Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 92 results scale clear search
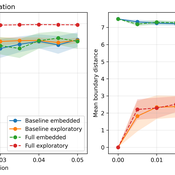
From Boundary Crossings to Global Connectivity: A Minimal Mechanism in Structured Agent-Based Landscapes
Fabio Nelli | Published Sunday, May 17, 2026This repository contains the Python implementation of an agent-based model investigating how localized boundary-crossing dynamics generate large-scale connectivity in structured multi-attractor landscapes.
Agents evolve in a continuous two-dimensional environment composed of attractor basins. A fraction of agents exhibits exploratory higher-mobility dynamics, while the remaining agents remain locally constrained. The model analyzes how localized configurational transitions accumulate into transition networks that progressively integrate the explored state space.
The repository includes:
…
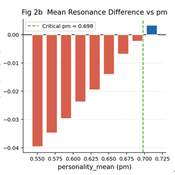
Zensei Wago: A Wealth-Integrated Social Capital Model
hiiki | Published Friday, May 15, 2026Interest-based compound economies generate monotonically increasing wealth inequality through multiplicative accumulation dynamics, yet the conditions under which gift-based reciprocal exchange outperforms such systems in collective well-being remain unquantified. We present Zensei Wago (全生和合), a seven-layer agent-based model comparing a Gift Resource Circulation (GRC) economy with a Compound Interest Circulation (CIC) economy under identical initial conditions. Across N = 5000 Monte Carlo replications (T = 700 ticks, N = 100 agents), GRC produced significantly higher collective resonance than CIC (p < 0.001, Cohen’s d = +0.171), above a critical prosocial threshold pm ≈ 0.698. Cohen’s d grows monotonically with duration — d = +1.943 at T = 1500 and d = +4.126 at T = 3000 — driven primarily by structural collapse of CIC resonance as inequality exceeds a critical Gini threshold (G > 0.333), while GRC resonance remains stable. The gift mechanism further decouples collective well-being from distributional outcomes, generating resonance through relational quality rather than material redistribution. Network topology analysis across seven configurations — combining a Watts-Strogatz rewiring sweep and a T = 1500 longitudinal replication — reveals that ring topology maximises GRC advantage (d = +1.17), that most topology-dependent reversals are transient (sparse and small-world both transition to significantly positive by T = 1500), and that a critical rewiring threshold of p ≈ 0.10–0.20 separates GRC-advantaged from GRC-disadvantaged network configurations. Scale-free networks remain persistently adverse (d = -7.24*), requiring structural redesign for gift-economy viability.

Simulating Climate Stress and Social Instability: An Agent-Based Model of Ecosystem Degradation and Violence in Coastal Communities
Jacopo A. Baggio hurtado-valdivieso | Published Sunday, April 12, 2026This model is an agent-based simulation designed to explore how climate-induced environmental degradation can contribute to the emergence of social violence in coastal communities that depend heavily on ecosystem services for their livelihoods. The model represents a coupled social–ecological system in which environmental shocks—such as sea level rise and marine ecosystem decline—affect local economic conditions, food security, and community stability.
Agents in the model represent individuals whose livelihoods depend on coastal ecosystems. Environmental degradation reduces ecosystem productivity and increases economic hardship, which can lead to the formation of grievances among agents. The model incorporates behavioral thresholds that determine how individuals respond to hardship and perceived injustice. Under certain conditions—particularly when institutional capacity and law enforcement effectiveness are limited—these grievances may escalate into violent behavior.
The simulation allows users to explore how different climate scenarios, levels of ecosystem degradation, livelihood dependence, and institutional responses influence the probability of social instability and violence. By modeling the interactions between environmental stress, socio-economic vulnerability, and governance capacity, the model provides a computational framework for examining potential pathways linking climate change and conflict in coastal social–ecological systems.
…
VIBE (Visible and Interconnected Behavioral Expectations Model)
Wenhan Feng | Published Friday, March 20, 2026This model aims to study the dynamic propagation of individual behaviour within social networks, focusing on how normative expectations (NE) and experiential expectations (EE) jointly influence behavioural decisions. It also explores the long-term effects of different intervention scenarios (such as enhancing visibility, considering indirect social links, and education) on behavioural propagation patterns and the overall behaviour of the group.
The model was developed in NetLogo 6.4. It generates simulated groups based on large-scale survey data, utilizing NetLogo’s CSV, Table, and Matrix extensions. The model also employs the NW extension to enable network analysis functionality.
The model is designed for research “Shaping social norms to promote individual response behavior in public crises: An agent-based modeling approach” in Journal of Cleaner Production, Volume 554, 8 April 2026, 148014
https://doi.org/10.1016/j.jclepro.2026.148014
Gender Dynamics at a Naturist Venue (infinite capacity)
James Junghanns | Published Tuesday, February 03, 2026Manipulate[
Module[{fDot, mDot, poly, roots, stableRoots, rStar, rIso,
endPointStar, endPointIso},(1. Define the System Dynamics)
fDot = phi1(f/m) - phi2(m/f);
mDot = mu1(f/m) - mu2(m/f);
(*2. Find the Equilibrium Ratio r=f/
…
Incentives for data sharing
Flaminio Squazzoni Federico Bianchi Thomas Klebel Tony Ross-Hellauer | Published Thursday, October 02, 2025Although beneficial to scientific development, data sharing is still uncommon in many research areas. Various organisations, including funding agencies that endorse open science, aim to increase its uptake. However, estimating the large-scale implications of different policy interventions on data sharing by funding agencies, especially in the context of intense competition among academics, is difficult empirically. Here, we built an agent-based model to simulate the effect of different funding schemes (i.e., highly competitive large grants vs. distributive small grants), and varying intensity of incentives for data sharing on the uptake of data sharing by academic teams strategically adapting to the context.
