About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 3 of 3 results status-power theory clear search
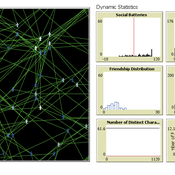
The Friendship Field
Eva Timmer Chrisja van de Kieft | Published Thursday, May 26, 2022 | Last modified Tuesday, August 30, 2022The Friendship Field model aims at modelling friendship formation based on three factors: Extraversion, Resemblance and Status, where social interaction is motivated by the Social Battery. Social Battery is one’s energy and motivation to engage in social contact. Since social contact is crucial for friendship formation, the model included Social Battery to affect social interactions. To our best knowledge, Social Battery is a yet unintroduced concept in research while it is a dynamic factor influencing the social interaction besides one’s characteristics. Extraverts’ Social Batteries charge while interacting and exhaust while being alone. Introverts’ Social Batteries charge while being alone and exhaust while interacting. The aim of the model is to illustrate the concept of Social Battery. Moreover, the Friendship Field shows patterns regarding Extraversion, Resemblance and Status including the mere-exposure effect and friendship by similarity. For the implementation of Status, Kemper’s status-power theory is used. The concept of Social Battery is also linked to Kemper’s theory on the organism as reference group. By running the model for a year (3 interactions moments per day), the friendship dynamics over time can be studied.
We presented the model at the Social Simulation Conference 2022.
GRASP world
Gert Jan Hofstede | Published Tuesday, April 16, 2019This agent-based model investigates group longevity in a population in a foundational way, using theory on social relations and culture. It is the first application of the GRASP meta-model for social agents, containing elements of Groups, Rituals, Affiliation, Status, and Power. It can be considered an exercise in artificial sociality: a culture-general, content-free base-line trust model from which to engage in more specific studies. Depending on cultural settings for individualism and power distance, as well as settings for xenophobia and for the increase of trust over group life, the GRASP world model generates a variety of patters. Number of groups ranges from one to many, composition from random to segregated, and pattern genesis from rapid to many hundreds of time steps. This makes GRASP world an instrument that plausibly models some basic elements of social structure in different societies.
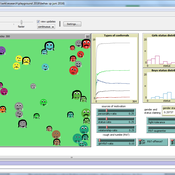
THE STATUS ARENA
Gert Jan Hofstede Jillian Student Mark R Kramer | Published Wednesday, June 08, 2016 | Last modified Tuesday, January 09, 2018Status-power dynamics on a playground, resulting in a status landscape with a gender status gap. Causal: individual (beauty, kindness, power), binary (rough-and-tumble; has-been-nice) or prior popularity (status). Cultural: acceptability of fighting.