Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 13 results clustering clear search
Peer reviewed The effect of homophily on co-offending outcomes
Ruslan Klymentiev Christophe Vandeviver Luis E. C. Rocha | Published Friday, September 26, 2025This Agent-Based Model is designed to simulate how similarity-based partner selection (homophily) shapes the formation of co-offending networks and the diffusion of skills within those networks. Its purpose is to isolate and test the effects of offenders’ preference for similar partners on network structure and information flow, under controlled conditions.
In the model, offenders are represented as agents with an individual attribute and a set of skills. At each time step, agents attempt to select partners based on similarity preference. When two agents mutually select each other, they commit a co-offense, forming a tie and exchanging a skill. The model tracks the evolution of network properties (e.g., density, clustering, and tie strength) as well as the spread of skills over time.
This simple and theoretical model does not aim to produce precise empirical predictions but rather to generate insights and test hypotheses about the trade-off between partnership stability and information diffusion. It provides a flexible framework for exploring how changes in partner selection preferences may lead to differences in criminal network dynamics. Although the model was developed to simulate offenders’ interactions, in principle, it could be applied to other social processes involving social learning and skills exchange.
…
Peer reviewed Virus Transmission with Super-spreaders
J M Applegate | Published Saturday, September 11, 2021A curious aspect of the Covid-19 pandemic is the clustering of outbreaks. Evidence suggests that 80\% of people who contract the virus are infected by only 19% of infected individuals, and that the majority of infected individuals faile to infect another person. Thus, the dispersion of a contagion, $k$, may be of more use in understanding the spread of Covid-19 than the reproduction number, R0.
The Virus Transmission with Super-spreaders model, written in NetLogo, is an adaptation of the canonical Virus Transmission on a Network model and allows the exploration of various mitigation protocols such as testing and quarantines with both homogenous transmission and heterogenous transmission.
The model consists of a population of individuals arranged in a network, where both population and network degree are tunable. At the start of the simulation, a subset of the population is initially infected. As the model runs, infected individuals will infect neighboring susceptible individuals according to either homogenous or heterogenous transmission, where heterogenous transmission models super-spreaders. In this case, k is described as the percentage of super-spreaders in the population and the differing transmission rates for super-spreaders and non super-spreaders. Infected individuals either recover, at which point they become resistant to infection, or die. Testing regimes cause discovered infected individuals to quarantine for a period of time.

Introducing two extensions of Schelling's segregation model
Andreas Flache Carlos A. de Matos Fernandes | Published Monday, January 25, 2021Schelling famously proposed an extremely simple but highly illustrative social mechanism to understand how strong ethnic segregation could arise in a world where individuals do not necessarily want it. Schelling’s simple computational model is the starting point for our extensions in which we build upon Wilensky’s original NetLogo implementation of this model. Our two NetLogo models can be best studied while reading our chapter “Agent-based Computational Models” (Flache and de Matos Fernandes, 2021). In the chapter, we propose 10 best practices to elucidate how agent-based models are a unique method for providing and analyzing formally precise, and empirically plausible mechanistic explanations of puzzling social phenomena, such as segregation, in the social world. Our chapter addresses in particular analytical sociologists who are new to ABMs.
In the first model (SegregationExtended), we build on Wilensky’s implementation of Schelling’s model which is available in NetLogo library (Wilensky, 1997). We considerably extend this model, allowing in particular to include larger neighborhoods and a population with four groups roughly resembling the ethnic composition of a contemporary large U.S. city. Further features added concern the possibility to include random noise, and the addition of a number of new outcome measures tuned to highlight macro-level implications of the segregation dynamics for different groups in the agent society.
In SegregationDiscreteChoice, we further modify the model incorporating in particular three new features: 1) heterogeneous preferences roughly based on empirical research categorizing agents into low, medium, and highly tolerant within each of the ethnic subgroups of the population, 2) we drop global thresholds (%-similar-wanted) and introduce instead a continuous individual-level single-peaked preference function for agents’ ideal neighborhood composition, and 3) we use a discrete choice model according to which agents probabilistically decide whether to move to a vacant spot or stay in the current spot by comparing the attractiveness of both locations based on the individual preference functions.