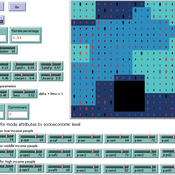
Peer reviewed Urban Transport Mode Choices
Kathleen Salazar -Serna Lorena Cadavid Carlos Franco | Published Thursday, May 22, 2025The model represents urban commuters’ transport mode choices among cars, public transit, and motorcycles—a mode highly prevalent in developing countries. Using an agent-based modeling approach, it simulates transport dynamics and serves as a testbed for evaluating policies aimed at improving mobility.
The model simulates an ecosystem of human agents who decide, at each time step, which mode of transportation to use for commuting to work. Their decision is based on a combination of personal satisfaction with their most recent journey—evaluated across a vector of individual needs—the information they crowdsource from their social network, and their personal uncertainty regarding trying new transport options.
Agents are assigned demographic attributes such as sex, age, and income level, and are distributed across city neighborhoods according to their socioeconomic status. To represent social influence in decision-making, agents are connected via a scale-free social network topology, where connections are more likely among agents within the same socioeconomic group, reflecting the tendency of individuals to form social ties with similar others.
…
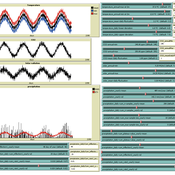
Peer reviewed The Indus Village's Weather model: procedural generation of daily weather
Andreas Angourakis | Published Tuesday, May 13, 2025Overview
The Weather model is a procedural generation model designed to create realistic daily weather data for socioecological simulations. It generates synthetic weather time series for solar radiation, temperature, and precipitation using algorithms based on sinusoidal and double logistic functions. The model incorporates stochastic variation to mimic unpredictable weather patterns and aims to provide realistic yet flexible weather inputs for exploring diverse climate scenarios.
The Weather model can be used independently or integrated into larger models, providing realistic weather patterns without extensive coding or data collection. It can be customized to meet specific requirements, enabling users to gain a better understanding of the underlying mechanisms and have greater confidence in their applications.
…
Protein 2.0: An Agent-Based Model for Simulating Norway’s Protein Sector Under Carbon Pricing and the Emergence of Cultivated Proteins
Gary Polhill Nick Roxburgh Rob J.F. Burton Klaus Mittenzwei | Published Thursday, May 08, 2025Protein 2.0 is a systems model of the Norwegian protein sector designed to explore the potential impacts of carbon taxation and the emergence of cultivated meat and dairy technologies. The model simulates production, pricing, and consumption dynamics across conventional and cultivated protein sources, accounting for emissions intensity, technological learning, economies of scale, and agent behaviour. It assesses how carbon pricing could alter the competitiveness of conventional beef, lamb, pork, chicken, milk, and egg production relative to emerging cultivated alternatives, and evaluates the implications for domestic production, emissions, and food system resilience. The model provides a flexible platform for exploring policy scenarios and transition pathways in protein supply. Further details can be found in the associated publication.
An agent-based model to simulate field-specific nitrogen fertilizer applications in grasslands
Maria Haensel Thomas Schmitt Andrea Kaim Sylvia Helena Annuth Thomas Koellner | Published Sunday, February 09, 2025Grasslands have a large share of the world’s land cover and their sustainable management is important for the protection and provisioning of grassland ecosystem services. The question of how to manage grassland sustainably is becoming increasingly important, especially in view of climate change, which on the one hand extends the vegetation period (and thus potentially allows use intensification) and on the other hand causes yield losses due to droughts. Fertilization plays an important role in grassland management and decisions are usually made at farm level. Data on fertilizer application rates are crucial for an accurate assessment of the effects of grassland management on ecosystem services. However, these are generally not available on farm/field scale. To close this gap, we present an agent-based model for Fertilization In Grasslands (FertIG). Based on animal, land-use, and cutting data, the model estimates grassland yields and calculates field-specific amounts of applied organic and mineral nitrogen on grassland (and partly cropland). Furthermore, the model considers different legal requirements (including fertilization ordinances) and nutrient trade among farms. FertIG was applied to a grassland-dominated region in Bavaria, Germany comparing the effects of changes in the fertilization ordinance as well as nutrient trade. The results show that the consideration of nutrient trade improves organic fertilizer distribution and leads to slightly lower Nmin applications. On a regional scale, recent legal changes (fertilization ordinance) had limited impacts. Limiting the maximum applicable amount of Norg to 170 kg N/ha fertilized area instead of farm area as of 2020 hardly changed fertilizer application rates. No longer considering application losses in the calculation of fertilizer requirements had the strongest effects, leading to lower supplementary Nmin applications. The model can be applied to other regions in Germany and, with respective adjustments, in Europe. Generally, it allows comparing the effects of policy changes on fertilization management at regional, farm and field scale.
Displaying 10 of 92 results scale clear search