Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 87 results for "Isaque Daniel Rocha Eberhardt" clear search
Tyche
Tony Lawson | Published Tuesday, February 28, 2012 | Last modified Saturday, April 27, 2013Demographic microsimulation model used in speed tests against LIAM 2.
The Effectiveness of Image-Scoring Under Different Ecological Conditions
G M Leighton | Published Monday, January 06, 2014The set of models test how receivers ability to accurately rank signalers under various ecological and behavioral contexts.
Exploring Urban Shrinkage
Andrew Crooks | Published Thursday, March 19, 2020While the world’s total urban population continues to grow, this growth is not equal. Some cities are declining, resulting in urban shrinkage which is now a global phenomenon. Many problems emerge due to urban shrinkage including population loss, economic depression, vacant properties and the contraction of housing markets. To explore this issue, this paper presents an agent-based model stylized on spatially explicit data of Detroit Tri-county area, an area witnessing urban shrinkage. Specifically, the model examines how micro-level housing trades impact urban shrinkage by capturing interactions between sellers and buyers within different sub-housing markets. The stylized model results highlight not only how we can simulate housing transactions but the aggregate market conditions relating to urban shrinkage (i.e., the contraction of housing markets). To this end, the paper demonstrates the potential of simulation to explore urban shrinkage and potentially offers a means to test polices to alleviate this issue.
Peer reviewed The effect of homophily on co-offending outcomes
Ruslan Klymentiev Christophe Vandeviver Luis E. C. Rocha | Published Friday, September 26, 2025This Agent-Based Model is designed to simulate how similarity-based partner selection (homophily) shapes the formation of co-offending networks and the diffusion of skills within those networks. Its purpose is to isolate and test the effects of offenders’ preference for similar partners on network structure and information flow, under controlled conditions.
In the model, offenders are represented as agents with an individual attribute and a set of skills. At each time step, agents attempt to select partners based on similarity preference. When two agents mutually select each other, they commit a co-offense, forming a tie and exchanging a skill. The model tracks the evolution of network properties (e.g., density, clustering, and tie strength) as well as the spread of skills over time.
This simple and theoretical model does not aim to produce precise empirical predictions but rather to generate insights and test hypotheses about the trade-off between partnership stability and information diffusion. It provides a flexible framework for exploring how changes in partner selection preferences may lead to differences in criminal network dynamics. Although the model was developed to simulate offenders’ interactions, in principle, it could be applied to other social processes involving social learning and skills exchange.
…
Peer reviewed An extended replication of Abelson's and Bernstein's community referendum simulation
Klaus G. Troitzsch | Published Friday, October 25, 2019 | Last modified Friday, August 25, 2023This is an extended replication of Abelson’s and Bernstein’s early computer simulation model of community referendum controversies which was originally published in 1963 and often cited, but seldom analysed in detail. This replication is in NetLogo 6.3.0, accompanied with an ODD+D protocol and class and sequence diagrams.
This replication replaces the original scales for attitude position and interest in the referendum issue which were distributed between 0 and 1 with values that are initialised according to a normal distribution with mean 0 and variance 1 to make simulation results easier compatible with scales derived from empirical data collected in surveys such as the European Value Study which often are derived via factor analysis or principal component analysis from the answers to sets of questions.
Another difference is that this model is not only run for Abelson’s and Bernstein’s ten week referendum campaign but for an arbitrary time in order that one can find out whether the distributions of attitude position and interest in the (still one-dimensional) issue stabilise in the long run.
Opinions on contested energy infrastructures
Annalisa Stefanelli | Published Thursday, June 23, 2016This ABM simulates opinions on a topic (originally contested infrastructures) through the interactions between paired agents and based on the sociopsychological assumptions of social judgment theory (SJT; Sherif & Hovland, 1961).
SiFlo: An Agent-based Model to simulate inhabitants’ behavior during a flood event
Patrick Taillandier Franck Taillandier Pascal Di Maiolo Rasool Mehdizadeh | Published Thursday, July 29, 2021SiFlo is an ABM dedicated to simulate flood events in urban areas. It considers the water flowing and the reaction of the inhabitants. The inhabitants would be able to perform different actions regarding the flood: protection (protect their house, their equipment and furniture…), evacuation (considering traffic model), get and give information (considering imperfect knowledge), etc. A special care was taken to model the inhabitant behavior: the inhabitants should be able to build complex reasoning, to have emotions, to follow or not instructions, to have incomplete knowledge about the flood, to interfere with other inhabitants, to find their way on the road network. The model integrates the closure of roads and the danger a flooded road can represent. Furthermore, it considers the state of the infrastructures and notably protection infrastructures as dyke. Then, it allows to simulate a dyke breaking.
The model intends to be generic and flexible whereas provide a fine geographic description of the case study. In this perspective, the model is able to directly import GIS data to reproduce any territory. The following sections expose the main elements of the model.
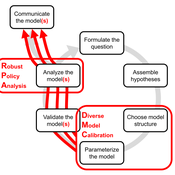
DMC-RPA: Diverse Model Calibration for Robust Policy Analysis (applied to an ABM of smallholder farmer resilience)
Tim Williams | Published Sunday, August 30, 2020This repository contains: (1) a model calibration procedure that identifies a set of diverse, plausible models; and (2) an ABM of smallholder agriculture, which is used as a case study application for the calibration method. By identifying a set of diverse models, the calibration method attends to the issue of “equifinality” prevalent in complex systems, which is a situation where multiple plausible process descriptions exist for a single outcome.
An Agent-Based Model of Corruption: Micro Approach
Valery Dzutsati | Published Friday, January 30, 2015 | Last modified Sunday, September 27, 2015Endogenous social transition from a high-corruption state to a low-corruption state, replication of Hammond 2009
Multi-agent modeling and analysis of the knowledge learning of a human-machine hybrid intelligent organization with human-machine trust
Haoxiang Zhang | Published Monday, April 24, 2023Machine learning technologies have changed the paradigm of knowledge discovery in organizations and transformed traditional organizational learning to human-machine hybrid intelligent organizational learning. However, it remains unclear how human-machine trust, which is an important factor that influences human-machine knowledge exchange, affects the effectiveness of human-machine hybrid intelligent organizational learning. To explore this issue, we used multi-agent simulation to construct a knowledge learning model of a human-machine hybrid intelligent organization with human-machine trust.
Displaying 10 of 87 results for "Isaque Daniel Rocha Eberhardt" clear search