…
Peer reviewed Gregarious Behavior, Human Colonization and Social Differentiation Agent-Based Model
Gert Jan Hofstede Mark R Kramer Sebastian Fajardo Andrés Bernal Martijn de Vries | Published Thursday, August 20, 2020 | Last modified Thursday, October 29, 2020Studies of colonization processes in past human societies often use a standard population model in which population is represented as a single quantity. Real populations in these processes, however, are structured with internal classes or stages, and classes are sometimes created based on social differentiation. In this present work, information about the colonization of old Providence Island was used to create an agent-based model of the colonization process in a heterogeneous environment for a population with social differentiation. Agents were socially divided into two classes and modeled with dissimilar spatial clustering preferences. The model and simulations assessed the importance of gregarious behavior for colonization processes conducted in heterogeneous environments by socially-differentiated populations. Results suggest that in these conditions, the colonization process starts with an agent cluster in the largest and most suitable area. The spatial distribution of agents maintained a tendency toward randomness as simulation time increased, even when gregariousness values increased. The most conspicuous effects in agent clustering were produced by the initial conditions and behavioral adaptations that increased the agent capacity to access more resources and the likelihood of gregariousness. The approach presented here could be used to analyze past human colonization events or support long-term conceptual design of future human colonization processes with small social formations into unfamiliar and uninhabited environments.
Exploring the Effects of Link Recommendations on Social Networks
Andrew Crooks Ciara Sibley | Published Thursday, March 19, 2020The purpose of this model is explore how “friend-of-friend” link recommendations, which are commonly used on social networking sites, impact online social network structure. Specifically, this model generates online social networks, by connecting individuals based upon varying proportions of a) connections from the real world and b) link recommendations. Links formed by recommendation mimic mutual connection, or friend-of-friend algorithms. Generated networks can then be analyzed, by the included scripts, to assess the influence that different proportions of link recommendations have on network properties, specifically: clustering, modularity, path length, eccentricity, diameter, and degree distribution.
Peer reviewed The Effect of Spatial Clustering on Stone Raw Material Procurement
Marco Janssen Simen Oestmo Curtis W Marean | Published Friday, April 21, 2017This model allows for the investigation of the effect spatial clustering of raw material sources has on the outcome of the neutral model of stone raw material procurement by Brantingham (2003).
From Cyber Space Opinion Leaders and the Spread of Anti-Vaccine Extremism to Physical Space Disease Outbreaks
Xiaoyi Yuan | Published Wednesday, March 08, 2017 | Last modified Friday, March 31, 2017This model simulates the spread of anti-vaccine sentiments in cyber and physical space and how it creates emergence of clusters of anti-vacciners, which eventually lead to higher probablity of disease outbreaks.
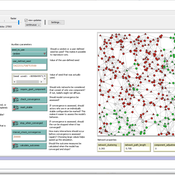
Peer reviewed A Model of Global Diversity and Local Consensus in Status Beliefs
André Grow Andreas Flache Rafael Wittek | Published Wednesday, March 01, 2017 | Last modified Wednesday, October 25, 2017This model makes it possible to explore how network clustering and resistance to changing existing status beliefs might affect the spontaneous emergence and diffusion of such beliefs as described by status construction theory.
The AgriculTural LandscApe Simulator (ATLAS)
Hugo Thierry Claude Monteil Aude Vialatte Jean-Philippe Choisis Benoit Gaudou Hazel Parry | Published Monday, January 30, 2017 | Last modified Wednesday, May 10, 2017The spatially-explicit AgriculTuralLandscApe Simulator (ATLAS) simulates realistic spatial-temporal crop availability at the landscape scale through crop rotations and crop phenology.
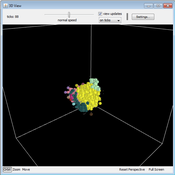
A Simulation of Entrepreneurial Spawning
Mark Bagley | Published Wednesday, June 08, 2016 | Last modified Friday, June 30, 2017Industrial clustering patterns are the result of an entrepreneurial process where spinoffs inherit the ideas and attributes of their parent firms. This computational model maps these patterns using abstract methodologies.
Displaying 10 of 13 results clustering clear search