November 05, 2023This research article presents an agent-based simulation hereinafter called COMMONSIM. It builds on COMMONISM, i.e. a large-scale commons-based vision for a utopian society. In this society, production and distribution of means are not coordinated via markets, exchange, and money, or a central polity, but via bottom-up signalling and polycentric networks, i.e. ex-ante coordination via needs. Heterogeneous agents care for each other in life groups and produce in different groups care, environmental as well as intermediate and final means to satisfy sensual-vital needs. Productive needs decide on the magnitude of activity in groups for a common interest, e.g. the production of means in a multi-sectoral artificial economy. Agents share cultural traits identified by different behaviour: a propensity for egoism, leisure, environmentalism, and productivity. The narrative of this utopian society follows principles of critical psychology and sociology, complexity and evolution, the theory of commons, and critical political economy. The article presents the utopia and an agent-based study of it, with emphasis on culture-dependent allocation mechanisms and their social and economic implications for agents and groups.
Peer reviewed ABM to create populations with realistic Big Five Personality Trait Expressions
Michael Vogrin | Published Tuesday, May 30, 2023This model aims at creating agent populations that have “personalities”, as described by the Big Five Model of Personality. The expression of the Big Five in the agent population has the following properties, so that they resemble real life populations as closely as possible:
-The population mean of each trait is 0.5 on a scale from 0 to 1.
-The population-wide distribution of each trait approximates a normal distribution.
-The intercorrelations of the Big Five are close to those observed in the Literature.
The literature used to fit the model was a publication by Dimitri van der Linden, Jan te Nijenhuis, and Arnold B. Bakker:
…

Peer reviewed ArchMatNet: Archaeological Material Networks
Claudine Gravel-Miguel Robert Bischoff Cecilia Padilla-Iglesias | Published Monday, February 20, 2023The purpose of the model is to investigate how different factors affect the ability of researchers to reconstruct prehistoric social networks from artifact stylistic similarities, as well as the overall diversity of cultural traits observed in archaeological assemblages. Given that cultural transmission and evolution is affected by multiple interacting phenomena, our model allows to simultaneously explore six sets of factors that may condition how social networks relate to shared culture between individuals and groups:
- Factors relating to the structure of social groups
- Factors relating to the cultural traits in question
- Factors relating to individual learning strategies
- Factors relating to the environment
…
Displaying 10 of 31 results Traits clear search