Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 213 results network clear search
Knowledge Sharing in a Hospital
bpint Emily Molfino Joshua Goldstein Kathryn Schaefer Ziemer Mark Orr Bryan Lewis Jose Jimenez | Published Friday, January 27, 2023Organizations are complex systems comprised of many dynamic and evolving interaction patterns among individuals and groups. Understanding these interactions and how patterns, such as informal structures and knowledge sharing behavior, emerge are crucial to creating effective and efficient organizations. To explore such organizational dynamics, the agent-based model integrates a cognitive model, dynamic social networks, and a physical environment.
Peer reviewed TRANSOPE: a multi-agent model to simulate outsourcing networks in road freight transport.
Aitor Salas-Peña Blanca Rosa Cases Gutiérrez | Published Friday, October 21, 2022A road freight transport (RFT) operation involves the participation of several types of companies in its execution. The TRANSOPE model simulates the subcontracting process between 3 types of companies: Freight Forwarders (FF), Transport Companies (TC) and self-employed carriers (CA). These companies (agents) form transport outsourcing chains (TOCs) by making decisions based on supplier selection criteria and transaction acceptance criteria. Through their participation in TOCs, companies are able to learn and exchange information, so that knowledge becomes another important factor in new collaborations. The model can replicate multiple subcontracting situations at a local and regional geographic level.
The succession of n operations over d days provides two types of results: 1) Social Complex Networks, and 2) Spatial knowledge accumulation environments. The combination of these results is used to identify the emergence of new logistics clusters. The types of actors involved as well as the variables and parameters used have their justification in a survey of transport experts and in the existing literature on the subject.
As a result of a preferential selection process, the distribution of activity among agents shows to be highly uneven. The cumulative network resulting from the self-organisation of the system suggests a structure similar to scale-free networks (Albert & Barabási, 2001). In this sense, new agents join the network according to the needs of the market. Similarly, the network of preferential relationships persists over time. Here, knowledge transfer plays a key role in the assignment of central connector roles, whose participation in the outsourcing network is even more decisive in situations of scarcity of transport contracts.
Agent-based simulation of discussion processes in risk workshops with quantitative skepticism
Matthias Meyer Clemens Harten Lucia Bellora-Bienengräber | Published Sunday, August 14, 2022The model measures drivers of effectiveness of risk assessments in risk workshops where a calculative culture of quantitative skepticism is present. We model the limits to information transfer, incomplete discussions, group characteristics, and interaction patterns and investigate their effect on risk assessment in risk workshops, in order to contrast results to a previous model focused on a calculative culture of quantitative enthusiasm.
The model simulates a discussion in the context of a risk workshop with 9 participants. The participants use constraint satisfaction networks to assess a given risk individually and as a group.
Cellular automata model of social networks
Rubens de Almeida Zimbres | Published Tuesday, August 02, 2022This project was developed during the Santa Fe course Introduction to Agent-Based Modeling 2022. The origin is a Cellular Automata (CA) model to simulate human interactions that happen in the real world, from Rubens and Oliveira (2009). These authors used a market research with real people in two different times: one at time zero and the second at time zero plus 4 months (longitudinal market research). They developed an agent-based model whose initial condition was inherited from the results of the first market research response values and evolve it to simulate human interactions with Agent-Based Modeling that led to the values of the second market research, without explicitly imposing rules. Then, compared results of the model with the second market research. The model reached 73.80% accuracy.
In the same way, this project is an Exploratory ABM project that models individuals in a closed society whose behavior depends upon the result of interaction with two neighbors within a radius of interaction, one on the relative “right” and other one on the relative “left”. According to the states (colors) of neighbors, a given cellular automata rule is applied, according to the value set in Chooser. Five states were used here and are defined as levels of quality perception, where red (states 0 and 1) means unhappy, state 3 is neutral and green (states 3 and 4) means happy.
