Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 242 results for "Armin Haas" clear search
Correlated random walk (Javascript)
Viktoriia Radchuk Uta Berger Thibault Fronville | Published Tuesday, May 09, 2023The first simple movement models used unbiased and uncorrelated random walks (RW). In such models of movement, the direction of the movement is totally independent of the previous movement direction. In other words, at each time step the direction, in which an individual is moving is completely random. This process is referred to as a Brownian motion.
On the other hand, in correlated random walks (CRW) the choice of the movement directions depends on the direction of the previous movement. At each time step, the movement direction has a tendency to point in the same direction as the previous one. This movement model fits well observational movement data for many animal species.
The presented agent based model simulated the movement of the agents as a correlated random walk (CRW). The turning angle at each time step follows the Von Mises distribution with a ϰ of 10. The closer ϰ gets to zero, the closer the Von Mises distribution becomes uniform. The larger ϰ gets, the more the Von Mises distribution approaches a normal distribution concentrated around the mean (0°).
In this script the turning angles (following the Von Mises distribution) are generated based on the the instructions from N. I. Fisher 2011.
This model is implemented in Javascript and can be used as a building block for more complex agent based models that would rely on describing the movement of individuals with CRW.
Exploring the Potential of Conversational AI Support for Agent-Based Social Simulation Model Design
Peer-Olaf Siebers | Published Sunday, May 12, 2024Our aim is to demonstrate how conversational AI systems, exemplified by ChatGPT, can support the conceptualisation of Agent-Based Social Simulation (ABSS) models, leading to a full ABSS model design document. Through advanced prompt engineering and adherence to the Engineering ABSS framework (Siebers and Klügl 2017), we have constructed a comprehensive script that is easy to use and that supports the design of ABSS models with or even by AI. The performance of the script is demonstrated through an illustrative case study related to the use of adaptive architecture in museums. The repository contains (1) the comprehensive script in a format that allows copying and pasting prompts for use with ChatGPT, (2) the results of the illustrative case study in the form of two conceptual ABSS models, the ground truth and the autogenerated version.

WealthDistribRes
Romulus-Catalin Damaceanu | Published Friday, May 04, 2012 | Last modified Saturday, April 27, 2013This model WealthDistribRes can be used to study the distribution of wealth in function of using a combination of resources classified in two renewable and nonrenewable.
Informal Information Transmission Networks among Medieval Genoese Investors
Christopher Frantz | Published Wednesday, October 09, 2013 | Last modified Thursday, October 24, 2013This model represents informal information transmission networks among medieval Genoese investors used to inform each other about cheating merchants they employed as part of long-distance trade operations.

Peer Review with Multiple Reviewers
Flaminio Squazzoni Federico Bianchi | Published Thursday, September 10, 2015This ABM looks at the effect of multiple reviewers and their behavior on the quality and efficiency of peer review. It models a community of scientists who alternatively act as “author” or “reviewer” at each turn.
Agent-based model for the socio-economic monitoring of visitor streams
Stefan Mohr | Published Saturday, January 20, 2018Due to the large extent of the Harz National Park, an accurate measurement of visitor numbers and their spatiotemporal distribution is not feasible. This model demonstrates the possibility to simulate the streams of visitors with ABM methodology.
Peer reviewed Casting: A Bio-Inspired Method for Restructuring Machine Learning Ensembles
Colin Lynch Bryan Daniels | Published Thursday, September 18, 2025The wisdom of the crowd refers to the phenomenon in which a group of individuals, each making independent decisions, can collectively arrive at highly accurate solutions—often more accurate than any individual within the group. This principle relies heavily on independence: if individual opinions are unbiased and uncorrelated, their errors tend to cancel out when averaged, reducing overall bias. However, in real-world social networks, individuals are often influenced by their neighbors, introducing correlations between decisions. Such social influence can amplify biases, disrupting the benefits of independent voting. This trade-off between independence and interdependence has striking parallels to ensemble learning methods in machine learning. Bagging (bootstrap aggregating) improves classification performance by combining independently trained weak learners, reducing bias. Boosting, on the other hand, explicitly introduces sequential dependence among learners, where each learner focuses on correcting the errors of its predecessors. This process can reinforce biases present in the data even if it reduces variance. Here, we introduce a new meta-algorithm, casting, which captures this biological and computational trade-off. Casting forms partially connected groups (“castes”) of weak learners that are internally linked through boosting, while the castes themselves remain independent and are aggregated using bagging. This creates a continuum between full independence (i.e., bagging) and full dependence (i.e., boosting). This method allows for the testing of model capabilities across values of the hyperparameter which controls connectedness. We specifically investigate classification tasks, but the method can be used for regression tasks as well. Ultimately, casting can provide insights for how real systems contend with classification problems.
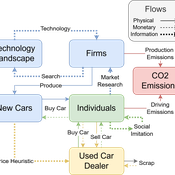
Driving in the wrong direction? A co-evolutionary model of electric vehicle adoption and innovation
Daniel Torren-Peraire | Published Friday, July 11, 2025Car-centric societies face substantial challenges in moving towards sustainable
mobility systems, with internal combustion engine vehicles remaining a major
source of emissions. Electric vehicles play a critical role in addressing this challenge, yet their diffusion depends on the interaction of consumer behaviour, firm
innovation, and policy incentives. This paper develops an agent-based model to
examine these dynamics, calibrated on the data for the state of California over
2001-2023. In the model, heterogeneous car users influenced by their social peers
…
Bargaining with misvaluation
Marcin Czupryna | Published Wednesday, January 14, 2026Subjective biases and errors systematically affect market equilibria, whether at the population level or in bilateral trading. Here, we consider the possibility that an agent engaged in bilateral trading is mistaken about her own valuation of the good she expects to trade, that has not been explicitly incorporated into the existing bilateral trade literature. Although it may sound paradoxical that a subjective private valuation is something an agent can be mistaken about, as it is up to her to fix it, we consider the case in which that agent, seller or buyer, consciously or not, given the structure of a market, a type of good, and a temporary lack of information, may arrive at an erroneous valuation. The typical context through which this possibility may arise is in relation with so-called experience goods, which are sold while all their intrinsic qualities are still unknown (such as untasted bottled fine wines). We model this “private misvaluation” phenomenon in our study. The agents may also be mistaken about how their exchange counterparties are themselves mistaken. Formally, they attribute a certain margin of error to the other agent, which can differ from the actual way that another agent misvalues the good under consideration. This can constitute the source of a second-order misvaluation. We model different attitudes and situations in which agents face unexpected signals from their counterparties and the manner and extent to which they revise their initial beliefs. We analyse and simulate numerically the consequences of first-order and second-order misvaluation on market equilibria.
Peer reviewed Green Consumption Tipping Point
Mario | Published Thursday, February 26, 2026This model is a minimal agent-based model (ABM) of green consumption and market tipping dynamics in a stylised two-firm economy. It is designed as an existence proof to illustrate how weak individual preferences, when combined with habit formation, social influence, and firm price adaptation, can generate non-linear transitions (tipping points) in market outcomes.
The economy consists of:
1) Two firms, each supplying a differentiated consumption bundle that differs in its fixed green share (one relatively greener, one less green).
2) Many households, each consuming a unit mass per period and allocating consumption between the two firms.
…
Displaying 10 of 242 results for "Armin Haas" clear search