Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 29 results person clear search
Peer reviewed AgModel
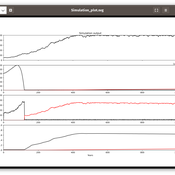
Isaac Ullah | Published Friday, December 06, 2024AgModel is an agent-based model of the forager-farmer transition. The model consists of a single software agent that, conceptually, can be thought of as a single hunter-gather community (i.e., a co-residential group that shares in subsistence activities and decision making). The agent has several characteristics, including a population of human foragers, intrinsic birth and death rates, an annual total energy need, and an available amount of foraging labor. The model assumes a central-place foraging strategy in a fixed territory for a two-resource economy: cereal grains and prey animals. The territory has a fixed number of patches, and a starting number of prey. While the model is not spatially explicit, it does assume some spatiality of resources by including search times.
Demographic and environmental components of the simulation occur and are updated at an annual temporal resolution, but foraging decisions are “event” based so that many such decisions will be made in each year. Thus, each new year, the foraging agent must undertake a series of optimal foraging decisions based on its current knowledge of the availability of cereals and prey animals. Other resources are not accounted for in the model directly, but can be assumed for by adjusting the total number of required annual energy intake that the foraging agent uses to calculate its cereal and prey animal foraging decisions. The agent proceeds to balance the net benefits of the chance of finding, processing, and consuming a prey animal, versus that of finding a cereal patch, and processing and consuming that cereal. These decisions continue until the annual kcal target is reached (balanced on the current human population). If the agent consumes all available resources in a given year, it may “starve”. Starvation will affect birth and death rates, as will foraging success, and so the population will increase or decrease according to a probabilistic function (perturbed by some stochasticity) and the agent’s foraging success or failure. The agent is also constrained by labor caps, set by the modeler at model initialization. If the agent expends its yearly budget of person-hours for hunting or foraging, then the agent can no longer do those activities that year, and it may starve.
Foragers choose to either expend their annual labor budget either hunting prey animals or harvesting cereal patches. If the agent chooses to harvest prey animals, they will expend energy searching for and processing prey animals. prey animals search times are density dependent, and the number of prey animals per encounter and handling times can be altered in the model parameterization (e.g. to increase the payoff per encounter). Prey animal populations are also subject to intrinsic birth and death rates with the addition of additional deaths caused by human predation. A small amount of prey animals may “migrate” into the territory each year. This prevents prey animals populations from complete decimation, but also may be used to model increased distances of logistic mobility (or, perhaps, even residential mobility within a larger territory).
…
GODS: Gossip-Oriented Dilemma Simulator
Jan Majewski | Published Wednesday, September 04, 2024 | Last modified Monday, September 29, 2025Model of influence of access to social information spread via social network on decisions in a two-person game.
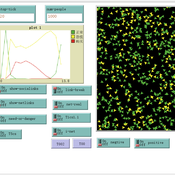
Simulation of Dual Information Exposure Networks: An Agent-Based Model of Panic Buying Behavior in China
dachenga | Published Thursday, April 11, 2024The main function of this simulation model is to simulate the onset of individual panic in the context of a public health event, and in particular to simulate how an individual’s panic develops and dies out in the context of a dual information contact network of online social media information and offline in-person perception information. In this model, eight different scenarios are set up by adjusting key parameters according to the difference in the amount and nature of information circulating in the dual information network, in order to observe how the agent’s panic behavior will change under different information exposure situations.
Peer reviewed Co-adoption of low-carbon household energy technologies
Mart van der Kam Maria Lagomarsino Elie Azar Ulf Hahnel David Parra | Published Tuesday, August 29, 2023 | Last modified Friday, February 23, 2024The model simulates the diffusion of four low-carbon energy technologies among households: photovoltaic (PV) solar panels, electric vehicles (EVs), heat pumps, and home batteries. We model household decision making as the decision marking of one person, the agent. The agent decides whether to adopt these technologies. Hereby, the model can be used to study co-adoption behaviour, thereby going beyond traditional diffusion models that focus on the adop-tion of single technologies. The combination of these technologies is of particular interest be-cause (1) using the energy generated by PV solar panels for EVs and heat pumps can reduce emissions associated with transport and heating, respectively, and (2) EVs, heat pumps, and home batteries can help to integrate PV solar panels in local electricity grids by offering flexible demand (EVs and heat pumps) and energy storage (home batteries and EVs), thereby reducing grid impacts and associated upgrading costs.
The purpose of the model is to represent realistic adoption and co-adoption behaviour. This is achieved by grounding the decision model on the risks-as-feelings model (Loewenstein et al., 2001), theory from environmental and social psychology, and empirically informing agent be-haviour by survey-data among 1469 people in the Swiss region Romandie.
The model can be used to construct scenarios for the diffusion of the four low-carbon energy technologies depending on different contexts, and as a virtual experimentation environment for ex ante evaluation of policy interventions to stimulate adoption and co-adoption.
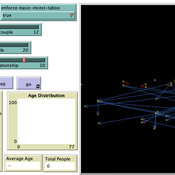
Peer reviewed Monogamous Reproduction in Small Populations and the Enforcement of the Incest Taboo
Ian Stuart | Published Wednesday, January 18, 2023This program was developed to simulate monogamous reproduction in small populations (and the enforcement of the incest taboo).
Every tick is a year. Adults can look for a mate and enter a relationship. Adult females in a Relationship (under the age of 52) have a chance to become pregnant. Everyone becomes not alive at 77 (at which point people are instead displayed as flowers).
User can select a starting-population. The starting population will be adults between the ages of 18 and 42.
