About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 12 results natural selection clear search

Blending vs particulate inheritance - demo of Fisher (1930)
Paul Smaldino | Published Friday, September 13, 2024A simple model illustrating RA Fisher’s (1930) reconciliation of Darwinian selection with particulate genetic contributions.
00b SimEvo_V5.08 NetLogo
Garvin Boyle | Published Saturday, October 05, 2019In 1985 Dr Michael Palmiter, a high school teacher, first built a very innovative agent-based model called “Simulated Evolution” which he used for teaching the dynamics of evolution. In his model, students can see the visual effects of evolution as it proceeds right in front of their eyes. Using his schema, small linear changes in the agent’s genotype have an exponential effect on the agent’s phenotype. Natural selection therefore happens quickly and effectively. I have used his approach to managing the evolution of competing agents in a variety of models that I have used to study the fundamental dynamics of sustainable economic systems. For example, here is a brief list of some of my models that use “Palmiter Genes”:
- ModEco - Palmiter genes are used to encode negotiation strategies for setting prices;
- PSoup - Palmiter genes are used to control both motion and metabolic evolution;
- TpLab - Palmiter genes are used to study the evolution of belief systems;
- EffLab - Palmiter genes are used to study Jevon’s Paradox, EROI and other things.
…

Opportunity cost of walking away in the spatial iterated prisoner's dilemma
Luke Premo | Published Wednesday, April 03, 2019Previous work with the spatial iterated prisoner’s dilemma has shown that “walk away” cooperators are able to outcompete defectors as well as cooperators that do not respond to defection, but it remains to be seen just how robust the so-called walk away strategy is to ecologically important variables such as population density, error, and offspring dispersal. Our simulation experiments identify socio-ecological conditions in which natural selection favors strategies that emphasize forgiveness over flight in the spatial iterated prisoner’s dilemma. Our interesting results are best explained by considering how population density, error, and offspring dispersal affect the opportunity cost associated with walking away from an error-prone partner.
Peer reviewed Population Genetics
Kristin Crouse | Published Thursday, February 08, 2018 | Last modified Wednesday, September 09, 2020This model simulates the mechanisms of evolution, or how allele frequencies change in a population over time.
Peer reviewed Dawkins Weasel
Kristin Crouse | Published Thursday, February 08, 2018 | Last modified Tuesday, February 04, 2020Dawkins’ Weasel is a NetLogo model that illustrates the principle of evolution by natural selection. It is inspired by a thought experiment presented by Richard Dawkins in his book The Blind Watchmaker (1996).
04 TpLab V2.08 – Teleological Pruning Laboratory
Garvin Boyle | Published Saturday, April 15, 2017Our societal belief systems are pruned by evolution, informing our unsustainable economies. This is one of a series of models exploring the dynamics of sustainable economics – PSoup, ModEco, EiLab, OamLab, MppLab, TpLab, CmLab.
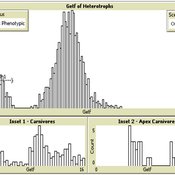
03 MppLab V1.09 – Maximum Power Principle Laboratory
Garvin Boyle | Published Saturday, April 15, 2017Using webs of replicas of Atwood’s Machine, we explore implications of the Maximum Power Principle. This is one of a series of models exploring the dynamics of sustainable economics – PSoup, ModEco, EiLab, OamLab, MppLab, TpLab, CmLab.
A spatial model of resource-consumer dynamics
Arend Ligtenberg Guus Ten Broeke George Ak Van Voorn Jaap Molenaar | Published Wednesday, January 11, 2017 | Last modified Thursday, September 17, 2020The model simulates agents in a spatial environment competing for a common resource that grows on patches. The resource is converted to energy, which is needed for performing actions and for surviving.
Effective population size and cultural evolution
Luke Premo | Published Tuesday, May 17, 2016This model illustrates how the effective population size and the rate of change in mean skill level of a cultural trait are affected by the presence of natural selection and/or the cultural transmission mechanism by which it is passed.
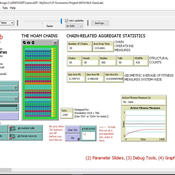
02 OamLab V1.10 - Open Atwood Machine Laboratory
Garvin Boyle | Published Saturday, January 31, 2015 | Last modified Thursday, April 13, 2017Using chains of replicas of Atwood’s Machine, this model explores implications of the Maximum Power Principle. It is one of a series of models exploring the dynamics of sustainable economics – PSoup, ModEco, EiLab, OamLab, MppLab, TpLab, EiLab.
Displaying 10 of 12 results natural selection clear search