There is also a message passing algorithm in the social network, to analyze the flow and spread of information among nodes. Both the cellular automaton and the message passing algorithms were developed using the Python extension. The model also uses extensions csv and arduino.
DroneStrikes_TerroristAttacks
B Shapiro | Published Friday, July 15, 2022ABM focused on examining the dissemination of opinions through a notional terrorist network to generate terrorist attacks caused by drone strikes.
JLootBox: An Agent-Based Model of Social Influence and Gambling in Online Video Games
Lila Zayed | Published Friday, May 06, 2022This model aims to explore how gambling-like behavior can emerge in loot box spending within gaming communities. A loot box is a purchasable mystery box that randomly awards the player a series of in-game items. Since the contents of the box are largely up to chance, many players can fall into a compulsion loop of purchasing, as the fear of missing out and belief in the gambler’s fallacy allow one to rationalize repeated purchases, especially when one compares their own luck to others. To simulate this behavior, this model generates players in different network structures to observe how factors such as network connectivity, a player’s internal decision making strategy, or even common manipulations games use these days may influence a player’s transactions.
The Levers of HIV Model
Arthur Hjorth Wouter Vermeer C. Hendricks Brown Uri Wilensky Can Gurkan | Published Tuesday, March 08, 2022 | Last modified Tuesday, October 31, 2023Chicago’s demographic, neighborhood, sex risk behaviors, sexual network data, and HIV prevention and treatment cascade information from 2015 were integrated as input to a new agent-based model (ABM) called the Levers-of-HIV-Model (LHM). This LHM, written in NetLogo, forms patterns of sexual relations among Men who have Sex with Men (MSM) based on static traits (race/ethnicity, and age) and dynamic states (sexual relations and practices) that are found in Chicago. LHM’s five modules simulate and count new infections at the two marker years of 2023 and 2030 for a wide range of distinct scenarios or levers, in which the levels of PrEP and ART linkage to care, retention, and adherence or viral load are increased over time from the 2015 baseline levels.
An Agent-Based Model of Insurance Customer Behaviour with Word of Mouth Network in C#
Rei England Iqbal Owadally Douglas Wright | Published Friday, March 04, 2022This is an agent-based model with two types of agents: customers and insurers. Insurers are price-takers who choose how much to spend on their service quality, and customers evaluate insurers based on premium, brand preference, and their perceived service quality. Customers are also connected in a small-world network and may share their opinions with their network.
The ABM contains two types of agents: insurers and customers. These act within the environment of a motor insurance market. At each simulation, the model undergoes the following steps:
- Network generation: At the start of the simulation, the model generates a small world network of social links between the customers, and randomly assigns each customer to an initial insurer ...
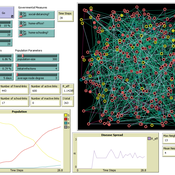
The Effect of Different Governmental Pandemic Control Measures on the Spread of a Virus Disease
Chiara Letter | Published Wednesday, January 26, 2022In this model, the spread of a virus disease in a network consisting of school pupils, employed, and umemployed people is simulated. The special feature in this model is the distinction between different types of links: family-, friends-, school-, or work-links. In this way, different governmental measures can be implemented in order to decelerate or stop the transmission.
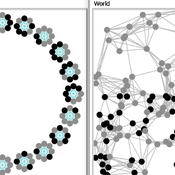
Two agent-based models of cooperation in dynamic groups and fixed social networks
Carlos A. de Matos Fernandes | Published Thursday, January 20, 2022Both models simulate n-person prisoner dilemma in groups (left figure) where agents decide to C/D – using a stochastic threshold algorithm with reinforcement learning components. We model fixed (single group ABM) and dynamic groups (bad-barrels ABM). The purpose of the bad-barrels model is to assess the impact of information during meritocratic matching. In the bad-barrels model, we incorporated a multidimensional structure in which agents are also embedded in a social network (2-person PD). We modeled a random and homophilous network via a random spatial graph algorithm (right figure).
Displaying 10 of 213 results network clear search