…
DINO model - Dynamics of Internalization and Dissemination of Norms
Marlene Batzke | Published Wednesday, January 11, 2023 | Last modified Saturday, August 19, 2023The DINO model (Dynamics of Internalization and Dissemimnation of Norms) simulates a conceptual model on the dynamics of norm internalization in the decision-making framework of a 3-person prisoner’s dilemma game.
Peer reviewed Personnel decisions in the hierarchy
Smarzhevskiy Ivan | Published Friday, August 19, 2022This is a model of organizational behavior in the hierarchy in which personnel decisions are made.
The idea of the model is that the hierarchy, busy with operations, is described by such characteristics as structure (number and interrelation of positions) and material, filling these positions (persons with their individual performance). A particular hierarchy is under certain external pressure (performance level requirement) and is characterized by the internal state of the material (the distribution of the perceptions of others over the ensemble of persons).
The World of the model is a four-level hierarchical structure, consisting of shuff positions of the top manager (zero level of the hierarchy), first-level managers who are subordinate to the top manager, second-level managers (subordinate to the first-level managers) and positions of employees (the third level of the hierarchy). ) subordinated to the second-level managers. Such a hierarchy is a tree, i.e. each position, with the exception of the position of top manager, has a single boss.
Agents in the model are persons occupying the specified positions, the number of persons is set by the slider (HumansQty). Personas have some operational performance (harisma, an unfortunate attribute name left over from the first edition of the model)) and a sense of other personas’ own perceptions. Performance values are distributed over the ensemble of persons according to the normal law with some mean value and variance.
The value of perception by agents of each other is positive or negative (implemented in the model as numerical values equal to +1 and -1). The distribution of perceptions over an ensemble of persons is implemented as a random variable specified by the probability of negative perception, the value of which is set by the control elements of the model interface. The numerical value of the probability equal to 0 corresponds to the case in which all persons positively perceive each other (the numerical value of the random variable is equal to 1, which corresponds to the positive perception of the other person by the individual).
The hierarchy is occupied with operational activity, the degree of intensity of which is set by the external parameter Difficulty. The level of productivity of each manager OAIndex is equal to the level of productivity of the department he leads and is the ratio of the sum of productivity of employees subordinate to the head to the level of complexity of the work Difficulty. An increase in the numerical value of Difficulty leads to a decrease in the OAIndex for all subdivisions of the hierarchy. The managerial meaning of the OAIndex indicator is the percentage of completion of the load specified for the hierarchy as a whole, i.e. the ratio of the actual performance of the structural subdivisions of the hierarchy to the required performance, the level of which is specified by the value of the Difficulty parameter.
…
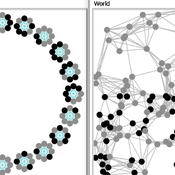
Two agent-based models of cooperation in dynamic groups and fixed social networks
Carlos A. de Matos Fernandes | Published Thursday, January 20, 2022Both models simulate n-person prisoner dilemma in groups (left figure) where agents decide to C/D – using a stochastic threshold algorithm with reinforcement learning components. We model fixed (single group ABM) and dynamic groups (bad-barrels ABM). The purpose of the bad-barrels model is to assess the impact of information during meritocratic matching. In the bad-barrels model, we incorporated a multidimensional structure in which agents are also embedded in a social network (2-person PD). We modeled a random and homophilous network via a random spatial graph algorithm (right figure).
An ABM of historic British milk consumption
Matthew Gibson | Published Monday, December 20, 2021Substitution of food products will be key to realising widespread adoption of sustainable diets. We present an agent-based model of decision-making and influences on food choice, and apply it to historically observed trends of British whole and skimmed (including semi) milk consumption from 1974 to 2005. We aim to give a plausible representation of milk choice substitution, and test different mechanisms of choice consideration. Agents are consumers that perceive information regarding the two milk choices, and hold values that inform their position on the health and environmental impact of those choices. Habit, social influence and post-decision evaluation are modelled. Representative survey data on human values and long-running public concerns empirically inform the model. An experiment was run to compare two model variants by how they perform in reproducing these trends. This was measured by recording mean weekly milk consumption per person. The variants differed in how agents became disposed to consider alternative milk choices. One followed a threshold approach, the other was probability based. All other model aspects remained unchanged. An optimisation exercise via an evolutionary algorithm was used to calibrate the model variants independently to observed data. Following calibration, uncertainty and global variance-based temporal sensitivity analysis were conducted. Both model variants were able to reproduce the general pattern of historical milk consumption, however, the probability-based approach gave a closer fit to the observed data, but over a wider range of uncertainty. This responds to, and further highlights, the need for research that looks at, and compares, different models of human decision-making in agent-based and simulation models. This study is the first to present an agent-based modelling of food choice substitution in the context of British milk consumption. It can serve as a valuable pre-curser to the modelling of dietary shift and sustainable product substitution to plant-based alternatives in Britain.

Simulating Components of the Reinforcing Spirals Model and Spiral of Silence
František Kalvas Michael D. Slater Ashley Sanders-Jackson | Published Friday, November 05, 2021Communication processes occur in complex dynamic systems impacted by person attitudes and beliefs, environmental affordances, interpersonal interactions and other variables that all change over time. Many of the current approaches utilized by Communication researchers are unable to consider the full complexity of communication systems or the over time nature of our data. We apply agent-based modeling to the Reinforcing Spirals Model and the Spiral of Silence to better elucidate the complex and dynamic nature of this process. Our preliminary results illustrate how environmental affordances (i.e. social media), closeness of the system and probability of outspokenness may impact how attitudes change over time. Additional analyses are also proposed.
Displaying 10 of 29 results person clear search