Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1195 results for "Aad Kessler" clear search
Exploring homeowners' insulation activity
Georg Holtz Emile Chappin Jonas Friege | Published Monday, June 01, 2015 | Last modified Monday, April 08, 2019We built an agent-based model to foster the understanding of homeowners’ insulation activity.

A Model of Making
Bruce Edmonds | Published Friday, January 29, 2016 | Last modified Wednesday, December 07, 2016This models provides the infrastructure to model the activity of making. Individuals use resources they find in their environment plus those they buy, to design, construct and deconstruct items. It represents plans and complex objects explicitly.
SBH trust model
Di Wang | Published Tuesday, December 14, 2010 | Last modified Saturday, April 27, 2013This is a computational model to articulate the theory and test some assumption and axioms for the trust model and its relationship to SBH.
Peer reviewed Torsten Hägerstrand’s Spatial Innovation Diffusion Model
Sean Bergin | Published Friday, September 14, 2012 | Last modified Saturday, April 27, 2013This model is a replication of Torsten Hägerstrand’s 1965 model–one of the earliest known calibrated and validated simulations with implicit “agent based” methodology.
DiDIY Factory
Ruth Meyer | Published Tuesday, February 20, 2018The DiDIY-Factory model is a model of an abstract factory. Its purpose is to investigate the impact Digital Do-It-Yourself (DiDIY) could have on the domain of work and organisation.
DiDIY can be defined as the set of all manufacturing activities (and mindsets) that are made possible by digital technologies. The availability and ease of use of digital technologies together with easily accessible shared knowledge may allow anyone to carry out activities that were previously only performed by experts and professionals. In the context of work and organisations, the DiDIY effect shakes organisational roles by such disintermediation of experts. It allows workers to overcome the traditionally strict organisational hierarchies by having direct access to relevant information, e.g. the status of machines via real-time information systems implemented in the factory.
A simulation model of this general scenario needs to represent a more or less abstract manufacturing firm with supervisors, workers, machines and tasks to be performed. Experiments with such a model can then be run to investigate the organisational structure –- changing from a strict hierarchy to a self-organised, seemingly anarchic organisation.
Peer reviewed Minding Norms in an Epidemic Does Matter
Klaus G. Troitzsch | Published Saturday, February 27, 2021 | Last modified Monday, September 13, 2021This paper tries to shed some light on the mutual influence of citizen behaviour and the spread of a virus in an epidemic. While the spread of a virus from infectious to susceptible persons and the outbreak of an infection leading to more or less severe illness and, finally, to recovery and immunity or death has been modelled with different kinds of models in the past, the influence of certain behaviours to keep the epidemic low and to follow recommendations of others to apply these behaviours has rarely been modelled. The model introduced here uses a theory of the effect of norm invocations among persons to find out the effect of spreading norms interacts with the progress of an epidemic. Results show that norm invocations matter. The model replicates the histories of the COVID-19 epidemic in various region, including “second waves” (but only until the end of 2021 as afterwards the official statistics ceased to be reliable as many infected persons did not report their positive test results after countermeasures were relieved), and shows that the calculation of the reproduction numbers from current reported infections usually overestimates the “real” but in practice unobservable reproduction number.
EU language skills
Marco Civico | Published Sunday, July 07, 2024The objective of this agent-based model is to test different language education orientations and their consequences for the EU population in terms of linguistic disenfranchisement, that is, the inability of citizens to understand EU documents and parliamentary discussions should their native language(s) no longer be official. I will focus on the impact of linguistic distance and language learning. Ideally, this model would be a tool to help EU policy makers make informed decisions about language practices and education policies, taking into account their consequences in terms of diversity and linguistic disenfranchisement. The model can be used to force agents to make certain choices in terms of language skills acquisition. The user can then go on to compare different scenarios in which language skills are acquired according to different rationales. The idea is that, by forcing agents to adopt certain language learning strategies, the model user can simulate policies promoting the acquisition of language skills and get an idea of their impact. In this way the model allows not only to sketch various scenarios of the evolution of language skills among EU citizens, but also to estimate the level of disenfranchisement in each of these scenarios.
FlipFlop1-ProMEERB: A coupled social-ecological model with a promotional mechanism for emergence of environmentally responsible behavior
Liliana Perez Saeed Harati Roberto Molowny-Horas | Published Friday, December 17, 2021At the heart of a study of Social-Ecological Systems, this model is built by coupling together two independently developed models of social and ecological phenomena. The social component of the model is an abstract model of interactions of a governing agent and several user agents, where the governing agent aims to promote a particular behavior among the user agents. The ecological model is a spatial model of spread of the Mountain Pine Beetle in the forests of British Columbia, Canada. The coupled model allowed us to simulate various hypothetical management scenarios in a context of forest insect infestations. The social and ecological components of this model are developed in two different environments. In order to establish the connection between those components, this model is equipped with a ‘FlipFlop’ - a structure of storage directories and communication protocols which allows each of the models to process its inputs, send an output message to the other, and/or wait for an input message from the other, when necessary. To see the publications associated with the social and ecological components of this coupled model please see the References section.
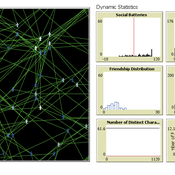
The Friendship Field
Eva Timmer Chrisja van de Kieft | Published Thursday, May 26, 2022 | Last modified Tuesday, August 30, 2022The Friendship Field model aims at modelling friendship formation based on three factors: Extraversion, Resemblance and Status, where social interaction is motivated by the Social Battery. Social Battery is one’s energy and motivation to engage in social contact. Since social contact is crucial for friendship formation, the model included Social Battery to affect social interactions. To our best knowledge, Social Battery is a yet unintroduced concept in research while it is a dynamic factor influencing the social interaction besides one’s characteristics. Extraverts’ Social Batteries charge while interacting and exhaust while being alone. Introverts’ Social Batteries charge while being alone and exhaust while interacting. The aim of the model is to illustrate the concept of Social Battery. Moreover, the Friendship Field shows patterns regarding Extraversion, Resemblance and Status including the mere-exposure effect and friendship by similarity. For the implementation of Status, Kemper’s status-power theory is used. The concept of Social Battery is also linked to Kemper’s theory on the organism as reference group. By running the model for a year (3 interactions moments per day), the friendship dynamics over time can be studied.
We presented the model at the Social Simulation Conference 2022.
BENCHv.2 model
Leila Niamir | Published Sunday, April 28, 2019The BENCH agent-based model is designed and developed to study shifts in residential energy use and corresponding emissions driven by behavioral changes among heterogeneous individuals.
Displaying 10 of 1195 results for "Aad Kessler" clear search