About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 110 results random clear search
MERCURY extension: population
Tom Brughmans | Published Thursday, May 23, 2019This model is an extended version of the original MERCURY model (https://www.comses.net/codebases/4347/releases/1.1.0/ ) . It allows for experiments to be performed in which empirically informed population sizes of sites are included, that allow for the scaling of the number of tableware traders with the population of settlements, and for hypothesised production centres of four tablewares to be used in experiments.
Experiments performed with this population extension and substantive interpretations derived from them are published in:
Hanson, J.W. & T. Brughmans. In press. Settlement scale and economic networks in the Roman Empire, in T. Brughmans & A.I. Wilson (ed.) Simulating Roman Economies. Theories, Methods and Computational Models. Oxford: Oxford University Press.
…
GRASP world
Gert Jan Hofstede | Published Tuesday, April 16, 2019This agent-based model investigates group longevity in a population in a foundational way, using theory on social relations and culture. It is the first application of the GRASP meta-model for social agents, containing elements of Groups, Rituals, Affiliation, Status, and Power. It can be considered an exercise in artificial sociality: a culture-general, content-free base-line trust model from which to engage in more specific studies. Depending on cultural settings for individualism and power distance, as well as settings for xenophobia and for the increase of trust over group life, the GRASP world model generates a variety of patters. Number of groups ranges from one to many, composition from random to segregated, and pattern genesis from rapid to many hundreds of time steps. This makes GRASP world an instrument that plausibly models some basic elements of social structure in different societies.
Peer reviewed Collectivities
Nigel Gilbert | Published Tuesday, April 09, 2019 | Last modified Thursday, August 22, 2019The model that simulates the dynamic creation and maintenance of knowledge-based formations such as communities of scientists, fashion movements, and subcultures. The model’s environment is a spatial one, representing not geographical space, but a “knowledge space” in which each point is a different collection of knowledge elements. Agents moving through this space represent people’s differing and changing knowledge and beliefs. The agents have only very simple behaviors: If they are “lonely,” that is, far from a local concentration of agents, they move toward the crowd; if they are crowded, they move away.
Running the model shows that the initial uniform random distribution of agents separates into “clumps,” in which some agents are central and others are distributed around them. The central agents are crowded, and so move. In doing so, they shift the centroid of the clump slightly and may make other agents either crowded or lonely, and they too will move. Thus, the clump of agents, although remaining together for long durations (as measured in time steps), drifts across the view. Lonely agents move toward the clump, sometimes joining it and sometimes continuing to trail behind it. The clumps never merge.
The model is written in NetLogo (v6). It is used as a demonstration of agent-based modelling in Gilbert, N. (2008) Agent-Based Models (Quantitative Applications in the Social Sciences). Sage Publications, Inc. and described in detail in Gilbert, N. (2007) “A generic model of collectivities,” Cybernetics and Systems. European Meeting on Cybernetic Science and Systems Research, 38(7), pp. 695–706.
Peer reviewed Applying Brantingham’s Neutral Model of Stone Raw Material Procurement to the Pinnacle Point Middle Stone Age Record, Western Cape, South Africa
Marco Janssen Simen Oestmo Haley Cawthra | Published Sunday, March 10, 2019This model is an application of Brantingham’s neutral model to a real landscape with real locations of potential sources. The sources are represented as their sizes during current conditions, and from marine geophysics surveys, and the agent starts at a random location in Mossel Bay Region (MBR) surrounding the Archaeological Pinnacle Point (PP) locality, Western Cape, South Africa. The agent moves at random on the landscape, picks up and discards raw materials based only upon space in toolkit and probability of discard. If the agent happens to encounter the PP locality while moving at random the agent may discard raw materials at it based on the discard probability.
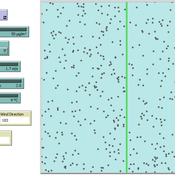
Absorption of particulate matter by leafs
Georg Jäger Chiara Letter | Published Monday, November 12, 2018 | Last modified Monday, November 12, 2018This model aims to understand the interaction between particulate matter and leaves of trees. The particles collide with the leaf and can either be absorbed with a certain probability, otherwise they bounce off it. The absorptions are detected in a counter.
The movement of the particles depends mainly on the strength and direction of the wind and the air temperature. They also show a certain random movement, but the proportion is negligible.
In a collision with the leaf, the particles are absorbed with a certain probability (absorption-probability), otherwise repelled.
An agent-based simulation model simulating the problem solving process of tournament-based crowdsourcing
wiseyanjie | Published Friday, July 06, 2018A series of studies show the applicability of the NK model in the crowdsourcing research, but it also exposes a problem that the application of the NK model is not tightly integrated with crowdsourcing process, which leads to lack of a basic crowdsourcing simulation model. Accordingly, by introducing interaction relationship among task decisions to define three tasks of different structure: local task, small-world task and random task, and introducing bounded rationality and its two dimensions are taken into account: bounded rationality level that used to distinguish industry types and bounded rationality bias that used to differentiate professional users and ordinary users, an agent-based model that simulates the problem-solving process of tournament-based crowdsourcing is constructed by combining the NK fitness landscapes and the crowdsourcing framework of “Task-Crowd-Process-Evaluation”.
Endogenous changes in public opinion dynamics
Francisco J. León-Medina | Published Tuesday, June 05, 2018The model formalizes a situation where agents embedded in different types of networks (random, small world and scale free networks) interact with their neighbors and express an opinion that is the result of different mechanisms: a coherence mechanism, in which agents try to stick to their previously expressed opinions; an assessment mechanism, in which agents consider available external information on the topic; and a social influence mechanism, in which agents tend to approach their neighbor’s opinions.
An agent-based simulation model simulating the problem solving process of tournament-based crowdsourcing
wiseyanjie | Published Friday, May 04, 2018 | Last modified Friday, July 06, 2018A series of studies show the applicability of the NK model in the crowdsourcing research, but it also exposes a problem that the application of the NK model is not tightly integrated with crowdsourcing process, which leads to lack of a basic crowdsourcing simulation model. Accordingly, by introducing interaction relationship among task decisions to define three tasks of different structure: local task, small-world task and random task, and introducing bounded rationality and its two dimensions are taken into account: bounded rationality level that used to distinguish industry types and bounded rationality bias that used to differentiate professional users and ordinary users, an agent-based model that simulates the problem-solving process of tournament-based crowdsourcing is constructed by combining the NK fitness landscapes and the crowdsourcing framework of “Task-Crowd-Process-Evaluation”.
Machine Learning simulates Agent-based Model
Bernardo Furtado | Published Wednesday, March 07, 2018This is an initial exploratory exercise done for the class @ http://thiagomarzagao.com/teaching/ipea/ Text available here: https://arxiv.org/abs/1712.04429v1
The program:
Reads output from an ABM model and its parameters’ configuration
Creates a socioeconomic optimal output based on two ABM results of the modelers choice
Organizes the data as X and Y matrices
Trains some Machine Learning algorithms
…

cluster analysis
Lars Spång | Published Tuesday, November 07, 2017This model demonstrates how to illustrate a cluster pattern by counting turtles within i moving circle with a specified radius. The procedure is common in archaeological spatial analysis.
Displaying 10 of 110 results random clear search